

By Gauthier Feuilen
Who hasn't heard of data quality? If there is a topic that comes up again and again lately it seems to be data governance where data quality plays an important role (or maybe I am just terribly biased).
Let's look together at how one might tackle this increasingly important issue for companies that have been gathering data (in data lakes or other). Where, When, What and How should one measure when we talk about data quality?
Where?
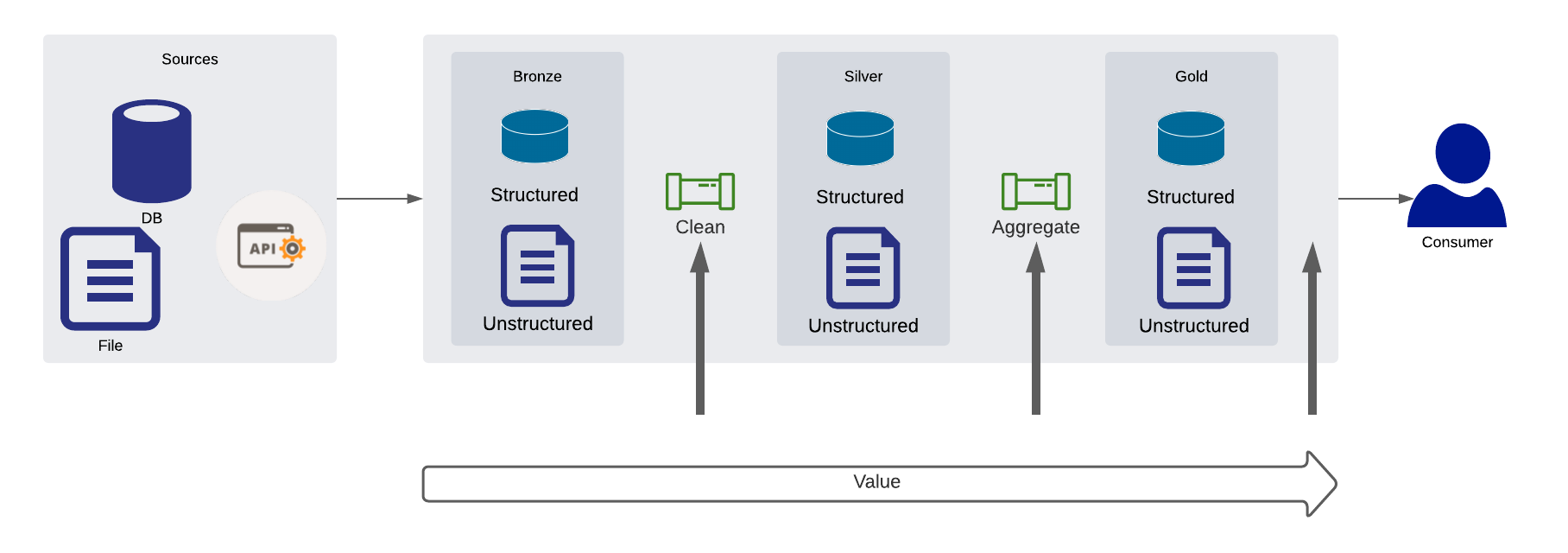
If you look at a typical pipeline, the picture below should look familiar. Ideally one should measure data quality at each and every step of the pipeline, before and after each transformation (like someone would write ALL tests before any implementation 😉 ).
Now, this is both hard to do and to maintain: as a rule of the thumb, start with what is closer to the consumer (from right to left) since this is where the most value is delivered. From there, work upstream as you will need to be able to investigate root causes of your issue.
When?
There is no definite answer to this:
Ideally again, one would measure quality as soon as the data is produced. This is good practice and can be "easily" added to your scheduling system (e.g. an extra step in Airflow) or as another consumer if you have a streaming data pipeline.
Often times, this is just not that easy and you can opt for a regularly scheduled job (CRON? ).
Do it often, as often as possible is the only advice to be given here.
What?
