

By Margaux Gérard, Omar Safwat
In our previous post, we explained our project of weather nowcasting in a general way. Now, we will deep dive into one of the most important steps in machine learning, which is model optimization. The need for optimizing model size and speed arises whenever the prediction model is required to run on an edge device, namely, smartphones, surveillance cameras, robots, etc. Therefore, the challenge is maintaining a small model that can run on inexpensive resources without sacrificing much accuracy.
To recap, our prediction model gets data from two sources, as shown in the following image.
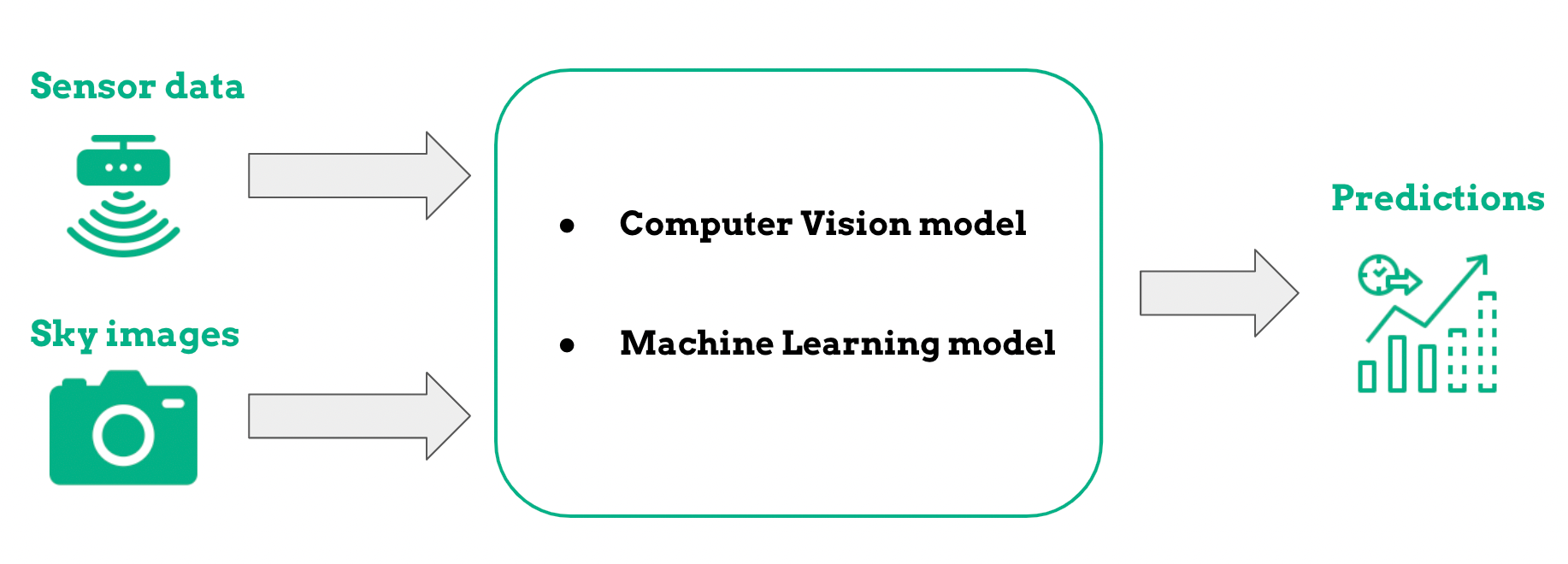
The edge device provides the model with weather information and images of the sky captured by a camera. Combining these two data sources, we are able to make a prediction of the weather conditions for the next four hours.
Image data preparation
Numerical data (e.g. temperature and pressure) can be processed and interpreted by any ML model. However, this is not the case for images. Images require an additional transformation step before being used by the model, and that is where the computer vision model comes into play. The vision model uses a type of artificial neural network called CNN, short for Convolutional Neural Network.
In a nutshell, the CNN extracts information from the images in an efficient manner. This creates what is called an image embedding, which is actually just a numerical vector holding the essential information and patterns extracted from the image.
