

By Dishani Sen
Data engineering is a crucial process involving data collection, storage, processing, and analysis. It plays a vital role in the data science lifecycle, enabling businesses to make informed decisions. In this blog post, we will discuss practical best practices for data engineering on Google Cloud Platforms. These practices will help you build scalable, reliable, and secure data engineering solutions. Additionally, we will cover individual services like BigQuery, DataFlow, Dataplex in detail in our upcoming blog series on GCP.
Google Cloud Platform (GCP) offers a wide range of services that can be used for data engineering. These services include:
- BigQuery: A fully managed, petabyte-scale analytics data warehouse
- Cloud Storage: A scalable, durable, and highly available object storage service
- Cloud Dataflow: A unified programming model for batch and streaming data processing
- Dataproc: A managed Hadoop and Spark service
- Cloud Data Fusion: A fully managed, cloud native, enterprise data integration service
and a plethora of others.
These services can be used to build a variety of data engineering solutions, such as:
- Data warehouses for storing and analysing large datasets
- Data pipelines for processing data in real time
- Machine learning models for making predictions
Key Components of Data Engineering on Google Cloud
The key components of data engineering on Google Cloud are:
- Data storage: Data storage is the process of storing data in a way that it can be accessed and processed later. GCP offers a variety of data storage services, including BigQuery, Cloud Storage, and Cloud SQL.
- Data processing: Data processing is the process of transforming data into a format that can be used for analysis or machine learning. GCP offers a variety of data processing services, including Cloud Dataflow, Dataproc, and Cloud Data Fusion.
- Data analysis: Data analysis is the process of extracting insights from data. GCP offers a variety of data analysis services, including BigQuery ML, Cloud Dataproc, and Cloud Data Fusion.
- Machine learning: Machine learning is the process of building models that can learn from data and make predictions. GCP offers a variety of machine learning services, including Cloud ML Engine, Cloud AutoML, and Cloud TPUs.
Services and Tools for Data Engineering on Google Cloud
In addition to the key components of data engineering, GCP also offers a variety of services and tools that can be used for data engineering purposes. These services and tools include:
- Cloud Dataproc: A managed Hadoop and Spark service that can be used to process large datasets.
- Cloud Dataflow: A unified programming model for batch and streaming data processing.
- Cloud Data Fusion: A fully managed, cloud native, enterprise data integration service.
- BigQuery ML: A service that provides machine learning capabilities on top of BigQuery.
- Cloud AutoML: A service that helps you build machine learning models without having to write any code.
- Cloud TPUs: Specialised hardware accelerators for machine learning.
Best Practices for Data Storage
The first step in any data engineering project is to choose the right data storage solution. The following factors should be considered when choosing a data storage solution:
- The type of data: Some data, such as structured data, is well-suited for relational databases. Other data, such as unstructured data, is better suited for object storage.
- The volume of data: The amount of data that needs to be stored will affect the choice of data storage solution.
- The performance requirements: The performance requirements of the data processing application will also affect the choice of data storage solution.
