

By Sam Debruyn
Welcome to the second part of a 5-part series on an end-to-end use case for Microsoft Fabric. This post will focus on the data engineering part of the use case.
In this series, we will explore how to use Microsoft Fabric to ingest, transform, and analyze data using a real-world use case. The series focuses on data engineering and analytics engineering. We will be using OneLake, Notebooks, Lakehouse, SQL Endpoints, Data Pipelines, dbt, and Power BI.
All posts in this series
This post is part of a 5-part series on an end-to-end use case for Microsoft Fabric:
- Fabric end-to-end use case: overview & architecture
- Fabric end-to-end use case: Data Engineering part 1 - Spark and Pandas in Notebooks
- Fabric end-to-end use case: Data Engineering part 2 - Pipelines
- Fabric end-to-end use case: Analytics Engineering part 1 - dbt with the Lakehouse
- Fabric end-to-end use case: Analytics Engineering part 2 - Reports
Use case introduction: the European energy market
If you’re following this series, feel free to skip this section as it’s the same introduction every time. 🙃
Since Russia invaded Ukraine, energy prices across Europe have increased significantly. This has led to a surge of alternative and green energy sources, such as solar and wind. However, these sources are not always available, and the energy grid needs to be able to handle the load.
Therefore, most European energy markets are converging towards a model with dynamic energy prices. In a lot of European countries, you can already opt for a dynamic tariff where the price of electricity changes every hour. This brings challenges, but also lots of opportunities. By analyzing the prices, you can optimize your energy consumption and save money. The flexibility and options improve a lot with the installation of a home battery. With some contracts, you could even earn money by selling your energy back to the grid at peak times or when the price is negative.