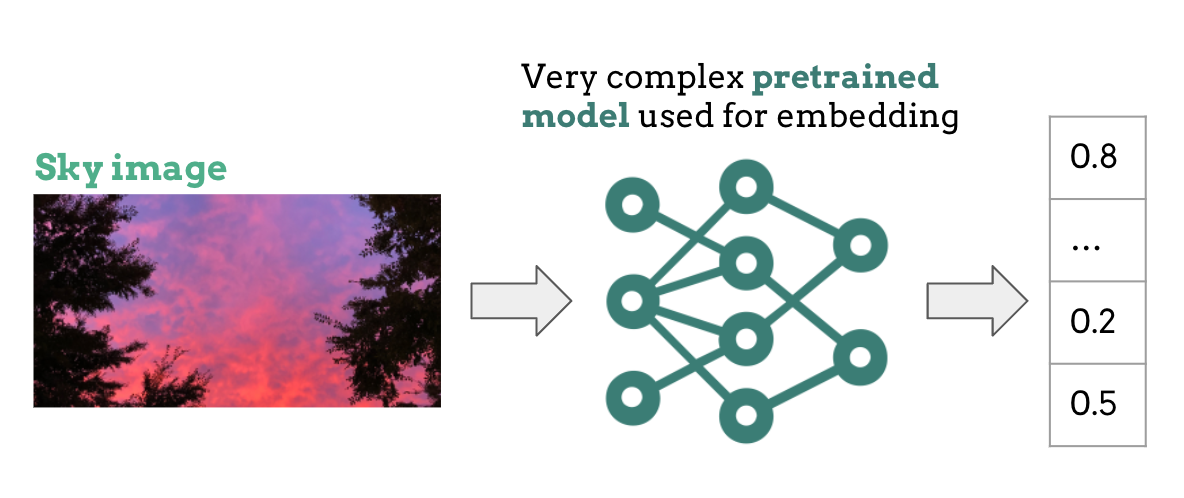
In order to build a powerful generalized model, we need a huge amount of time and data. Luckily, the AI community has pre-trained CNNs openly available with a wide range of size and accuracy. The tradeoff is always, however, choosing between a large and more accurate model or a smaller and less accurate model. Realizing the complexity of our task, we decided to use a pre-trained CNN to create the image embedding.
If you recall from our previous post, the entire model should make predictions in real-time on an edge device that has limited resources. This means that we need a small size CNN able to process the embedding in minimal time.
And the question is… How can this be achieved without reducing the CNN's complexity?
How to compress the pre-trained model? 🤏
This is where size reduction techniques come to the rescue. Techniques such as quantization and knowledge distillation are able to effectively reduce the model size without damaging its ability to extract patterns from image data.
Quantization
The quantization process reduces the precision of the weights and biases used by the neural network in order to consume less memory.
Generally the process uses 8-bit like integers to represent the parameters instead of the 32-bit floats. The obvious advantage of such a process is the reduction of model size (by a factor of 4), but also integer operations to perform relative to floats, not to mention less power consumption.

In practice there are two ways to do this:
- The first is post-training quantization where the neural network is entirely trained using floating-point computation and then gets quantized afterward, after which the parameters are entirely frozen and can no longer be updated.
- The second is training-aware quantization where the neural network uses the quantized version in the forward pass during training. The idea is that the quantization-related errors will accumulate in the total loss of the model during training, and the training optimizer will work to adjust parameters accordingly and reduce error overall. This method has the benefit of much lower loss than post-training quantization.
If you want to know more about model compression, check our article and tutorial (tensorflow).
