

By Dimitri Pfeiffer
Over the past decade, data driven decision algorithms have become more and more performant and prevalent, but also complex. They are not only complex to develop or deploy in production, but even their operating mechanics are hard to understand. The so-called black box algorithms have taken over, with their awesome results and complete lack of transparency. And while this trend does not seem anywhere close to reversing[^1], great strides have been made in the field of explainability to address this particular issue so that never again can a black box feel like actual black magic.
Why should I care ?
Whether you are a technical expert or a business stakeholder, there are many different reasons for you to care about explainability in predictive models. Let's go over a few of them.
First of all, more transparency means more trust in the solution. Chances are, at some point you'll need to sell this solution, either to your boss or a customer, be it internal or external. And if you cannot trust something, how can you reasonably consider using it? It is also very likely that the people that need this solution have some idea of how it should work, i.e., on what it should based itself to make decisions and how it should react to different inputs.
Second, explainability enables accountability, by exposing the drivers responsible for the decisions being suggested. And once those drivers are identified, they can potentially be turned into actionable insights in order to increase value or reduce costs, on top of the value and cost reduction gained from the unexplained solution. Third, regulations are increasingly calling for more transparency and audit in machine learning. It has historically been the case in specific domains such as finance and healthcare, but now the trend is growing across all kind of industries, namely in Europe with the GDPR and its "right to explanation"[^2]
Last but not least, you do not want to let discrimination and bias creep into your company decision making processes. And the risk is very real since machine learning is at its core about reproducing past examples. Consider for example the automated resumé reviewer of Amazon that favored men[^3], or the discrimination built into the Facebook ad-serving algorithm[^4] which led them to a lawsuit from the federal US government[^5].
How do I get explanations?
Now that you should be convinced there is value in explainability, the next logical step would be to wonder what to do about it. Fortunately there are many tools and resources at our disposal to tackle this issue.[^6]
Let's dive right in and present a subset of the possibilities, split into two main categories: local and global explainability. There are two kinds of explanation you can seek:local, where one particular instance of prediction is in scope, providing an answer to one applicant asking "Why was my loan request rejected?"global, where the dynamics of the whole model are under the microscope, providing an answer to the business owner asking "What makes a loan request good or bad?"
Global explanations
Here we answer the question "what makes the model tick?", or in other words, what are the overall drivers in the decision making process?Accumulated Local Effects (ALE) Plots are on of the great visual tools to answer this question. The goal is to show how a feature affects the prediction on average. You can think of this as feature importance on steroids.
Let's see it in action! Imagine a bike rental business assessing a predictive model of the daily demand in bicycle, in order to better plan the offer.
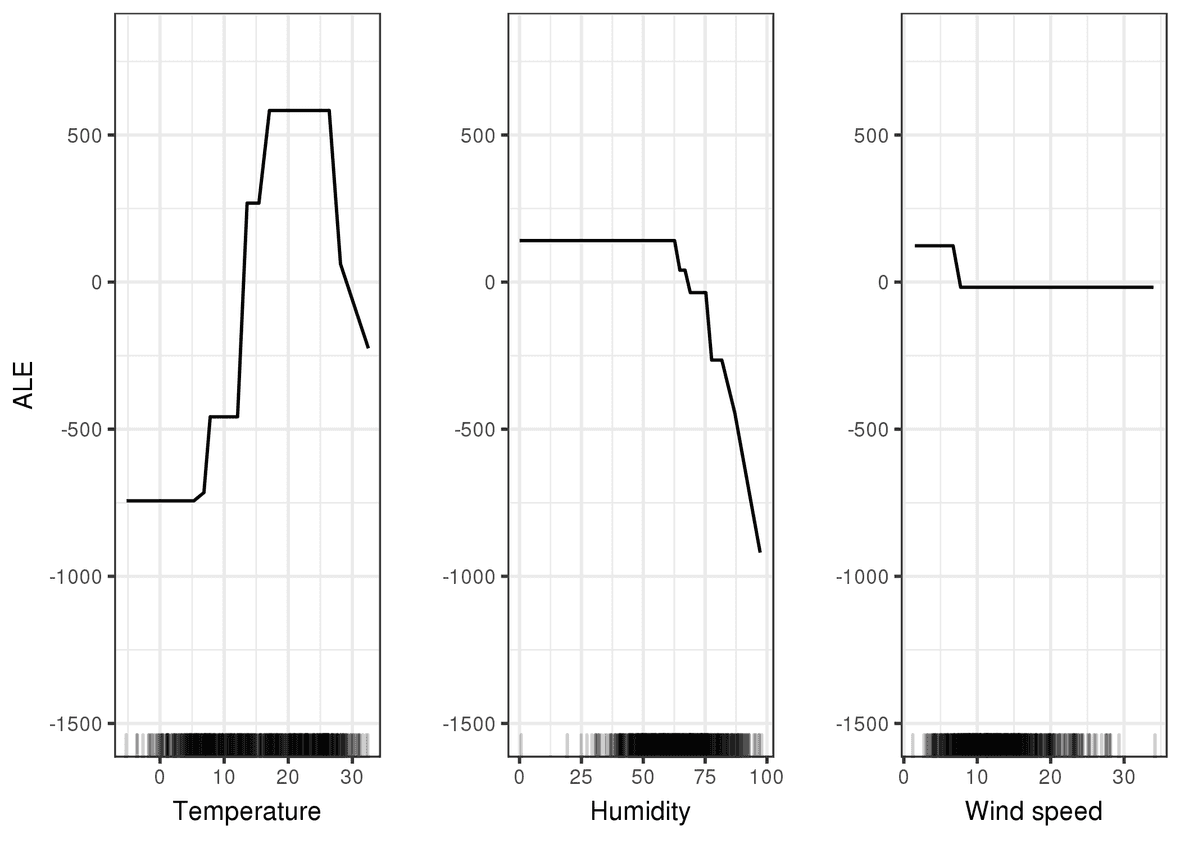
We see here that the model will on average predict more rentals when the temperature is in a sweet spot between 17°C and 25°C, whereas it will dramatically predict less rentals when the humidity is above 60%. On the other hand, the wind speed does not seem to have any effect.