In this use case, we will be ingesting Epex Spot (European Energy Exchange) day-ahead energy pricing data. Energy companies buy and sell energy on this exchange. The price of energy is announced one day in advance. The price can even become negative when there will be too much energy on the grid (e.g. it’s sunnier and windier than expected and some energy plants cannot easily scale down capacity).
Since it’s quite a lot of content with more than 1 hour of total reading time, I’ve split it up into 5 easily digestible parts.
We want to ingest this data and store it in OneLake. At one point, we could combine this data with weather forecasts to train a machine learning model to predict the energy price.
After ingestion, we will transform the data and model it for dashboarding. In the dashboard, we will have simple advice on how to optimize your energy consumption and save money by smartly using a home battery.
All data is publicly available, so you can follow along in your own Fabric Workspace.
Source data
The data we are using comes from the table marked below from the Epex Spot website. The data is - very unfortunately - not easily available through an API or a regular data format.
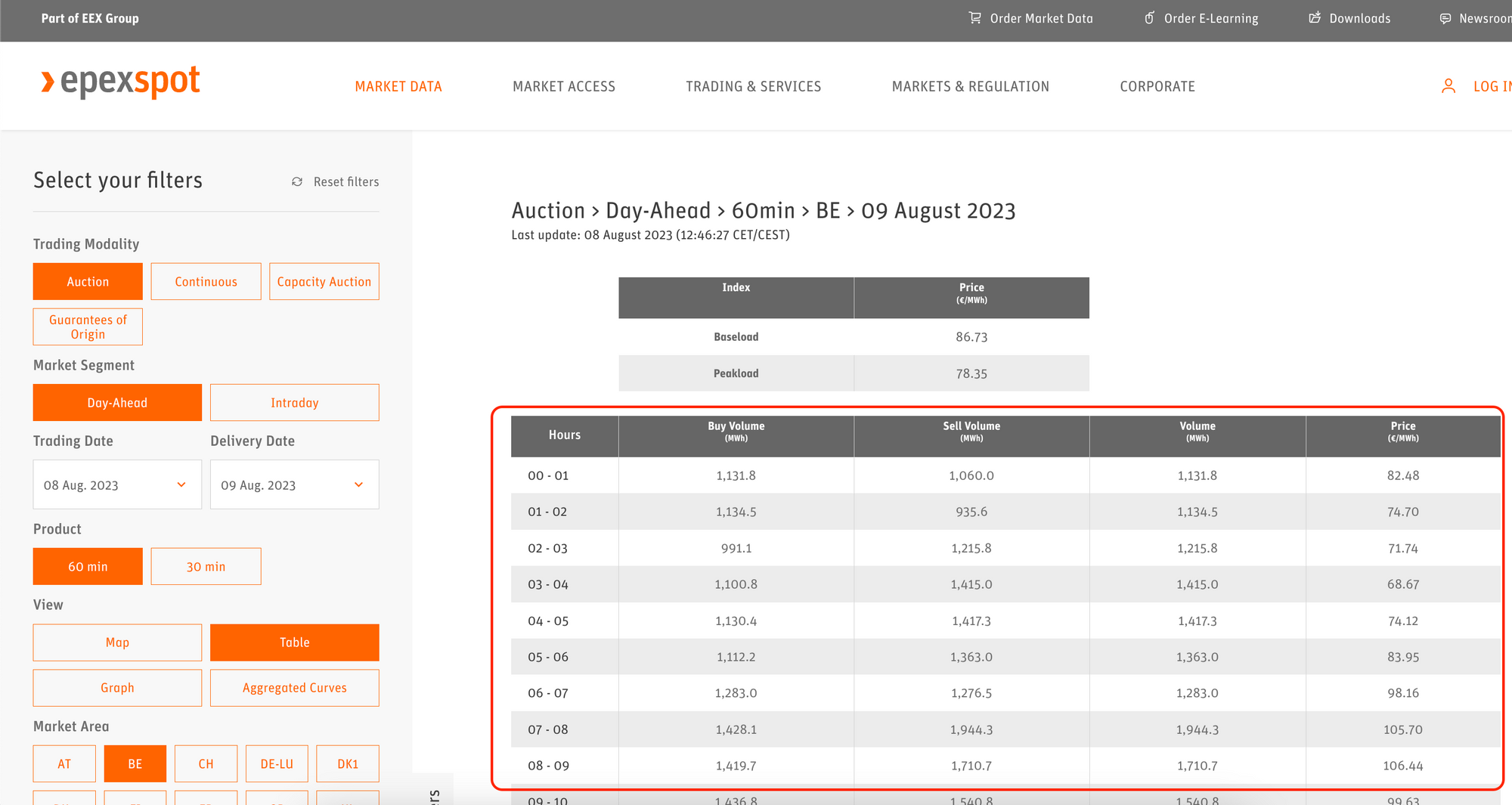
Instead, we have to scrape the data from the website. Luckily, I'm not the first person to do this. I found this GitHub repository where Steffen Zimmermann already went through the hassle of analyzing the website's HTML code and extracting the data we need from it. By looking at that source code and taking the bits and pieces we need from it, we can achieve the same result in a Notebook.
Installing beautifulsoup4
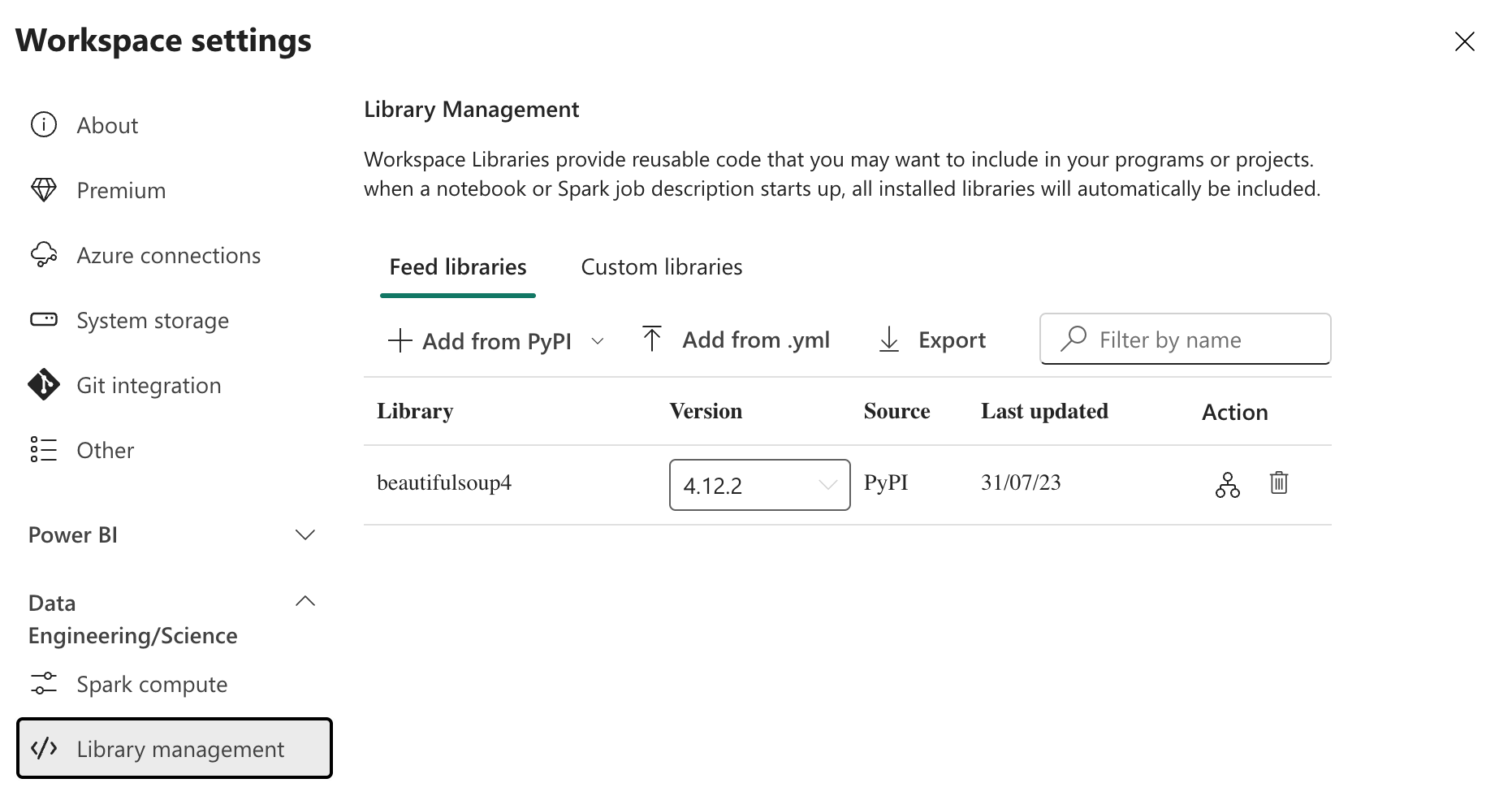