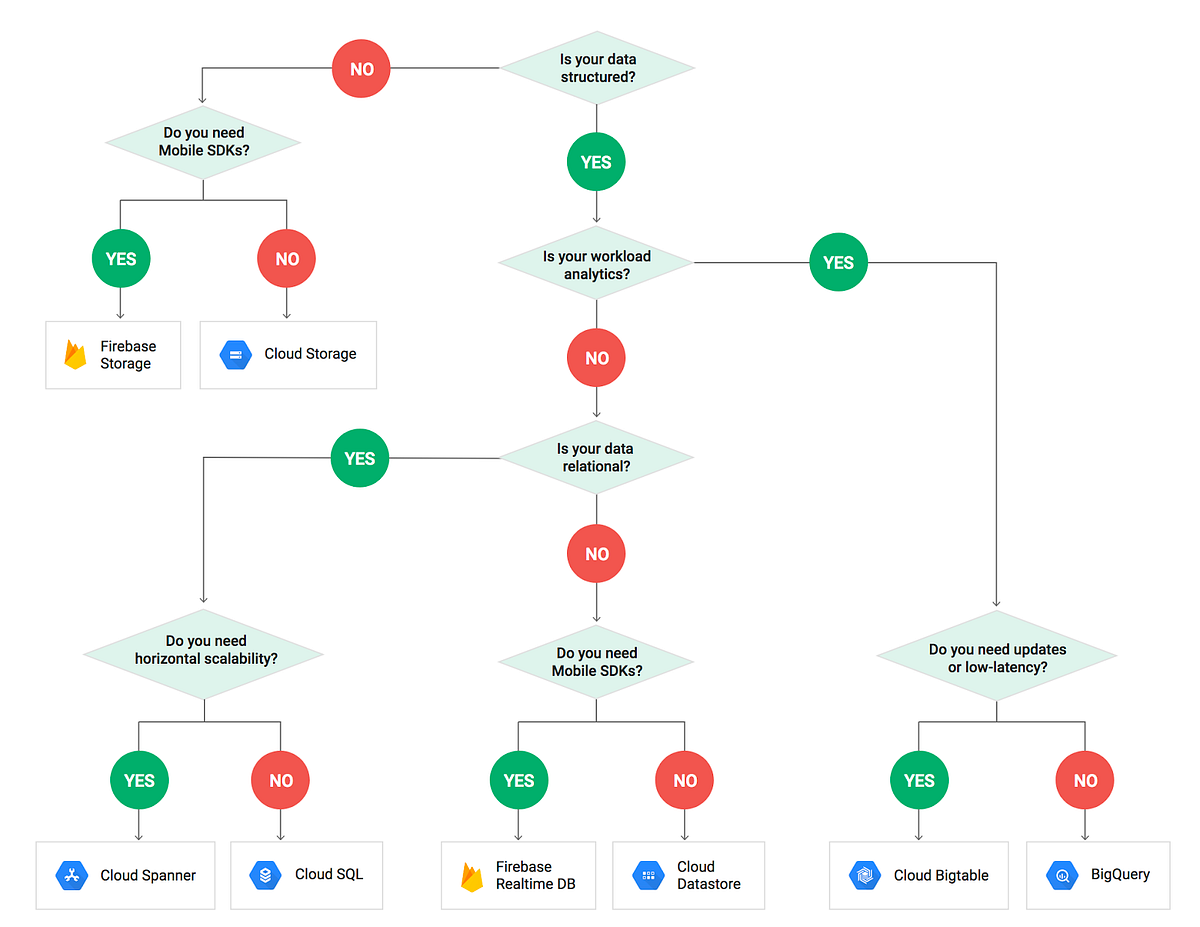
Best Practices for Data Processing
Once the data has been stored, it needs to be processed. The following factors should be considered when choosing a data processing solution:
- The type of data processing: Some data processing tasks, such as batch processing, can be performed on a batch processing engine. Other data processing tasks, such as streaming processing, can be performed on a streaming processing engine.
- The volume of data: The amount of data that needs to be processed will affect the choice of data processing solution.
- The performance requirements: The performance requirements of the data processing application will also affect the choice of data processing solution.
Best Practices for Data Security
Data security is a critical part of any data engineering project. The following factors should be considered when implementing data security measures:
- Encryption: Data should be encrypted at rest and in transit.
- Access control: Access to data should be restricted to authorised users.
- Auditing: Data access should be audited to track who has accessed the data and when.
By implementing these data security measures, you can help to protect your data from unauthorised access.
Best Practices for Machine Learning
Machine learning is a powerful tool that can be used to make predictions from data. The following factors should be considered when choosing a machine learning solution:
- The type of machine learning task: Some machine learning tasks, such as classification, can be performed using a supervised learning algorithm. Other machine learning tasks, such as clustering, can be performed using an unsupervised learning algorithm.
- The volume of data: The amount of data that is available will affect the choice of machine learning solution.
- The performance requirements: The performance requirements of the machine learning application will also affect the choice of machine learning solution.
Conclusion
Data engineering on Google Cloud Platforms offers powerful solutions for collecting, processing, and analysing data. By following these best practices, you can build efficient and secure data engineering solutions. Stay tuned for more blog posts in our GCP series. Hope you enjoyed this practical introduction to data engineering on GCP! These are just a few of the best practices for data engineering on Google Cloud.