

By Andrea Benevenuta
Large Language Models (LLMs) have recently emerged as a groundbreaking advancement in the field of natural language processing. These models are designed to comprehend and generate human-like text, exhibiting a remarkable ability to understand context, grammar, and even nuances in language. One of the applications of such models is to extract relevant information from vast document collections. By extracting pertinent information, LLMs can be used to efficiently provide fast and precise answers when users inquire about these documents.
Our in-house solution, AIDEN (AI Driven-knowledge Enhanced Navigator), works by taking a question from the user, scanning the relevant documents, and serving up an answer based on its understanding. It is capable of doing that by sifting through a variety of documents such as PDF files and web pages.
AIDEN incorporates several essential components. Firstly, it utilizes a Large Language Model as its core. Secondly, it employs a custom prompt with specific instructions to guide its responses. Additionally, it includes a memory component to retain information from past interactions with the user. Lastly, it utilizes a retrieval mechanism that lets it delve into the documents (untrained data) in an efficient way. The whole process is orchestrated by LangChain, an open source Python library built to interact with LLMs.
In this post, we want to focus on the data preparation process. Our goal is to prepare and structure the data as efficiently as possible so that our application can find the answers efficiently. In the next chapter we will delve into the different steps of the process and some challenges we faced.
Data preparation journey
An essential part of our application resides in how to structure our data (markdown, pdf, textual files for example) in order to get an accurate and fast response. Suppose you have a PDF document with thousands of pages and wish to ask questions about its content. One solution could be to directly include the entire document and the question in the prompt of the model. This is not feasible due to the limitations of LLM’s context window. Models, like GPT-3.5, have a constrained context window, often equivalent to just a single or very few pages of the PDF.
To tackle this challenge, we need a strategic approach to provide the LLM with the most relevant parts of the document that might contain the answer to the query.
Here is an overview of what the data preparation workflow looks like.
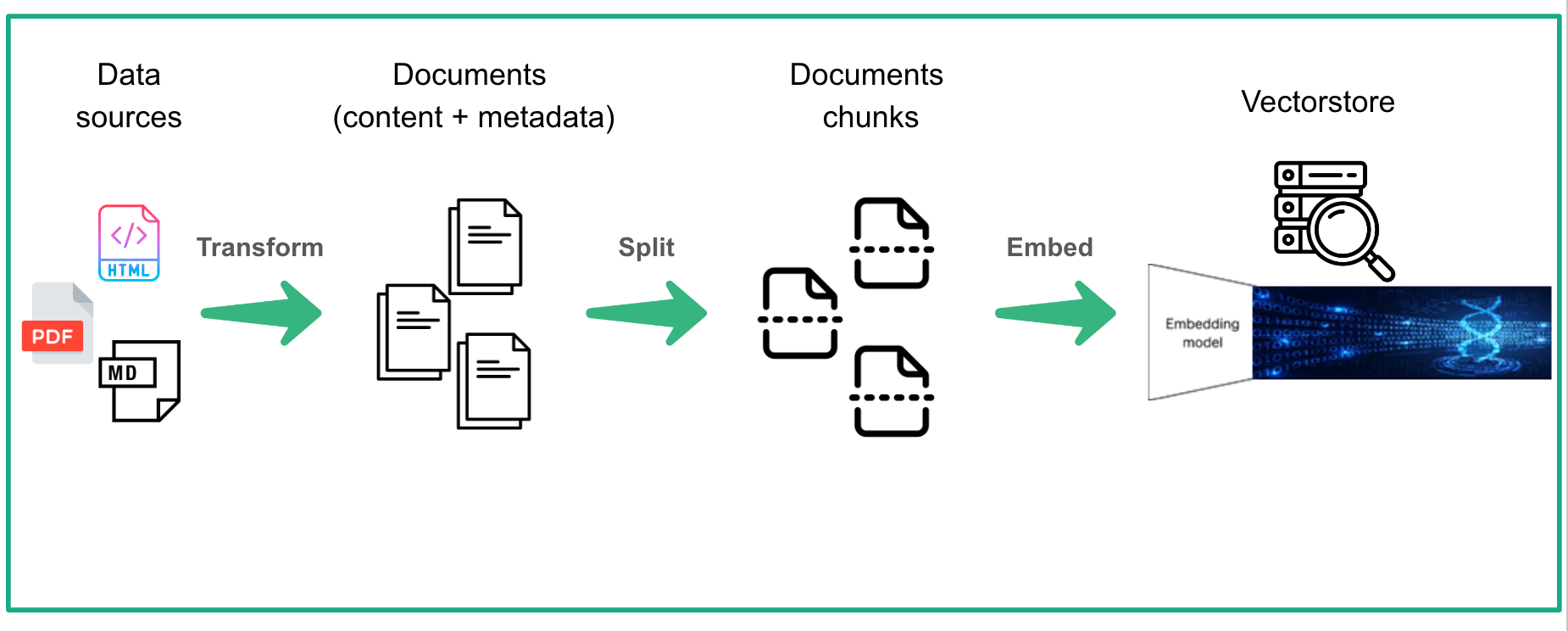
In essence, instead of storing documents as they are, we transform them into vectors of numbers. These vectors capture the meaning and relationships within the documents and are saved in a special storage system called vector store. When we ask a question, the vector store helps the LLM find information quickly, by matching the relevant information that can be used to answer the question.
In the following sections, we will explain all the necessary steps of the data preparation workflow and the details of each step.