Before we can get started, we first need to install the beautifulsoup4 Python package in the Spark runtime environment of our Fabric Workspace. This can be done by going to your Workspace settings and then expanding the Data Engineering/Science section. There, you will find the </> Library management tab. Click on it and then on the + Add from PyPI button. In the text box that appears, enter beautifulsoup4, pick the latest version, and click on the Apply button. This will install the package in your Workspace. I suggest you take a coffee now since the installation process took a few minutes for me.
The Notebook
Now it's time to have some fun and start playing with the data. Create a new Notebook and follow Fabric's prompts to also create a new Lakehouse. Both operations take a few seconds and don't require any infrastructure to be provisioned.
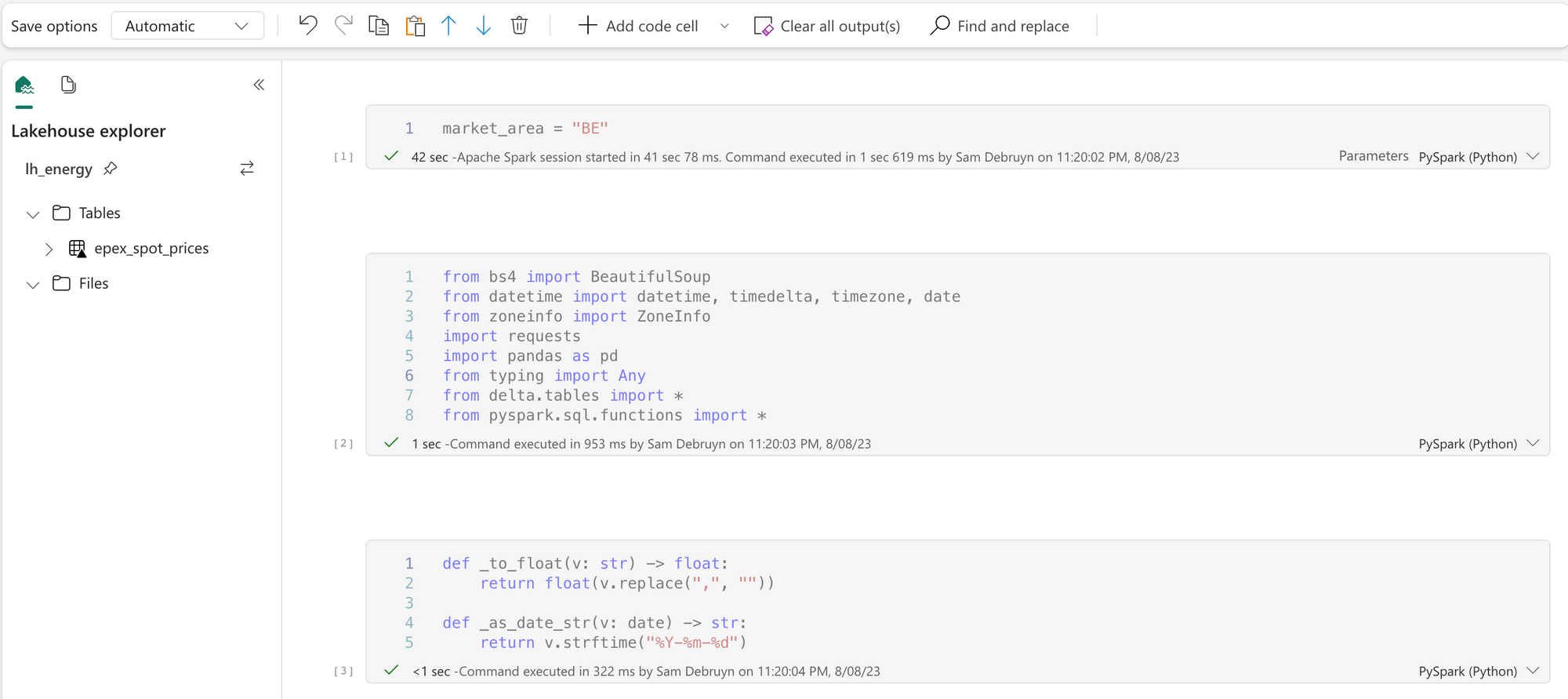
Unfortunately the Fabric feature to export Notebooks doesn't fully work yet, so I cannot share the Notebook itself at the time of writing. I will update this post with a link to a downloadable version you can import once this feature is available. In the meantime, the code below is the full Notebook. Let's go through it step by step.
market_area = "BE"
from datetime import date, datetime, timedelta, timezone
from typing import Any
import pandas as pd
import requests
from bs4 import BeautifulSoup
from delta.tables import *
from pyspark.sql.functions import *
def _to_float(v: str) -> float:
return float(v.replace(",", ""))
def _as_date_str(v: date) -> str:
return v.strftime("%Y-%m-%d")
def extract_invokes(data: dict[str, Any]) -> dict[str, Any]:
invokes = {}
for entry in data:
if entry["command"] == "invoke":
invokes[entry["selector"]] = entry
return invokes
def fetch_data(delivery_date: date, market_area: str) -> dict[str, Any]:
trading_date = delivery_date - timedelta(days=1)
params = {
"market_area": market_area,
"trading_date": _as_date_str(trading_date),
"delivery_date": _as_date_str(delivery_date),
"modality": "Auction",
