

By Toon Van Craenendonck
Deep neural networks offer unparalleled performance for many applications, but running inference can be resource-intensive. Model optimization comes in to help here, reducing disk storage, memory usage or compute requirements. This can be useful for deployment on the edge (to run models where it otherwise would not be possible), as well as for the cloud and on-premise (to run models faster, or allow more models te be stored in-memory simultaneously). Moreover, reduced energy requirements of optimized models can help to alleviate the strain that an ever-increasing number of models puts on our environment.
Model optimization techniques aim to compress models, without sacrifying too much accuracy. For example:
- Weight pruning can be used to remove model weights that have little effect on the network output.
- Weight clustering, as the name implies, clusters the weights of each layer, and replaces each individual weight by an index to its cluster centroid. Storing the centroid values only once and re-using indexes to these centroids in the weight matrix reduces model complexity.
- Knowledge distillation is a procedure in which a smaller (compressed) network is trained to mimic a larger model.
- Model quantization approximates neural network storage and inference by using bitwidths that are lower than floating point precision (eg. by using int8 or float16 instead of float32).
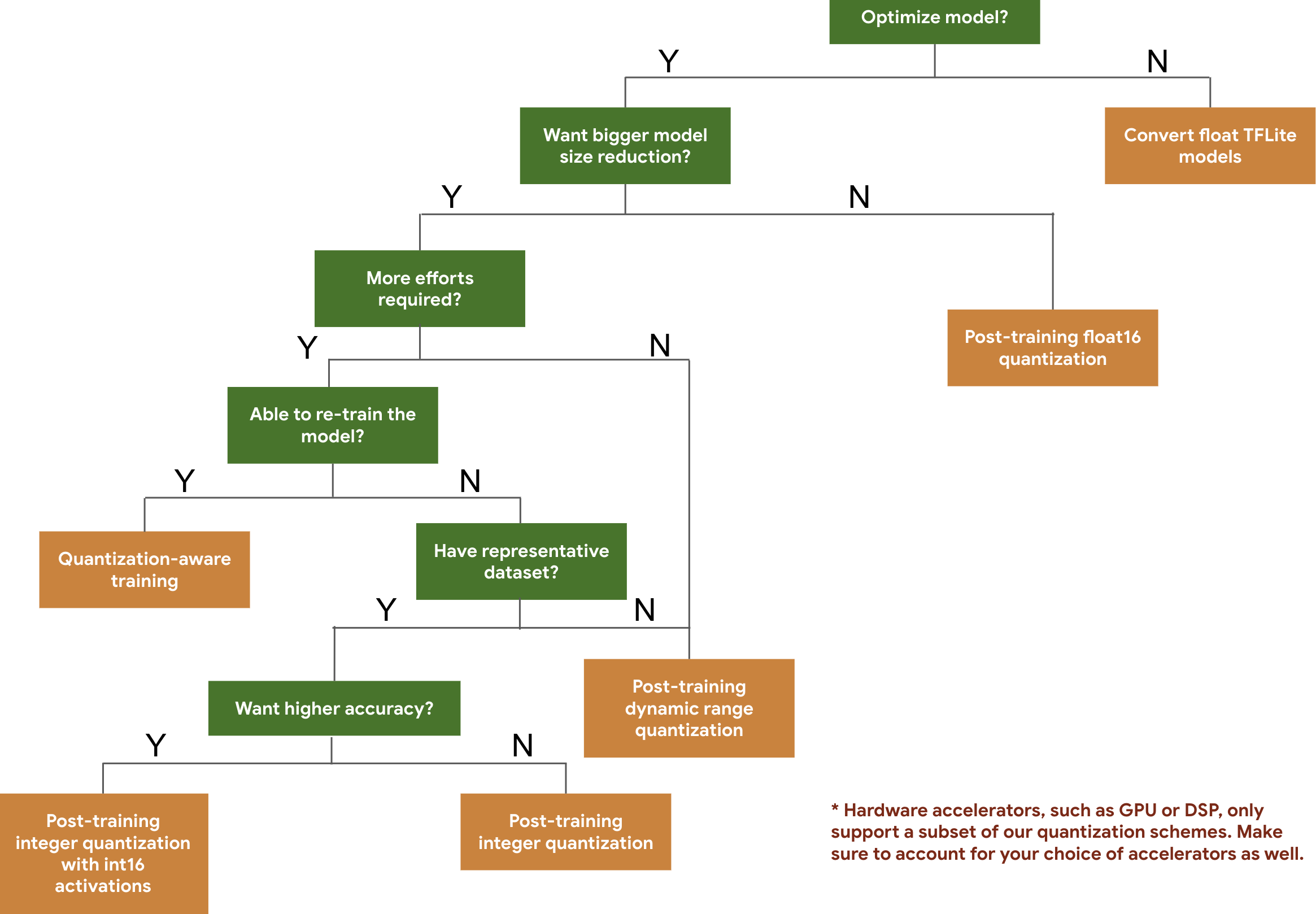
I'll briefly demonstrate model quantization, which can be applied to any model after training without the need for fine-tuning and typically provides good results out of the box. I'll be using TFLite, a framework that is tailored for edge inference. It offers several quantization methods, as the following decision diagram shows:

We'll use dynamic range quantization, which maps 32-bit floating point weights to 8-bit integers to achieve a 4x reduction in model size. Of course we'll need a model to compress, and for this example I have chosen a ResNet50 model that I trained a while ago to do face mask classification. This network was trained on faces with artificially generated masks, and achieves an accuracy of 90% on real face masks. If you want to follow this small experiment in a bit more detail, you can check out this notebook.
Optimizing the network
TFlite makes it incredibly easy to do compression. Once we have loaded our tensorflow model, converting it to TFlite format and applying dynamic weight quantization is as simple as this:
import tensorflow as tf
model_dir = Path('models')
model = tf.keras.models.load_model(str(model_dir / 'mask_classifier.h5'))
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
with open(model_dir / 'mask_classifier_quantized.tflite', 'wb') as f:
f.write(tflite_model)While our original ResNet50 model file was 94MB, our quantized version is only 23MB or roughly 1/4 of the original size as expected.
