

By GUPPI
Foreword
In this post, we have gathered our experts’ views on new developments in AI. However, AI is a broad field and we do not pretend to have a complete understanding of the whole landscape. Our view is necessarily biased by our activities as an AI service provider and our Belgian market presence. Bearing this in mind, we examine different trends that we have spotted in AI across industries, research, tooling and much more.
The goal of this article is to get an overview of the landscape and not deep dive into each of the topics (although some are pretty exciting). If you too get excited, and want more, don't worry, we'll definitely deep dive into some of these cool topics over the course of the year.
First, we cover the core part of any AI use case: data. Then we will give an overview of the evolution in algorithms and techniques used to process the data. We touch upon the governance and infrastructure needed to leverage the full potential of AI and make it core to a data driven business. Finally, we briefly discuss ethical and societal impact of AI. Each section is independent so the reader can skip any part and go directly to what they're most interested in.
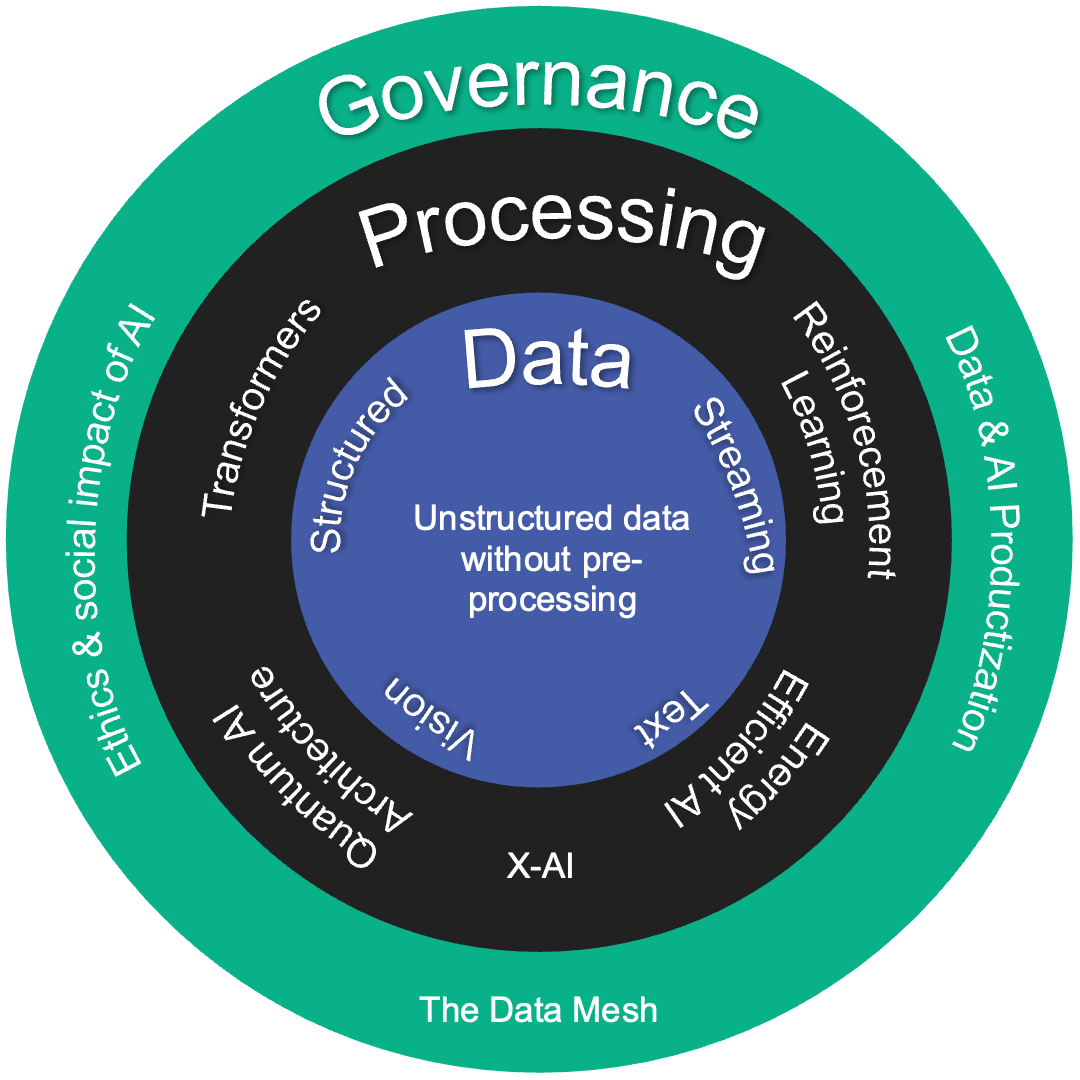
Evolution of data availability and structure
While structured data has been the main paradigm around which data-driven, and consequently AI-powered applications were built, we see a shift in industry where increasingly, companies are adopting AI-powered applications that can directly provide value from unstructured data.