"sub_modality": "DayAhead",
"product": "60",
"data_mode": "table",
"ajax_form": 1,
}
data = {
"form_id": "market_data_filters_form",
"_triggering_element_name": "submit_js",
}
r = requests.post("https://www.epexspot.com/en/market-data", params=params, data=data)
r.raise_for_status()
return r.json()
def extract_table_data(delivery_date: datetime, data: dict[str, Any], market_area: str) -> pd.DataFrame:
soup = BeautifulSoup(data["args"][0], features="html.parser")
try:
table = soup.find("table", class_="table-01 table-length-1")
body = table.tbody
rows = body.find_all_next("tr")
except AttributeError:
return [] # no data available
start_time = delivery_date.replace(hour=0, minute=0, second=0, microsecond=0)
# convert timezone to UTC (and adjust timestamp)
start_time = start_time.astimezone(timezone.utc)
records = []
for row in rows:
end_time = start_time + timedelta(hours=1)
buy_volume_col = row.td
sell_volume_col = buy_volume_col.find_next_sibling("td")
volume_col = sell_volume_col.find_next_sibling("td")
price_col = volume_col.find_next_sibling("td")
records.append(
(
market_area,
start_time,
end_time,
_to_float(buy_volume_col.string),
_to_float(sell_volume_col.string),
_to_float(volume_col.string),
_to_float(price_col.string),
)
)
start_time = end_time
return pd.DataFrame.from_records(records, columns=["market", "start_time", "end_time", "buy_volume", "sell_volume", "volume", "price"])
def fetch_day(delivery_date: datetime, market_area) -> pd.DataFrame:
data = fetch_data(delivery_date.date(), market_area)
invokes = extract_invokes(data)
# check if there is an invoke command with selector ".js-md-widget"
# because this contains the table with the results
table_data = invokes.get(".js-md-widget")
if table_data is None:
# no data for this day
return []
return extract_table_data(delivery_date, table_data, market_area)
current = DeltaTable.forName(spark, "epex_spot_prices")