Distillation
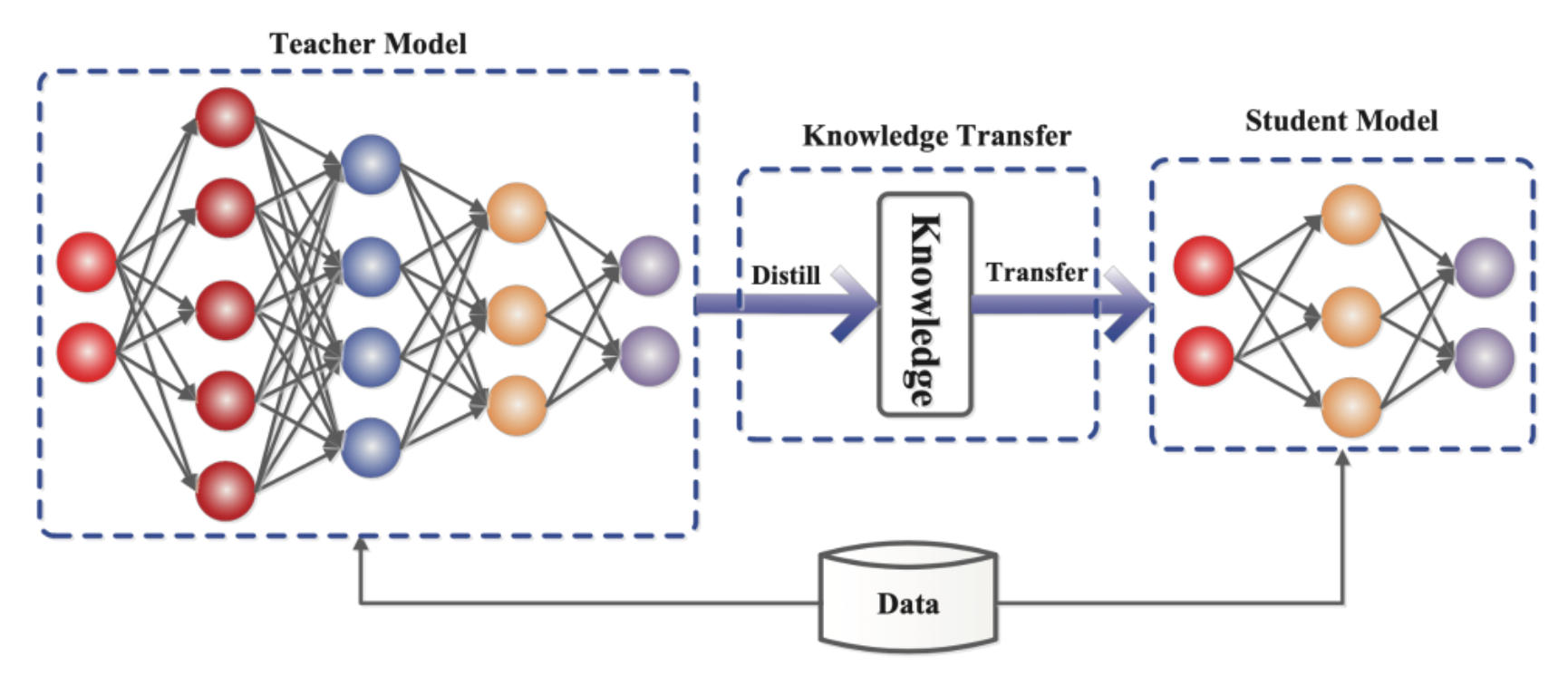
Knowledge distillation is the process of transferring the knowledge from a large well-trained model to a smaller one. The large model usually goes by the name of "Teacher model", and the smaller model is called "Student model".
The way we transfer the knowledge from the teacher to the student is by minimizing a special loss function, as shown in the following figure.
Knowledge Distillation can be achieved using different algorithms and variations of teacher and student models. With some variations, student models can learn effectively enough to have performance very close to that of the teacher, while maintaining a much smaller size.
Discussion of results
In this section, we evaluate the results from using the two model size reduction techniques discussed earlier.
