

By Dorian Van den Heede
Can 4 Dataroots colleagues without professional music production experience write hit songs with AI? In this blogpost series the Beatroots team members uncover how they wrote their latest song, Song of the Machines, which they submitted for the 2022 AI Song Contest.
AI Song Contest
The AI Song Contest is an international music competition exploring the use of AI in the songwriting process. We have participated with Beatroots since its inception in 2020.
The premise for the contest is to write songs with, but not limited to, AI. The winner is voted in 2 phases. First, a panel of experts decides on a top 15 based on a diverse set of criteria (eg. overall song quality, use of AI tools, creativity, ...). Next, the voting very much resembles the procedure at the Eurovision song contest: 50% jury and 50% public. Unfortunately, we didn't make it to the final. You can listen to the finalists and cast your votes on the official website by the 30th of June.
For the past two years, we have had a particular focus to keep humanoid interference to a bare minimum. Our 2020 submission Violent Delights Have Violent Ends was generated entirely by a notebook script and our 2021 song Robotic Love was a remixed version of a cherry picked sample of a finetuned Jukebox model.
This year, our vision was to develop and fine-tune AI tools as "creative partners" in music-making. Again, we have used as much AI-generated output as possible, from lyrics to melodies to beats. Meanwhile, the sole responsibility of the humble humanoid was rearranging and producing the generated samples in a DAW (Digital Audio Workstation). Once our code is cleaned and peer reviewed, we will maintain it as an open source repository on Github. Stay tuned!
Workflow
At first, we have researched promising models in the open source community. It is truly astounding to see the progress and variety of AI music generation tools over the last two years. One day we could take the time to write up a survey on this, but for now it suffices to say that Google (with their Magenta project) and OpenAI (with Jukebox, MuseNet, GPT-3, ...) take the cake.
Next, we decided on which of these tools are the most promising and could realistically be mastered and optionally finetuned within the time constraints of the competition.
Once the deadline for submission came creeping in (read: 1 week before handing in) we put an abrupt halt to the development phase and entered the most fun part of the project: songwriting.
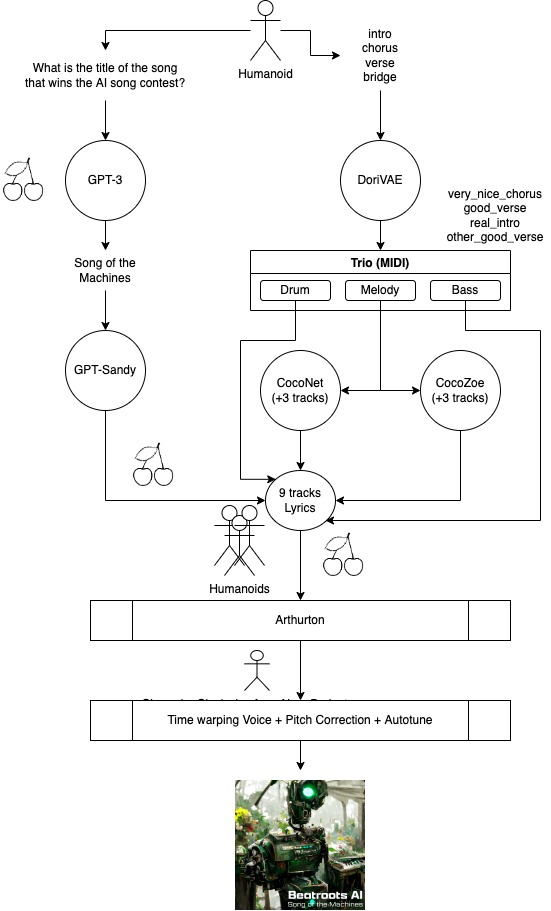
The final workflow to create our hit song is described in the flowchart above.
We didn’t know what to call our song, which is why we asked GPT-3 to give us cool names instead. The question we asked our dear Android friend was ‘Generate multiple creative titles for a song which would win the AI song contest’. GPT-3 gave us quite a lot of candidate titles ('Beyond the Binary' comes to mind), but we liked ‘Song of the Machines’ the best.