Whereas before unstructured data such as images or text needed significant pre-processing before their use in AI-powered applications, many adopters of AI solutions will no longer need to deal with such upfront investments due to the increasing flexibility of AI. That is in part due to incredible advances in AI research, increasingly mature and flexible data processing solutions, and broader services offerings catering to specific industries requiring less domain-specific adaptations before value creation.
Beyond unstructured data, we see that advances in hardware are also impacting the method in which data is being collected, with an increasing shift from batch-based processing to streaming, also requiring the integration of time as an additional dimension. With the emergence of ever-cheaper and more effective sensors, new use cases are enabled at an increasing pace and allow AI to empower more sensor-heavy industries such as Smart Cities, Industry 4.0, manufacturing and logistics industry. Time series data infrastructure and accompanying AI algorithms are never hotter, open source libraries propose ways to lighten and compress AI models, cloud providers have dedicated IOT services and streaming engines are awaiting their time in the spotlight. This will for sure see the emergence of new cases like Digital Twins of factories & cities. AI on edge is starting to boom.
Trends in AI algorithms
If so many use cases are possible, it is thanks to steadily increasing research in AI. We have been closely following up the trends in research and attended the massively prestigious and influential NeurIPS conference in December 2021. Based on guidance by our experts and our attendance to these conferences, we’ve compiled a list of trends that we expect will be highly influential in the upcoming years.
The Rise of Transformers
One thing is clear, Transformers are here to stay. Transformers were already the powerhouse of contemporary NLP applications, but are now increasingly being applied in other data types or modalities, such as images, videos and audio.
The most appealing feature of Transformers is not that their accuracy is at a similar level (or even better) than the de facto standard in computer vision, namely convolutional neural networks (CNNs), but rather their potential multi-modal and multi-task functionalities that outperform any previous approaches. Transformers lend themselves exceptionally well to bridging the gap between multiple modalities, allowing practitioners to solve challenges that were previously impossible or required a significant amount of R&D for a singular application.
For example, we used DALL-E, a model created by OpenAI, that generates an image based on a caption written by its user to portray the following:

However, at this time transformers require significantly more computational resources for the same performance on prototypical tasks. We see a lot of investment in this area of research and we believe. Transformers will continue to explode in size throughout 2022, and we will be closely monitoring this evolution.
Reinforcement Learning Boom
Significantly more attention is being given to the implications of Reinforcement Learning (RL) in society. RL is very different from traditional machine learning in that the latter builds a representation of the world, whereas RL agents are trained to, and have the potential to alter the world in a dynamic fashion. RL is applicable to a lot of use cases like recommender engines, next best action framework and automation. What we don’t know yet is whether RL will replace the more traditional control approaches, or whether they’ll be applied to different use cases, or even combined.
Explainability, interpretability, accountability
Following the attention by regulators and the increasing impact of AI on the general public, researchers & industry practitioners are increasingly focusing on eXplainable AI (XAI). In many ways, XAI is about making AI applications more human-centric, meaning increased interactivity, transparency or human-like representation of AI output.
