

By Bart Smeets
Over the last months, I’ve read several posts showing how to use generative AI to generate comics. Sometimes the visuals, sometimes the story, sometimes a combo of both. It is often used as a starting point, and the comic evolves from there. Or it serves as a moodboard for the artist to quickly sketch up some ideas to work on manually as a next step. I’ve not yet seen (and this is probably simply my limited view of the world) generative AI being used to improve the aesthetics of an already existing comic.
This line of thought made me wonder how easy it would be to promote myself from amateur dad doodler to actual comic artist. Could generative AI give me a hand in this, and if so, would it be a helpful hand?
The start
Let’s start with doodling a mini webcomic. I guess purple elephants are always a safe choice. I’ll use Procreate for this.

This output clearly shows that an (artificial) helping hand would not be a bad thing. In the realm of visual generative AI, I’m personally a big fan of Midjourney. I enjoy the out-of-the-box aesthetics more than those of DALL-E 2 or Stable Diffusion. Inpainting is a notable lacking feature in Midjourney that will be relevant in this experiment (hypothesizing here). Inpainting is the ability to erase/touch up parts of the generated picture with a new prompt. Another point, more talking from experience than anything else, is that DALL-E 2 will also be a tad easier on prompt engineering when getting a good factual representation of what we want to see. Note that the content of the below post is being created when I’m typing up this post, so don’t expect any thoroughly researched output; this is output anyone can get with minimal input & time.
Let's get bedazzled
Yes, I like to say bedazzled.
Let’s try out this prompt:
A pink elephant looking at an egg with a hat on that is holding a sandwich with ones and zeros on it, comic style, 16 bit colors.
This is what Midjourney (v5) gives us:

This is what DALL-E 2 gives us:

This is what Stable Diffusion (v2.1) gives us:

So yeah… Esthetically definitely enjoy Midjourney in this first go. But all three approaches require more thinking on how to get an output more consistent with our original comic (and in line with this simple prompt).
<15 minutes later> I tried a ton of different prompts to see if we could get closer to a composition as is shown in the first panel of our webcomic, but alas, it seems difficult to convey this in a single prompt.
I’m going to try another approach. What if we create a scenery and then use inpainting to add what we want to see? I will use DALL-E 2 from now on as it has quite a nifty inpainting functionality.
a wide open meadow, marvel comics style

OK, cool cool, not bad. Now, let’s use DALL-E 2s inpainting functionality to add a pink elephant in the left corner.
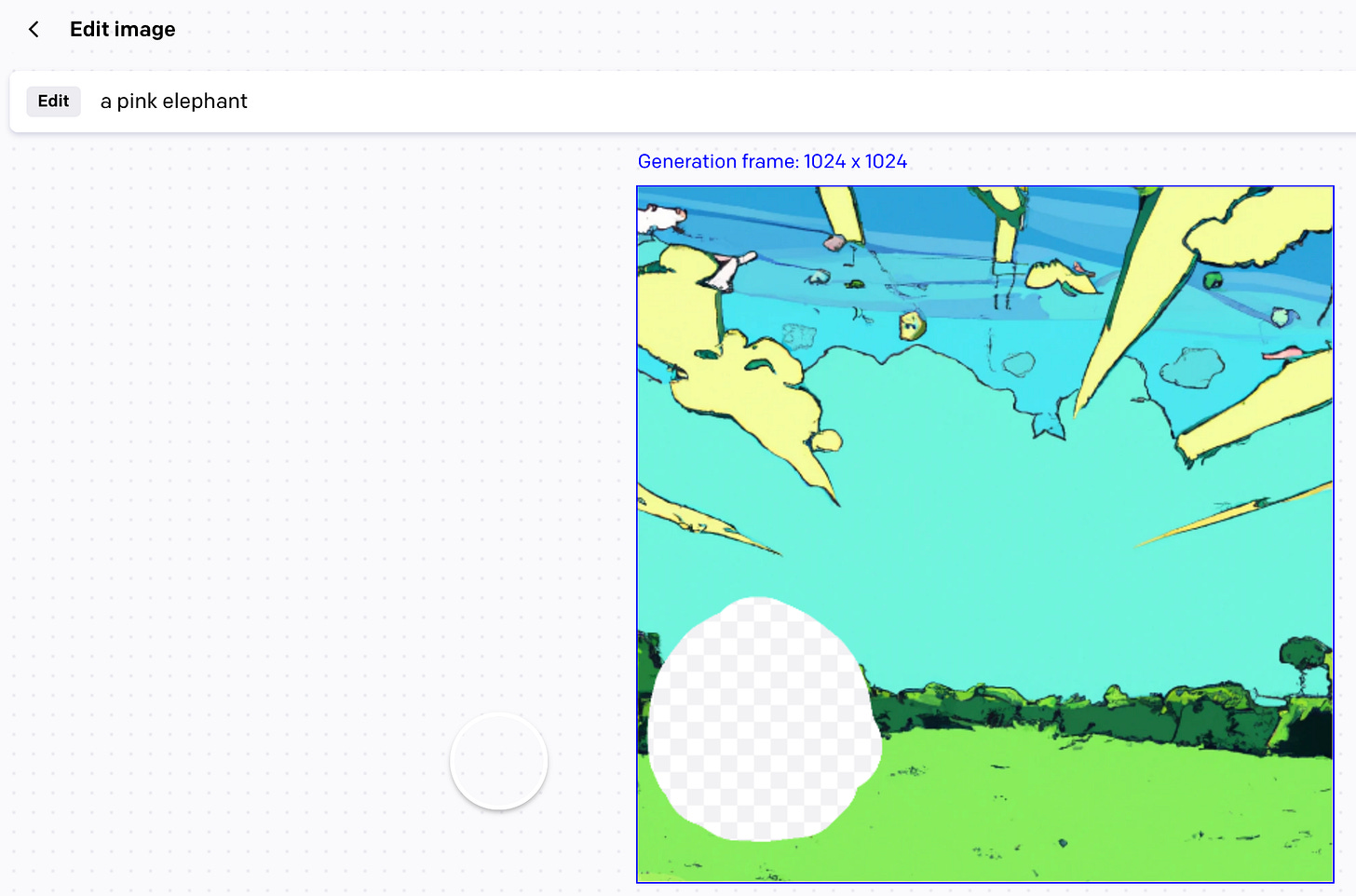
OK, we got a result.