This kind of figure is not very hard to interpret and it provides some degree of confidence that the model is both sound and not biased.
Local explanations
Here we answer the kind of questions like "why was my loan application rejected", or in other words, what are the specific reasons behind a single instance of prediction?Local surrogate techniques such as LIME[^7] are one of the answers to that question. The main idea is to create another model, very simple and interpretable, that mimics the complex model's behavior in a small region around the specific instance of prediction we are interested in. In essence, we build a local estimation fo the complex model and we get a shot at understanding what happened when the prediction was made.
Let's take a look at what we can expect from this! Still in the bike rental scenario, we wonder why the usage prediction is so high on day X and so low on day Y.
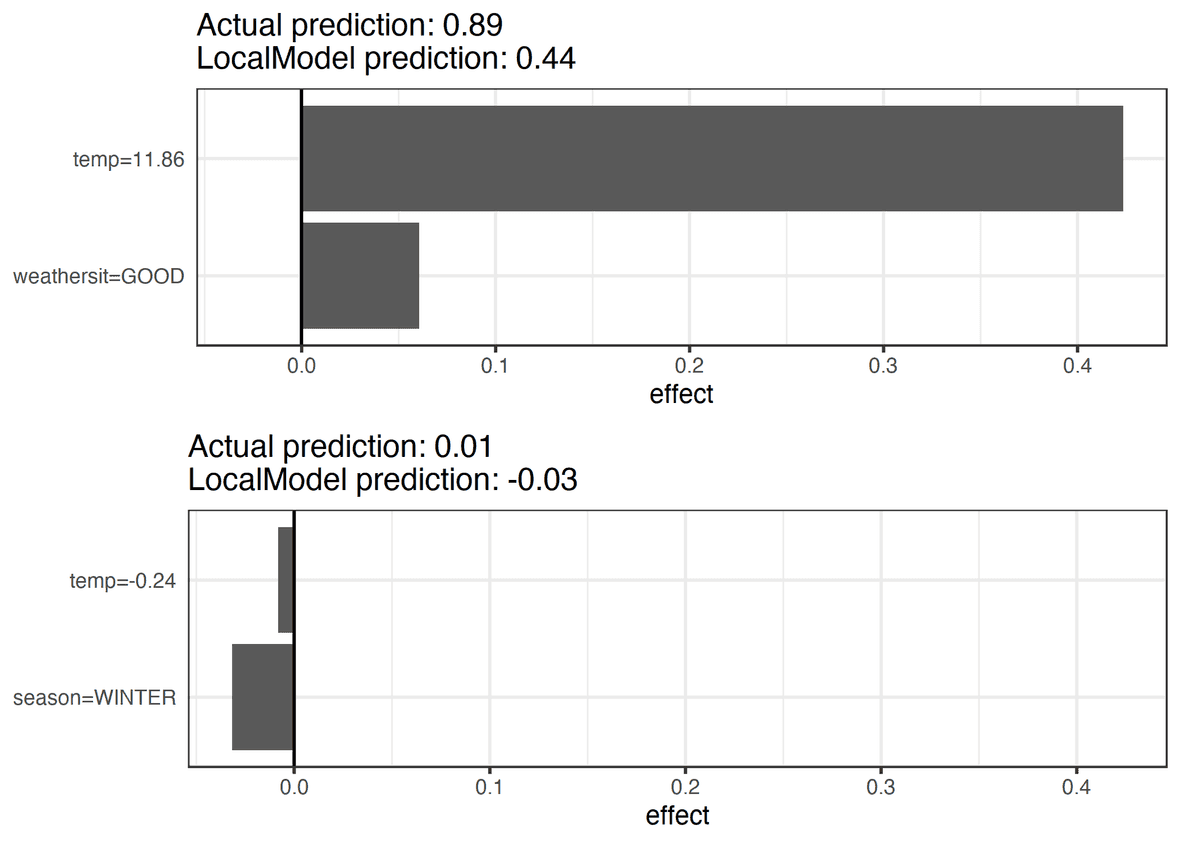
From the figure, we can answer the following: Predictions were high on day X because the temperature and the overall weather conditions were good, while the predictions for day Y were very poor mainly because it was freezing and we were in the dead of winter.
Next steps
The topic of machine learning explainability is vast and evolving rapidly, there is a lot of reading material out there we haven't even touched here in this humble blog post where we only scratched the surface.
The main take away from this post:
- As a technical expert, you should be able to convince anyone of the soundness and correctness of your product, but also be able to justify each of its decisions.
- As a business stakeholder, you should request proofs that the solution works as intended and is not repeating errors and biases from the past.
- Consider for example what Andrej Karpathy dubbed Software 2.0
- https://www.privacy-regulation.eu/en/r71.htm
- https://www.theguardian.com/technology/2018/oct/10/amazon-hiring-ai-gender-bias-recruiting-engine
- https://www.technologyreview.com/2019/04/05/1175/facebook-algorithm-discriminates-ai-bias/
- https://www.npr.org/2019/03/28/707614254/hud-slaps-facebook-with-housing-discrimination-charge
- See for example https://christophm.github.io/interpretable-ml-book/index.html
- https://github.com/marcotcr/lime
Images are from Molnar, Christoph. "Interpretable machine learning. A Guide for Making Black Box Models Explainable", 2019.