Consequently, human-in-the-loop XAI solutions that integrate human feedback are gaining traction, especially in combination with RL that allows dynamic adaptation to specific user and task contexts. In terms of AI transparency and decision-making representation, industry and academia alike are increasingly leveraging graph-based data and model representations. Finally, existing XAI methods are being re-examined and improved, for example through enabling uncertainty quantification of existing feature importance metrics such as LIME & Shapley, exposing the (oftentimes questionable) reliability of these dominant XAI approaches.
This increased attention has led to an explosion of new open-source initiatives and startups that provide XAI solutions, which leads to a dilemma for industry practitioners in their choice of XAI methodology and tooling. Dataroots will be providing recommendations and insights into these trends in the upcoming months.
(Energy) efficient AI
With AI being everywhere and models becoming complexer, a lot of compute power is necessary to train models and models also consume resources at prediction time. With the increase of AI usage, It is expected to become an ecological problem sooner rather than later. A new area of research is exploring how to construct more eco-friendly models. Work is mainly focused on building different models architectures, sometimes inspired by nature and our brain.
Research section finale
To conclude the section on research, we would like to briefly mention quantum computing. Even if it is still mainly used in research context, it has interesting implications and could be used to create different ML architectures. It’s definitely not coming to the industry soon but very interesting to follow its evolution.
There are a lot more exciting developments that we did not mention in this post and we’ll make sure to dedicate one (or more) post(s) to specifically deep dive into interesting trends in research.
Leveraging AI in a mature manner - (ML, Dev & Data)-Ops trends in applying product management approach to AI
Having top notch AI techniques is great. How do we now leverage the full potential of these algorithms?
For quite some time, there was a gap between the development of models and their productionalisation (this is actually one of the main reasons for the creation of dataroots).
In practice, existing tools and frameworks can still be improved, like being able to scale to dozens of models (especially for monitoring and automatic retraining), being more suited to enterprise setup (multi environments, workspaces), having a faster learning curve, and sometimes being more stable. We have already seen a lot of improvements in this area and we will continue to follow up closely the maturation process of the MLOps stack.
With the MLops stack easing productionalization of AI and the access to on demand compute resources, models are more and more trained online. A model is usually first trained on historical data and then deployed to make predictions. While our society evolves very fast, models need to be optimized in real time, to learn new behavior and stay relevant. We see online training and real time predictions/recommendations increase in the future.
We’ve not yet discussed the foundation making all of the above possible: infrastructure and data pipelines.
Infrastructure & data pipelines
Evolution of data, from 1700 to now
The word data was first used in the mid 17th century, it is the plural of the Latin word datum which means the things given. We’ll have to wait until the 40’s to get the modern definition of data: transmissible and storable computer information. In the 80’s, data was stored in warehouses and since 2010, it is also possible to tap it into lakes. Since then, data platforms have evolved a lot and data lakes and warehouses are now converging. The race between Databricks and Snowflake is the embodiment of this convergence.
Recent innovations in data warehousing are driving the industry towards a technology stack called the “modern data architecture”. The core component of this stack is a single system that provides compute and data storage for your data platform and that supports SQL as a first-class citizen. Typically you will see cloud data warehouses such as Snowflake, Databricks, and BigQuery taking up this role.
An ecosystem of tools has been built around these warehouses to easily support the different functionalities that should be a part of a data platform: Fivetran for data ingestion, Airflow for orchestration, Amundsen for data cataloging, great_expectations for data quality, Looker for BI and analytics, DBT for SQL development, and a lot more.
Because these tools can assume that there is a single warehouse supporting all their storage- and compute-needs they can simplify things significantly: they work well with SQL, are more straightforward operationally (as they can let the DWH do the heavy lifting), are easy to set up, and you can modularly add and replace different tools!