One elephant down, an egg and a sandwich to go 🤞. Let’s first try to generate an egg with a cap on.
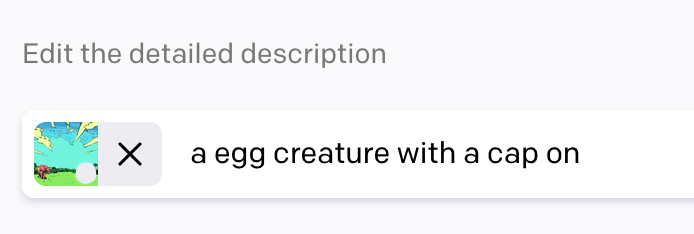

After a few variations, this seems to be the one that most match what we want, minus the cap. So, let’s inpaint again to get our poor lil’ bald egg fitted with a baseball cap.
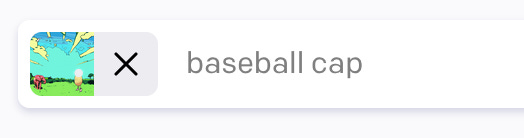

Hmmm… Good enough. Just a sandwich with some ones and zeros to go.


So I tried to re-inpainting and variations on the inpainting prompt. But getting our 1s and 0s on our slice of bread seems difficult. I’ll manually edit that into the image a bit later.
I’ll do some final inpainting on the facial expression of the egg that we can use for the final panel of the comic.


OK, that seems fine-ish. I’ll move all this over to Procreate, do some final editing, and add the speech balloons.

The Masterpiece
And then we end up with this original masterpiece.

Seems that all that is left to do now is to give up my job, become an AI-assisted comic artist, and profit.
Some afterthoughts
The outcome is OK. More visually impressive than the original. But it contains a ton of artefacts. It could be much cleaner. Having it much cleaner would require much touching up to be done by me, though. For now, I’ll keep it at manual doodling and use these generative services more for idea generation. Think “automated mood board” style. For that, I’m definitely putting my eggs in Midjourney’s basket. It will be interesting to see how they plan to add in- or outpainting functionality.
Artefacts seem like a small thing, but they’re really a PITA. Based on how you want to use your outcome, cleaning up artefacts can take up way more time than the whole creative process. Think if, for example, you need a vector-based output for an embroidery print; then artefacts quickly become the bane of your existence. And remember, these are artefacts/noise that would normally not be part of something you or I would doodle. Just have a look at our egg dude or the sky.
Another interesting topic we didn’t cover here is style consistency. Now we used the same scenery for each panel. Still, from the moment you start using different sceneries or different poses of your characters, it becomes important that there is consistency in style used and the characters created. In my experience, this is not easy and worth diving deeper into before committing. Midjourney has some internal utilities (e.g. seed setting, blending) to support this. I’ve also seen good results using CLIP Interrogator 2 to enrich/describe your prompt for the desired result in more detail. This topic of consistency would probably be worth another post. 🤔
In short, doodle away on paper, on screen or via AI! 🤖
You might also like
 dataroots
dataroots Creative Bloq
Creative Bloq