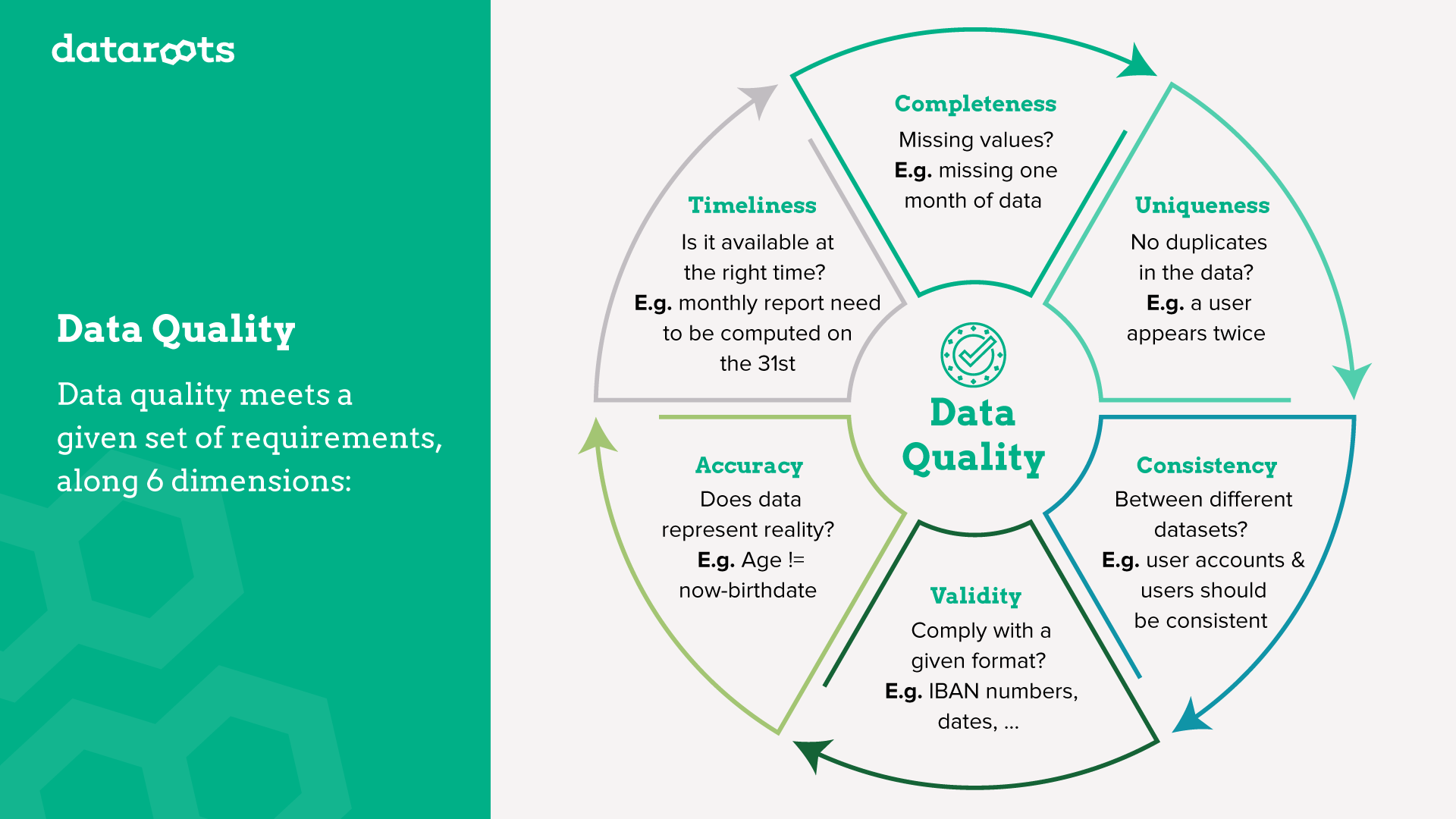
A picture is worth a thousand words, here are broadly accepted "dimensions" that one can measure on data. A small example to illustrate each is also shown.
How?
If you are still following, you probably have been waiting for this last part which is mainly about tooling, or is it?
There is a myriad of tools out there that can do the job, from local python scripts to fully fledged pricey solutions. I'll name drop two tools that we see gaining traction in our domain
great_expectations
A python tool, backend agnostic (can run on pandas, spark or SQL) that offers a bit more than just a library:
- Automated profiling & expectations (=DQ rule) suggestion
- Data Doc to view results
- And extensive glossary of expectations that one can use
- Integration with commonly used scheduling system (e.g. Airflow)
- A CLI, an everything-as-configuration mentality and extensible API.
This one is particularly useful if you have a python team and are just looking for a tool to fit the purpose. If you haven't seen it yet, make sure to check our tutorial built by Romain & Ilion
DBT
A SQL on steroids framework that allows to express DE tasks and has data checks as first class citizen. It also provides additional features such as:
- The ability to package & share functionalities
- Documentation of your data
- Lineage of your data
- JUST SQL with some templating — Simplicity FTW
DBT has been on our radar for quite some time, not just for data quality purposes (as the above's feature list let appear). Make sure to look at Sam Debruyn's intro presentation to get to know more.
