

By Jinfu Chen, Baudouin Martelée
After one month of training at dataroots, some starters work on the internal project. The project of the Rootsacademy 2022 Q3 class consists of making an end-to-end solution for inferring information from traffic images. It goes without saying that this end-to-end solution requires infrastructure. In this post, we go through the infrastructure along with some tips and tricks to deploy AWS infrastructure using Terraform. Our aim is to explain things at a high level, such that you, the reader, can get a better understanding of how to achieve the same result, even without prior knowledge of AWS and Terraform.
Crash Course on AWS Services in Architecture
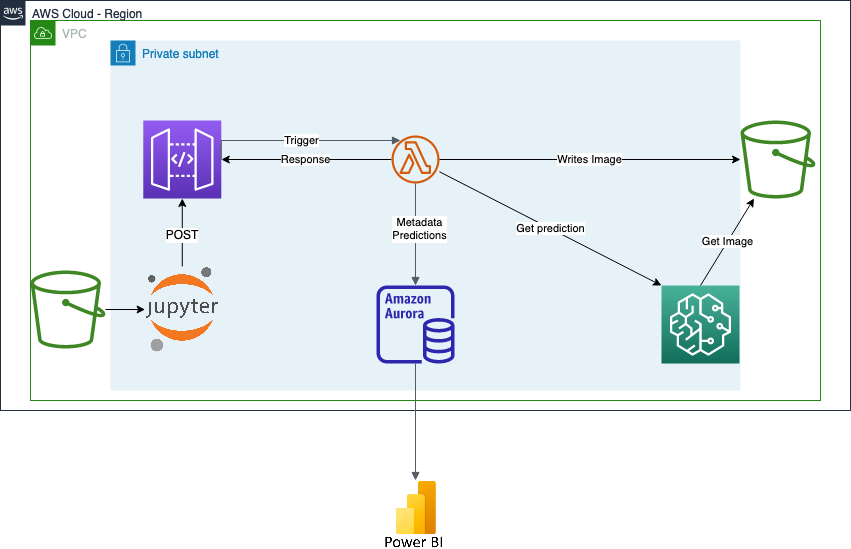
The above image displays final architecture. We need several services in AWS to realize the solution. In this section we give a short explanation of the used AWS services and how we used them in our architecture.
Region, VPC and Subnets
AWS services are deployed inside a region, the region can be seen as the physical location where services are running. AWS gives us the possibility to create private networks using VPCs. These VPCs can be split in several subnets, which allows us to control the resilience of deployed resources inside this VPC.
For our project we deployed everything inside a single subnet, but ideally you would maximize the resilience of your architecture.
Amazon S3
S3 is the object storage service within AWS and introduces the concept of buckets, on which objects are stored on.
We have two buckets running inside this architecture. The first bucket mimics a street camera that takes images of its surroundings, and the other one saves the annotated images that are made by the model.
Amazon Sagemaker Notebook and Model
Sagemaker is the service on AWS that contains all your machine learning needs. It has a lot of features ranging from training models to deploying endpoints to it.
We use Sagemaker Notebook for feeding images to the API Gateway in order to get an inference. The Sagemaker Model (deployed as image on Amazon ECR) annotates the images and gives it back to the Lambda.
Amazon API Gateway
API Gateway allows for creation and managing APIs. API Gateway is situated between applications using the API and services that implement the functionality of the API.
In our case, the API Gateway implements a REST API POST method. The Sagemaker Notebook calls the POST method with an image and triggers the Lambda, and after successful inference, the method returns a body containing the annotated image.
AWS Lambda
Lambda is a FaaS service within AWS for running code using a specific runtime.
Our Lambda code (deployed as image on Amazon ECR) connects several components with the following functionality:
- Inquiries Sagemaker for prediction
- Writing annotated image to the s3 bucket
- Writing metadata and annotated image to RDS
- Passing the annotated image back to API Gateway
Amazon RDS
The relation database of Amazon is Amazon RDS.
Our use for RDS is to save the metadata of the input images and their Sagemaker inferences.
Infrastructure as Code (IaC), What's in a Name?
Readers familiar with AWS Cloudformation might have heard of IaC. Terraform's functionality is somewhat similar to Cloudformation, but Cloudformation is only for AWS. Terraform is cloud agnostic and can be used to provision infrastructure on other major cloud platforms.
All of the above AWS services and their configurations can be specified in Terraform as code. Instead of creating all those components manually using the AWS Console, Terraform eases the process of deploying infrastructure on AWS by writing declarative code which represents resources and their configurations. It also links those resources to physical resources on AWS (state file), so it can detect changes in code and adjust the physical resource accordingly.
resource "aws_sagemaker_notebook_instance" "notebook_instance" {
name = "smart-mobility-notebook-instance-${terraform.workspace}"
role_arn = var.iam_role_arn
instance_type = "ml.t2.medium"
subnet_id = var.subnet_ids[0]
security_groups = var.security_group_ids
}When working with multiple people on a Terraform project, it is recommended to perform what is called a bootstrap. The bootstrap consists of two operations:
- Saving the state file in a s3 bucket, so that the state file can be accessed by your teammates.
- Saving a lock in a DynamoDB table. The lock ensures that only one person can modify the resources listed in the state file to prevent inconsistencies.
It is important to check if the partition key for the DynamoDB table is called LockID. This specific partition key is required for Terraform for recognizing the table.
Points of Attention
We finish this blog post with some points to pay attention to when setting up a similar infrastructure.
- API Gateway
For deploying the aws_api_gateway_integration resource, the uri of the Lambda needs to be in the following format:
"arn:aws:apigateway:${region}:lambda:path/2015-03-31/functions/${lambda_arn}/invocations/"- IAM Policies
Working with IAM policies is tricky. You need to be aware that some services might not have permission to do certain things. In AWS, the default rule is implicit deny. Resources are inaccessible for all kinds of actions performed on it unless explicitly stated by policies. If an action times out, there is a high probability that a policy needs to be set.
- Terraform workspaces
Terraform workspaces are useful when working with multiple environments (e.g. development and production). Each workspace has its own state file, making it possible to deploy the same resources for different environments.
- Github Actions and Github secrets
It is possible to create a CI/CD workflow using Github Actions that validates the changes in the Terraform code and apply those changes to AWS. Be aware that Github needs AWS credentials to do that, but do not place your credentials on the repository. Github secrets offers a secure way to save your AWS credentials such that it can be used in CI/CD workflows.
- AWS Console
It might be easier to create a first version of a resource using the AWS Console. Here you can get a high level overview and idea of the possible configuration parameters. If you can make a resource with your desired configuration, it should not be that difficult to translate it to Terraform code.
Conclusion
The cloud & infrastructure side of the Rootsacademy project was an interesting experience to have. It gave us a bit of more experience before starting working with clients. We would like to thank Virginie for organizing this project and our senior colleagues Richard and Emre for their time reviewing our PRs and giving us guidance.
This blog is mainly concerned about cloud & infrastructure, but if you would like to know more about the other elements of this project, we would highly recommend reading the blog posts of the data team and machine learning team.
You might also like