Verifying the accuracy of the compressed network
One might expect that throwing away 3/4 of the bits representing the network weights might significantly affect accuracy, but in practice quantization often has very little effect. Intuitively, neural networks are trained to be robust to noisy inputs, and this robustness allows them to deal with the noise introduced by lowering precision. Our original model has an accuracy of 90.7%. We can create a TFLite interpreter to make inferences, and apply it to each of our test set images to verify the accuracy of our quantized model (for the complete code, check the notebook):
interpreter = tf.lite.Interpreter(str(model_dir / 'mask_classifier_quantized.tflite'))
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
interpreter.allocate_tensors()
preds = []
for batch_idx in range(len(test_generator)):
for img in test_generator[batch_idx][0]:
interpreter.set_tensor(input_details[0]['index'], np.expand_dims(img, axis=0))
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
preds.append(output_data[0][0])
preds = [x > 0.5 for x in preds]
tflite_acc = metrics.accuracy_score(test_generator.labels, preds)
print(f"The quantized TFlite model accuracy = {tflite_acc:.3f}")It turns out that our quantized model achieves an accuracy of 91.89%, surprisingly even outperforming our original model. In general, though, one can expect slight drops in accuracy. If your drop in accuracy is unacceptable, you can use quantization aware training to improve your results.
Verifying memory consumption
We already know that our model consumes less disk space, but we're also interested in its memory consumption at inference time. TFLite provides a nice benchmarking tool to assess this. This runs your model with some randomly generated inputs, and collects statistics on latency and memory consumption while doing so. In our case, the original model had a memory footprint of 104MB, whereas the quantized model only consumes 25MB.
Finally, I want to note that model optimization is only one aspect to handling inference in resource-constrained environments, and depending on your use case you might want to take other aspects into account. For example, even without making any changes to the model, the choice of the inference framework can significantly affect inference time and memory usage (for example, TensorRT does clever things such as layer & tensor fusion or using dynamic tensor memory to reduce model memory consumption). If you know your constraints from the start, you might also opt for model architectures that are designed to be low-cost, such as MobileNet or EfficientNet.
If you want to read more on this topic, you can check out the tensorflow model optimization documentation or the list of interesting pointers collected at the Awesome ML Model Compression overview page.