

By GUPPI
As the surge in gas and electricity prices intensifies with the UK and European gas prices even closing at ten times their level from the beginning of the year, caused by a global supply crunch resulting from economies starting to recover from the pandemic along with the lower-than-expected gas supply from Russia, many consumers will be looking to cut their energy bills by finding the best deal possible on the market. This may even involve switching energy suppliers.
Due to the liberalization and unbundling of the energy markets in Europe, utility suppliers face an increasingly fierce competition and consumers find it easier to switch suppliers when they feel unsatisfied or when they can find better deals elsewhere. This shift resulted in a higher customer churn rate in the utilities sector.
Customer churn is defined as the tendency of a customer to quit buying a particular brand and hence stop being a paying customer of a particular company.
For a company, it would be quite useful to know which customer will churn in a particular time window so that they can still make an effort to retain this client. You might wonder why you would spend all that money on retaining clients that are on the verge of leaving. Well, research shows that it is 5 to 6 times more expensive to acquire a new customer than to retain one.
That being said, how would a company even know whether a customer will churn in the future? Should they hire some kind of fortune teller with a crystal ball? No, the answer here is data!
It is possible to implement machine learning algorithms that will predict the likelihood of a customer churning within a predefined period of time. As usual, here too, feature engineering will play a big part in improving the model’s performance.
As main drivers for customer churn in the utilities sector, we found as the number one reason the price of the contract and whether prices were increasing. The fact that there could be potential cost savings elsewhere can trigger consumers to have a more thorough look at their current bill and compare it to the bill they would have received if they had a different contract at a different supplier. Interesting features to include in the model would for instance be the difference in the price paid by the customer with the average price on the market, whether the price is increasing, whether the customers received discounts, whether the price rate is fixed or variable and so on.
Other drivers were customer service (using complaints data), more innovative offers from competitors (such as consumption tracking) and as people tend to become more environmentally conscious, another driver was the offer of green contracts.
Of course, other features such as customer engagement (e.g. number of emails sent to the supplier), customer demographics (e.g. age, gender, income level), transaction history (e.g. length of relationship, late payments) and interaction data (e.g. how long ago since the customer visited the company’s website, did the customer visit the pricing page) will also be valuable. Currently, there is a big panic on the energy markets which is reflected by soaring energy prices. The inclusion of information like spot prices, future prices and doing a change point analysis (which will detect a sudden increase or decrease in prices) will identify consumer sentiment and could also potentially be valuable to include in the model.
There are however also some pitfalls that need to be addressed when implementing a customer churn model.
The first pitfall is the train-test split. Careful considerations must be made here to avoid data leakage.
Let’s take a simple example of a business with two clients, namely X1 and X2 and six months of data. Let’s also, to simplify, agree that we want to predict the moment of churn itself. In practice, we would like to predict churn a few months in advance so that the business still would have time to target the customer with a retention campaign. We could then model this as a batch process that will check each month which customer will churn in the next three months. However, this solution would not be optimal for a real-time or next-best-action type of model (and is out of scope for this post).

What would happen now if we use the commonly used random train-test split. The dataset would look something like this:
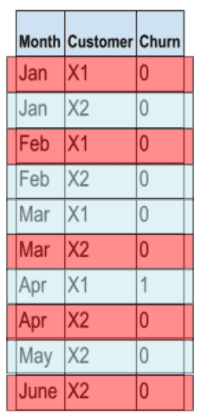
The blue records will belong to the train set, whereas the red ones will belong to the test set.
As you can see, there are two kinds of data leakage involved with this split:
- Time-based: the model will already have seen information from the future. Example: the model will train on the knowledge that customer X1 was still a client in March and will predict the likelihood of X1 churning in January. If we know that client X1 is still a customer in March, then he will be a customer in January too.
- Instance-based: both the train and test set contain the records of X1 and X2. The model will already incorporate information about X1 and X2 while training
The recommended approach here would be to split in both a time- as well as instance-based way to minimize the risk of data leakage. This way, the train data will only comprise data of X1 ranging from January up to March. The test set will contain data from only X2 ranging from April up till June. This ensures that the train and test sets are independent.
Another pitfall to consider is the very imbalanced nature of the data. In Europe, the average churn rate in the utilities sector ranges from 12% to 15%. As a consequence of this big skew in the data, the model will tend to give more importance to the majority class and might tend to neglect the minority class. There are various methods designed to tackle this problem (such as random oversampling, random undersampling, SMOTE, ADASYN), but we will not go into further detail.
Now just another quick final remark on another interesting technique to improve your business’ retention rates: uplift modeling.
In classic churn problems, we attempt to predict those customers who are about to churn. Uplift modeling, on the other hand, will try to predict which customers will churn and can be retained if targeted.
Customers can be divided into 4 groups:
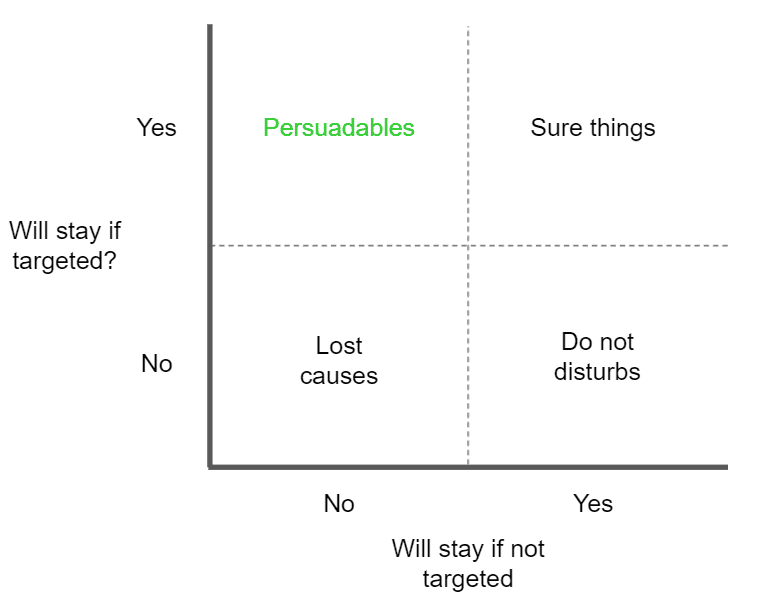
The goal of uplift modeling is to predict which of the customers belong to the persuadables group as targeting this group will bring the most added value for the business. This group, if targeted, will stay and will continue to bring in revenue.
To perform uplift modeling, additional information is needed, namely information about which of the customers were targeted with retention campaigns and which were not.
To conclude, it is crucial for businesses to maximize their retention rate as it is way more expensive acquiring new customers than retaining the existing ones. Especially in these times of big uncertainty and rapidly rising prices, utility companies could face higher customer churn rates. Machine learning can help in this endeavor by predicting the likelihood of a consumer churning in the near future so that these could still be retained by targeting them with for instance promotional campaigns. However, some considerations must be made to avoid data leakage while splitting the data into a train and test set. The recommended approach here is to make the split in such a way that the customers only belong to either the train or validation set and ensure that the train set is prior to the validation set. Moreover, the highly imbalanced nature of the data makes training a model also more complicated. This can be tackled by resampling the data. Lastly, uplift modeling will tackle the problem the business is most interested in: namely the identification of the customers that will churn, but can still be retained when targeted with a retention campaign.