And now what?
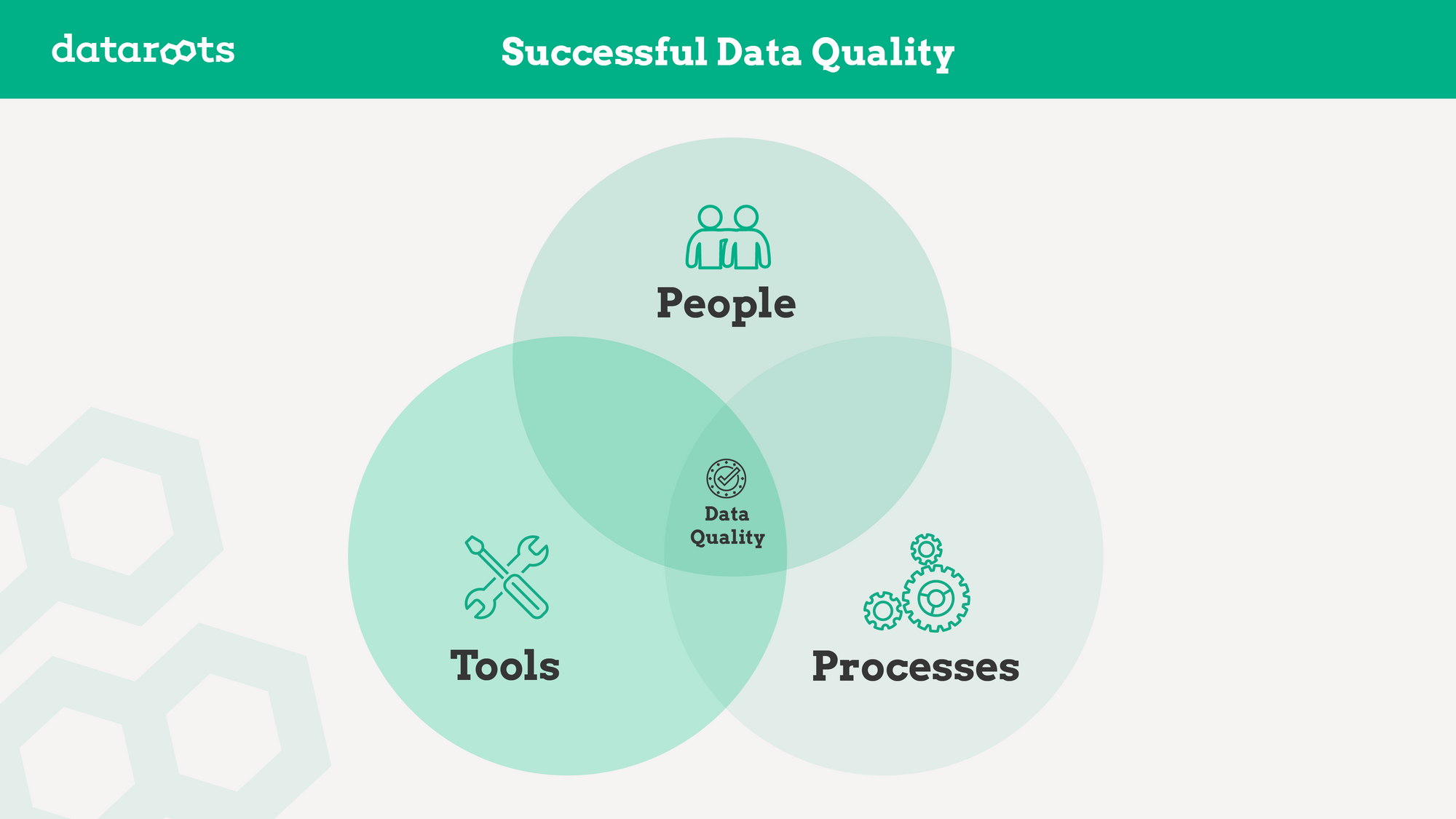
Data quality wouldn't be complete if we were missing on the human aspect of it. Like any technical solution, it doesn't work if nobody uses it and if there is no commonly shared guidelines and processes around it. Successful data quality is the combination of all this.
How to implement these processes and guidelines would (will?) be another topic.