current_df = current.toDF()
current_df = current_df.withColumn("date", to_date(col("start_time")))
current_market_count = current_df.filter((current_df.market == market_area) & (current_df.date == _as_date_str(datetime.now() + timedelta(days=1)))).count()
if current_market_count == 24:
mssparkutils.notebook.exit("Already ingested")
prices = fetch_day(datetime.now() + timedelta(days=1), market_area)
if len(prices) == 0:
mssparkutils.notebook.exit("No prices available yet")
spark_df = spark.createDataFrame(prices)
current.alias("current").merge(spark_df.alias("new"), "current.market = new.market AND current.start_time = new.start_time AND current.end_time = new.end_time").whenNotMatchedInsertAll().execute()
Walkthrough
Parameter cell
market_area = "BE"
The first cell is a parameter cell where we set the market we want to ingest. I would like to run this notebook for all markets where Epex Spot is active, so by parametrizing the market area, we can pass the market area as a parameter to the notebook when we run it.
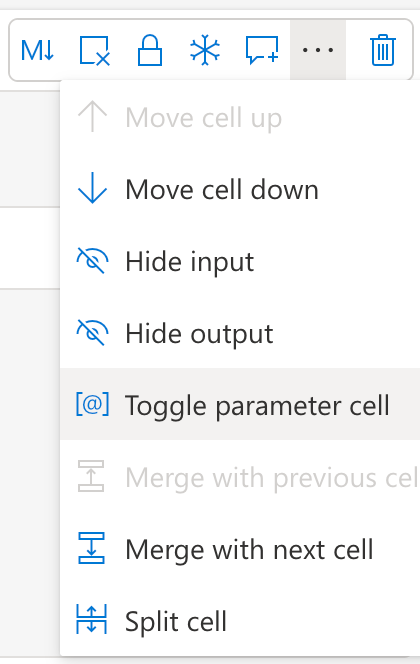
To make a cell a parameter cell, click on the ... next to the code cell and select Toggle parameter cell.
Imports
Next, we import all required libraries.
from datetime import date, datetime, timedelta, timezone
from typing import Any
import pandas as pd
import requests
from bs4 import BeautifulSoup
from delta.tables import *
from pyspark.sql.functions import *
- Pandas is used to create a DataFrame from the data we extract from the website.
- Requests is used to make the HTTP request to the website.
- BeautifulSoup is used to parse the HTML response.
- Delta is used to write the data to the Delta table with the upsert functionality.
- And finally, we import some functions from the PySpark library to see if we already ingested the data and avoid extra HTTP requests and CU consumption (read more about billing in my previous blog post.