Subsequently, we combined inputs and outputs from our designated tools:
- Generating musical sections with DoriVAE as a starting point
- Generating harmonies on DoriVAE sampled melodies with CocoNet and CocoZoë
- Generating pop lyrics and chords with GPT-Sandy
- Enriching our outputs with the free Magenta plugin for Ableton
In the remainder of this article, we zoom in on (1). (2), (3) and (4) are subjects for upcoming posts!
MusicVAE: A Variational Auto Encoder (VAE) for music
With MusicVAE, an open source model published by Magenta, one can:
- randomly sample music note sequences
- interpolate between sequences ('eg. get a mixture of two melodies')
- manipulate existing sequences with attribute vectors ('eg. make beats less complex')
The core idea to achieve these feats is to train a Neural Network architecture to compress music (encoder) and rebuild (decoder) the original input with the additional constraint that the representations in the the compressed space (also called latent space) should be similar if the music is similar as well (and different if the music is different). This is what we call a Variational Auto Encoder (VAE).
If you want to learn more about the subject, Magenta has written an excellent blog post about this.
One of the models Magenta has pre-trained is for 16-bar music with three tracks: melody, bass and drums. Since this generates the most tracks in one go it's the one we have chosen to interact with.
Below you can listen to trio sample generated for this blogpost with MusicVAE:
Although remarkable in its capability to generate short musical sequences the entire sample lacks musical coherence across its full length. A famous music design principle popularised by Youtube star Adam Neely is that 'Repetition legitimises'. This generated sample feels lawless to me.
Ironic due to its apparent simplicity, repetition is one of the fundamental challenges for current music generation machine learning algorithms, especially for long term structures. The model does not know when to repeat or only slightly adapt an earlier motif. This is why the outputs from state of the art models sound more like a 'fluid hallucinations' instead of actual 'songs'.
Most radio hit songs also have a repetitive and predictable structure, for example 'verse-chorus-verse-chorus-bridge-chorus' is a well known success formula handled by countless songwriters and producers. Each of these section types have their own characteristics and style traits, for example the best melody should be in the chorus, the verse tells the story, the bridge connects verse to chorus, ... MusicVAE is indifferent to these subtleties (although one could argue to use attribute vectors).
Currently, there is no publicly available dataset that aligns musical sections to theirs scores. Luckily, we were able to reuse such a dataset on 200 Eurovision songs which we received for the 2020 AI song contest. This is a small dataset, which poses additional challenges on allowed model complexity.
To deal with small datasets, generate more cohesive musical ideas and introduce the notion of sections into MusicVAE, we first developed MiniVAE in 2020. For Song of the Machines, we refined and rebranded MiniVAE to DoriVAE.
DoriVAE: Nested Latent Spaces

The main idea is to train smaller VAEs that are fed the encodings from MusicVAE as input, and yield their reconstructions as output. Each new VAE is specialised and trained to one specific music type, genre, artist, ... In our use case each VAE is specialised in musical sections and represents a 16-bar trio (melody, bass and drums). This is an idea inspired on MidiMe.
We opted to reduce the existing latent space (which has a dimension of 512) by encoding this into a nested, smaller latent space with a dimension of 16. This nested latent space is optimised to contain only the musical structures we request (eg. all samples in the mini latent space represent a catchy chorus).
To generate new samples, we simply need to sample from our nested space and then decode twice: first with our custom trained section decoder, finally with the pretrained MusicVAE decoder. In total, we trained 6 additional VAEs This is how we generated the melody for the chorus in Song of the Machines:
or the intro melody (which we slightly modified in the DAW):
Conclusion
Creating nested latent spaces with MusicVAE is an effective method to create specialised models to sample music the way you want. DoriVAE fed the team with 3 tracks (melody, bass and drum) and 16 bars (32 seconds at 120BPM) of inspiration per generated sample, which we then cherry picked and adjusted to our liking.
The journey didn't end here. Stay tuned for the upcoming blogposts by our team on how we enriched our trio samples with contemporary harmonisations, finetuned transformers to generate lyrics with a musical context and put it all together within a DAW.