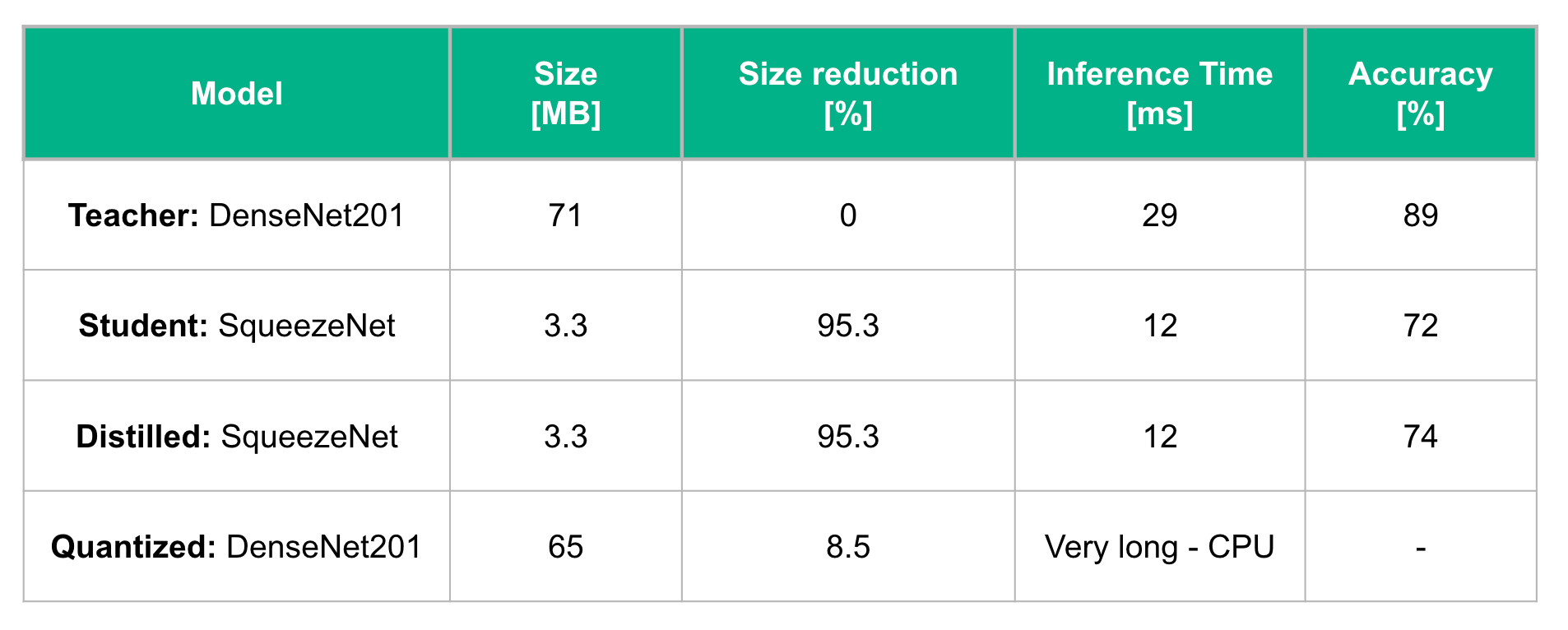
For the knowledge distillation method, we chose the DenseNet201 as a teacher model. This model is considered to be very accurate because it is pre-trained on thousands of images from ImageNet, a popular dataset of pictures created by Google. For the student model, we used the SqueezeNet pre-trained model whose size is 5% of the teacher model's. We then fine-tuned both models on Caltech 256, a dataset with 256 distinct image classes, as opposed to ImageNet which contains 1000 distinct image classes. This would make the knowledge distillation from the teacher to the student model much faster and easier.
After training the student model for 15 epochs, we were able to increase the accuracy of the pre-trained student model by 2%, slightly closing the gap between the teacher and the student models performance.
A recent survey shows similar results [1]. Indeed there are more variations to try for knowledge distillation, which would yield better results. For example, some student models learn from some teacher models better than others, not to mention the different knowledge distillation algorithms, which you can learn more about in [1].
For the quantization method, we applied the PyTorch post-training quantization function on the pre-trained DenseNet201 model. However, the size reduction observed was marginal and model inference time was even longer than before, as quantization on PyTorch is not yet supported on GPUs.
Conclusion and future work 🚀
In this blog post, we tackled a very critical topic in machine learning, which is model compression. In Deep Learning, deploying cumbersome models on devices with limited resources is always a challenge because of their high computational and storage requirements. In this post, we briefly discussed two recent model compression techniques that, although still under research, show very promising results. Quantization and knowledge distillation have demonstrated their ability to effectively reduce the size and runtime of large deep learning models without heavily sacrificing their accuracy.
In our project, we applied these two effective techniques with simple configurations, which showed promising results even though we haven't fully exploited the broad range of choices and variations under each.