Scraping functions
def _to_float(v: str) -> float:
return float(v.replace(",", ""))
def _as_date_str(v: date) -> str:
return v.strftime("%Y-%m-%d")
def extract_invokes(data: dict[str, Any]) -> dict[str, Any]:
invokes = {}
for entry in data:
if entry["command"] == "invoke":
invokes[entry["selector"]] = entry
return invokes
def fetch_data(delivery_date: date, market_area: str) -> dict[str, Any]:
trading_date = delivery_date - timedelta(days=1)
params = {
"market_area": market_area,
"trading_date": _as_date_str(trading_date),
"delivery_date": _as_date_str(delivery_date),
"modality": "Auction",
"sub_modality": "DayAhead",
"product": "60",
"data_mode": "table",
"ajax_form": 1,
}
data = {
"form_id": "market_data_filters_form",
"_triggering_element_name": "submit_js",
}
r = requests.post("https://www.epexspot.com/en/market-data", params=params, data=data)
r.raise_for_status()
return r.json()
def extract_table_data(delivery_date: datetime, data: dict[str, Any], market_area: str) -> pd.DataFrame:
soup = BeautifulSoup(data["args"][0], features="html.parser")
try:
table = soup.find("table", class_="table-01 table-length-1")
body = table.tbody
rows = body.find_all_next("tr")
except AttributeError:
return [] # no data available
start_time = delivery_date.replace(hour=0, minute=0, second=0, microsecond=0)
# convert timezone to UTC (and adjust timestamp)
start_time = start_time.astimezone(timezone.utc)
records = []
for row in rows:
end_time = start_time + timedelta(hours=1)
buy_volume_col = row.td
sell_volume_col = buy_volume_col.find_next_sibling("td")
volume_col = sell_volume_col.find_next_sibling("td")
price_col = volume_col.find_next_sibling("td")
records.append(
(
market_area,
start_time,
end_time,
_to_float(buy_volume_col.string),
_to_float(sell_volume_col.string),
_to_float(volume_col.string),
_to_float(price_col.string),
)
)
start_time = end_time
return pd.DataFrame.from_records(records, columns=["market", "start_time", "end_time", "buy_volume", "sell_volume", "volume", "price"])
The next 5 functions are used to scrape the data from the website. You can skip to the next paragraph if you are not that interested in the scraping itself. The code above basically works as follows:
- We submit an HTTP POST request (a submitted form) to the web page and the server responds with a JSON object. The request has to contain the parameters that the users would normally select on the website.
- Deeply nested inside this JSON object we get back, we find HTML code containing the table that contains the data we are interested in.
- We pass the HTML code to BeautifulSoup, which parses the HTML code for us and we ask it to look for for the table.
The interesting part is located at the end of the code snippet above. Here, we loop over all rows in the table and append each of them to a list of tuples. We also convert the date and time to UTC, so that we don't have to worry about timezones or daylight-saving time later on. Finally, we convert the list of tuples to a Pandas DataFrame.
def fetch_day(delivery_date: datetime, market_area) -> pd.DataFrame:
data = fetch_data(delivery_date.date(), market_area)
invokes = extract_invokes(data)
# check if there is an invoke command with selector ".js-md-widget"
# because this contains the table with the results
table_data = invokes.get(".js-md-widget")
if table_data is None:
# no data for this day
return []
return extract_table_data(delivery_date, table_data, market_area)
The last scraping-related function adds more error handling. It is not known when the pricing data becomes available, so the notebook will run multiple times a day until we have data for the next day.
First run & partitioning strategy
prices = fetch_day(datetime.now() + timedelta(days=1), market_area)
if len(prices) == 0:
mssparkutils.notebook.exit("No prices available yet")
spark_df = spark.createDataFrame(prices)
spark_df.write.mode("overwrite").format("delta").option("overwriteSchema", "true").partitionBy("market").saveAsTable("epex_spot_prices")
The code above is the version of the notebook that should be used on the very first run to initialize the Delta table. We call our scraping functions to fetch data for the market set above for the next day and then convert the Pandas DataFrame to a Spark DataFrame. We then write the Spark DataFrame to the Delta table.
The line mssparkutils.notebook.exit("No prices available yet") tells the notebook to exit gracefully, without errors, if the prices are not available yet.