This is good news for the fans of SQL. We have to give it to IBM, SQL remains perennially fashionable. Of course SQL had some periods in the shadow but it’s back in the spotlight, and hotter than ever. With tools like DBT and Big Query, it has never been easier to transform data. Nowadays it is even possible to deploy models in your SQL queries, for batch processing. We definitely expect more improvement in making complex data pipelines easier and better.
Finally, the problem of modelling data for databases is still not solved, data vault and kimball methods are not yet dead! Data Vault is now getting pretty old, but you see it being applied more often recently, especially for the first layer of data. The Kimball star schema is a bit more controversial. Some seem to be able to be fine without it, others do come back to it. Still the question remains, what are the rules or techniques you can apply to keep the agility with such design?
Why so much evolution and so fast?
Managing rapidly changing Ops technologies
Data Mesh or Data Fabric is an interesting data management philosophy towards a composable company. It relies on decentralization and distribution of responsibilities towards actors that are closest to the data.
Data mesh is built around 4 principles :
- Domain driven: ensures that data is owned by those who truly understand it.
- Data Products: a data product is a node in the mesh that provides and consumes data from the mesh.
- Self Service Platforms: a common central system manages historical data in real time.
- Federated computational governance: is about establishing global standards.
Although Data Mesh is a noble quest, some questions related to its implementation remain open, like what will be the role of the product owner? Will business teams build "consumer oriented data"? Where are the machine learning engineers going to play?
Currently a standard stack has not emerged and combining the need for autonomy of the domain teams with the central system does not seem straightforward.
Furthermore, data governance and architecture still need to evolve to answer these valid questions and avoid creating a big (data) mess when responsibilities are decentralized.
Ethics & social impact of AI
Today, more and more resources are available for training and getting to understand AI. The open source community is growing, providing tutorial, code and support for questions. The universities and colleges train students to AI and data, offering master after master, to complement any type of study with an AI training. It is undoubtedly easier to train yourself in AI, especially if you are tech savvy.
Still, the impact that AI could have on our society is difficult to quantify and it is often hard for the EU citizen to grasp all the implications that AI can have on his live. AI is not always beneficial and its consequences can be frightening. One glance at how the media depicts the various scandals (Trump's campaign, facebook, Amazon, etc) is enough to understand that. Asia and the USA are not always the good kid, with their lack of regulations, questionable applications for AI arise: surveillance, discrimination and manipulation are some examples.
Luckily, the EU already started legislating, first with GDPR and in April 2021, they issued a proposal for regulations of AI. Even if it will not be legally binding soon, this has a lot of implications. The first focus of the regulation is about traceability, which is mainly covered by the MLOps stack. The second focus of the regulation is about responsible AI, which entails to build AI that can be trusted. In short, a responsible AI is a fair AI, and an AI that can be explained (in a human-like way). We expect that XAI (explainable AI) will be a part of any project soon and research to crack open the black boxes is going full speed.
Also worth mentioning is that solid (founded by the father of the WWW, it aims at getting true data ownership and improved privacy for all) is starting to have some traction and being embedded in local initiatives like Data village and Datanutsbedrijf.
Finally, discussions about ethics in AI are well underway: trying to figure out how to balance the threats and opportunities it creates. A well known example are generative models: developed with great intentions, they quickly were applied in some controversial cases like identity theft. Who knows, maybe one day, machine learning engineers will have to swear a Hippocratic Oath.
Closing remarks
I hope we were able to spark your interest and give you a condensed picture of the current AI landscape along with some of our expectations for it. We are very excited, this new year promises a lot of very cool AI developments and as always, we'll keep up to date with it. If we have picked your interest, be sure to stay tuned as we’ll most likely deep dive into the above topics and share about them in one of our channels!
We probably missed some topics, we all have our blind spots...
If there is any topic that you think we should have covered in this post, do not hesitate to reach out, we are always glad to broaden our horizons and get some fresh ideas.
subscribe to our RSS feed and our LinkedIn page.
We also did a short video on data trends, don't miss it.