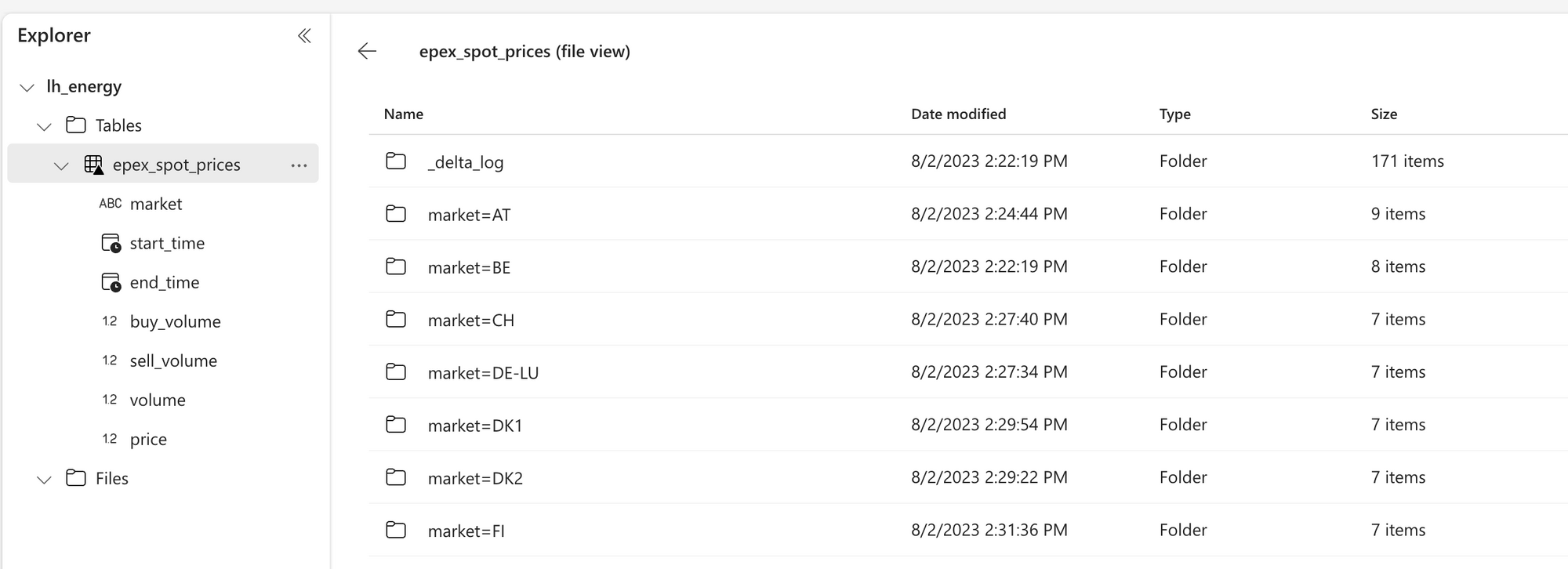
The last line is the most interesting one. We write the data to the Delta table and partition it by market. This means that the data will be stored in multiple folders, one for each market. The folder structure will look like this:
epex_spot_prices
|── _delta_log
├── market=AT
│ ├── part-00000-....parquet
│ ├── part-00001-....parquet
│ ├── ...
├── market=BE
│ ├── part-00000-....parquet
│ ├── part-00001-....parquet
│ ├── ...
├── ...
Delta tables are locked when they are written to, except when the multiple processes are not writing to the same partition. So partitioning by market allows us to run the notebook concurrently for different markets.
Subsequent runs
current = DeltaTable.forName(spark, "epex_spot_prices")
current_df = current.toDF()
current_df = current_df.withColumn("date", to_date(col("start_time")))
current_market_count = current_df.filter((current_df.market == market_area) & (current_df.date == _as_date_str(datetime.now() + timedelta(days=1)))).count()
if current_market_count == 24:
mssparkutils.notebook.exit("Already ingested")
On subsequent runs, we should avoid doing unnecessary HTTP calls by first checking if we already have the data for this market for the next day. Since there is one row per hour, we should have 24 rows per market. We can check this by counting the number of rows for the market and date we are interested in. If we have 24 rows, we can exit the notebook.
In the code above, I am loading the data first as a DeltaTable object so that we can use this later on to merge the new data with the existing data. I then convert the DeltaTable to a Spark DataFrame and add a column with the date. Then I filter the DataFrame to only contain the rows for the market and date we are interested in and count the number of rows.
prices = fetch_day(datetime.now() + timedelta(days=1), market_area)
if len(prices) == 0:
mssparkutils.notebook.exit("No prices available yet")
spark_df = spark.createDataFrame(prices)
current.alias("current").merge(spark_df.alias("new"), "current.market = new.market AND current.start_time = new.start_time AND current.end_time = new.end_time").whenNotMatchedInsertAll().execute()
Finally, we fetch the data for the next day and convert it to a Spark DataFrame. We then merge the new data with the existing data. The merge function is a Delta-specific function that allows us to merge two DataFrames. We merge the new data with the existing data on the columns market, start_time and end_time. We use the whenNotMatchedInsertAll function to insert all rows from the new DataFrame that do not match any rows in the existing DataFrame. This means that we will only insert the new rows. The execute function executes the merge operation.
This is where the magic of Delta Lake comes into play. Thanks to its transaction log, this merge or upsert operation becomes available. Doing the same thing with plain Parquet or CSV files would be much more difficult.
Since we have the check above, we could just ignore the merging and always append all new data, but years of data engineering have taught me that it is better to be safe than sorry.
The result
Now it's time to run the notebook and see it in action. I'm always amazed by how fast Fabric can spin up a Spark session. The same operation took minutes with the platforms that were available a few years ago.
After running the notebook, you can find the Delta table in the Lakehouse.
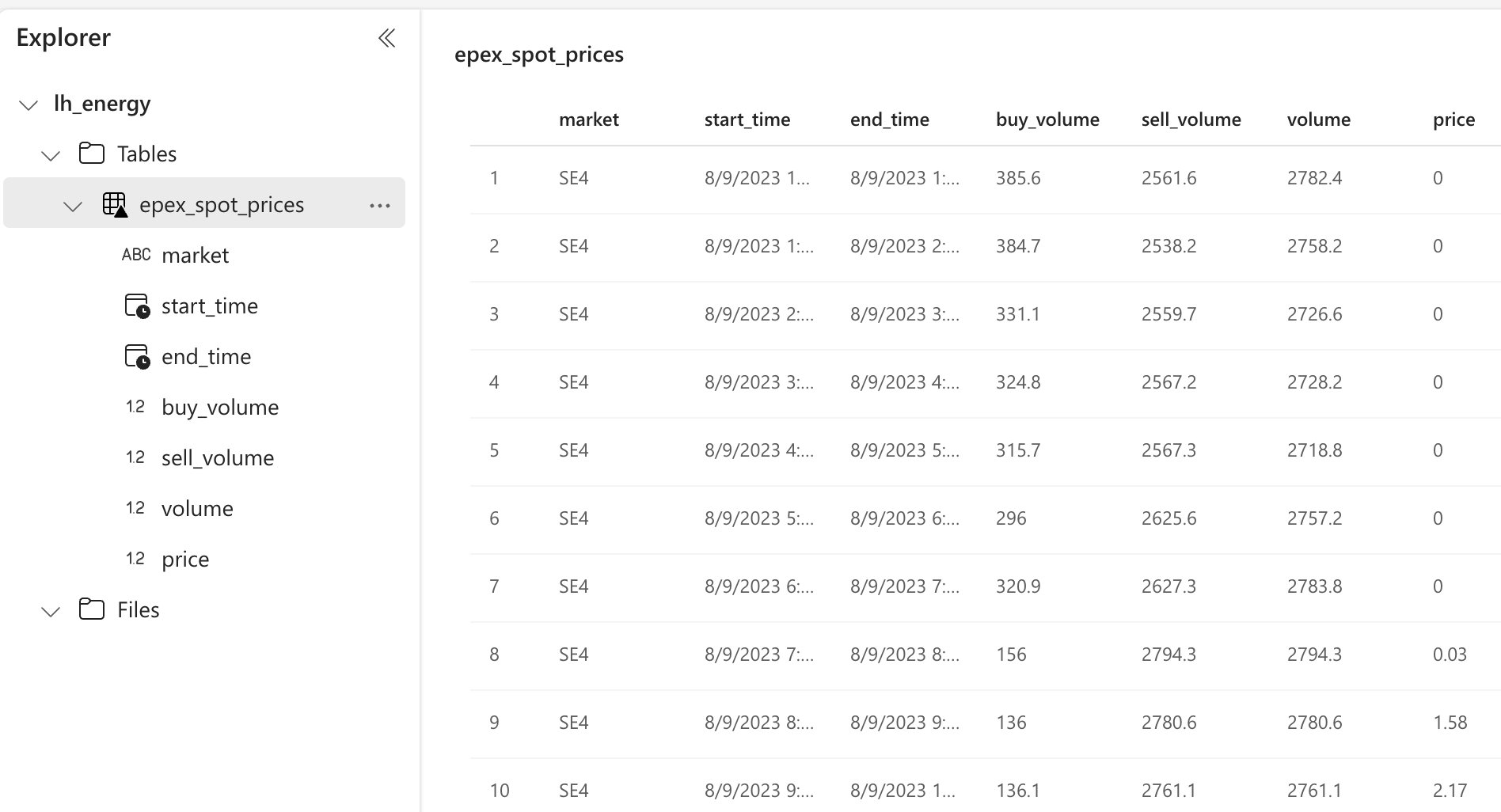
We can also check out the files by clicking on the ... and choosing View files. Here we see the partitioning strategy in action.
👉 Next part
In the next part, we'll use our Notebook in a Pipeline and schedule it to run a couple of times a day.
The link will start working as soon as the post is published, about a week after this one.