Step 1: From Raw Data to Structured Documents
The first crucial step in our data preparation process involves converting raw data into structured documents. What we do here is to convert each page of our files into a Document object which consists of two key components: page_content and metadata.
The page_content represents the textual content extracted from the document page itself. The metadata encompasses additional details, including the source of the document (the file it originates from), the page number, file type, and other relevant information. This metadata is important in tracking the specific sources utilized by the LLM when generating answers.
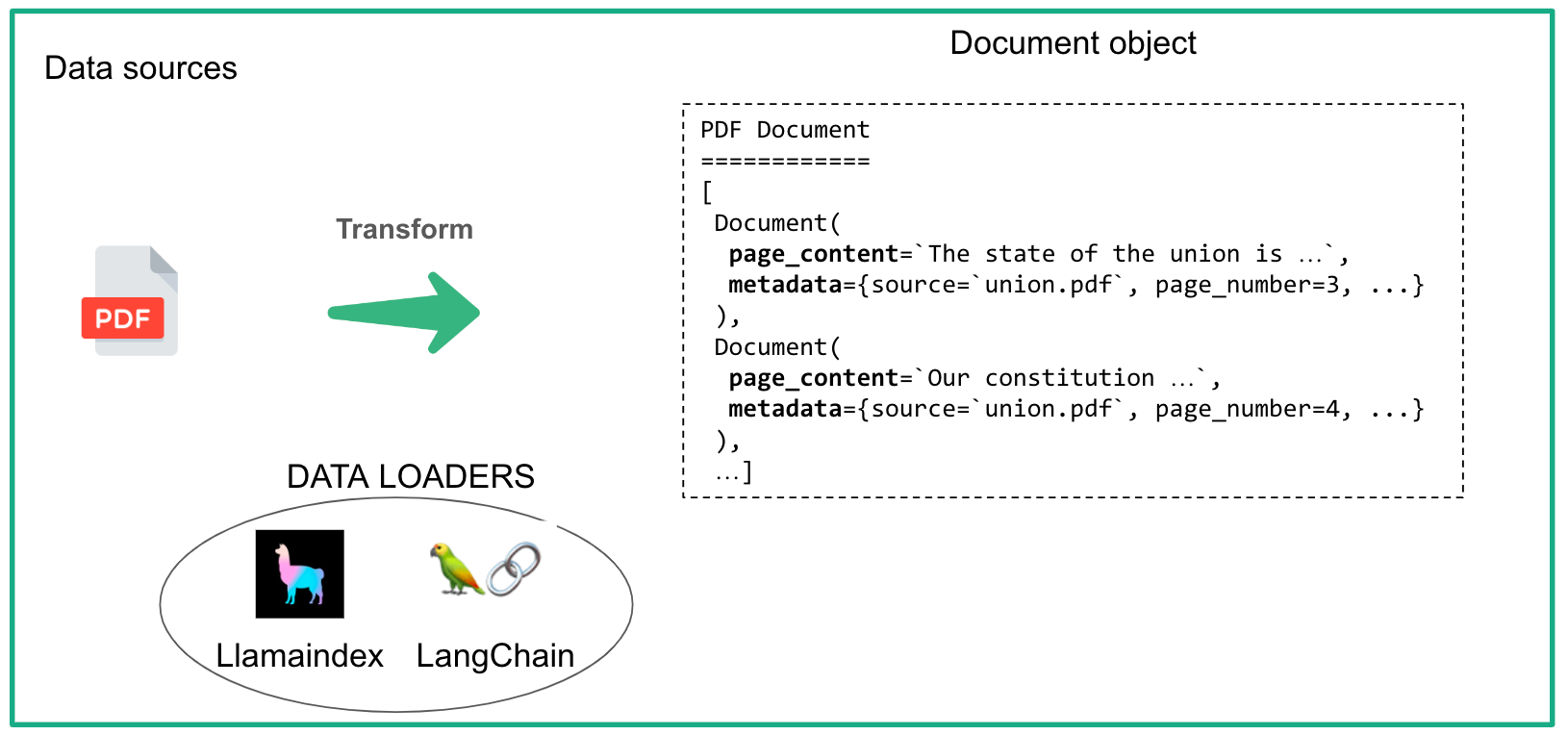
To accomplish this, we leverage robust tools such as Data Loaders, which are offered by open-source libraries like LangChain and Llamaindex. These libraries support various formats, ranging from PDF and CSV to HTML, Markdown, and even databases.
Step 2: From Structured Documents to Document Chunks
Structuring our documents is an important step, but it's not sufficient on its own. Sometimes, a single page can contain a substantial amount of text, making it infeasible to add to the LLM prompt, due to the limited context window. Additionally, the answer to a specific question may require combining information from different parts of the knowledge base.
To address these limitations, we adopt a solution by dividing our structured documents into smaller, more manageable chunks. These document chunks enable our LLM application to process information in a more efficient and effective manner, ensuring that information required to provide a relevant and sufficiently comprehensive answer is not overlooked.
Concretely, we can make use of a functionality provided by LangChain: RecursiveCharacterTextSplitter. It is a versatile tool for splitting text based on a list of characters. It aims to create meaningful chunks of a specified length, by progressively splitting at delimiters like double newlines, single newlines, and spaces. This approach preserves semantic context, by keeping the paragraphs, sentences, and words together, retaining their meaningful connections. It is therefore ideal when we are dealing with textual data.
Using this object is fairly simple. We need to pass the Document and specify the desired length of each chunk (for example 1000 words). Additionally, we can specify how many overlapping characters to include between adjacent chunks.
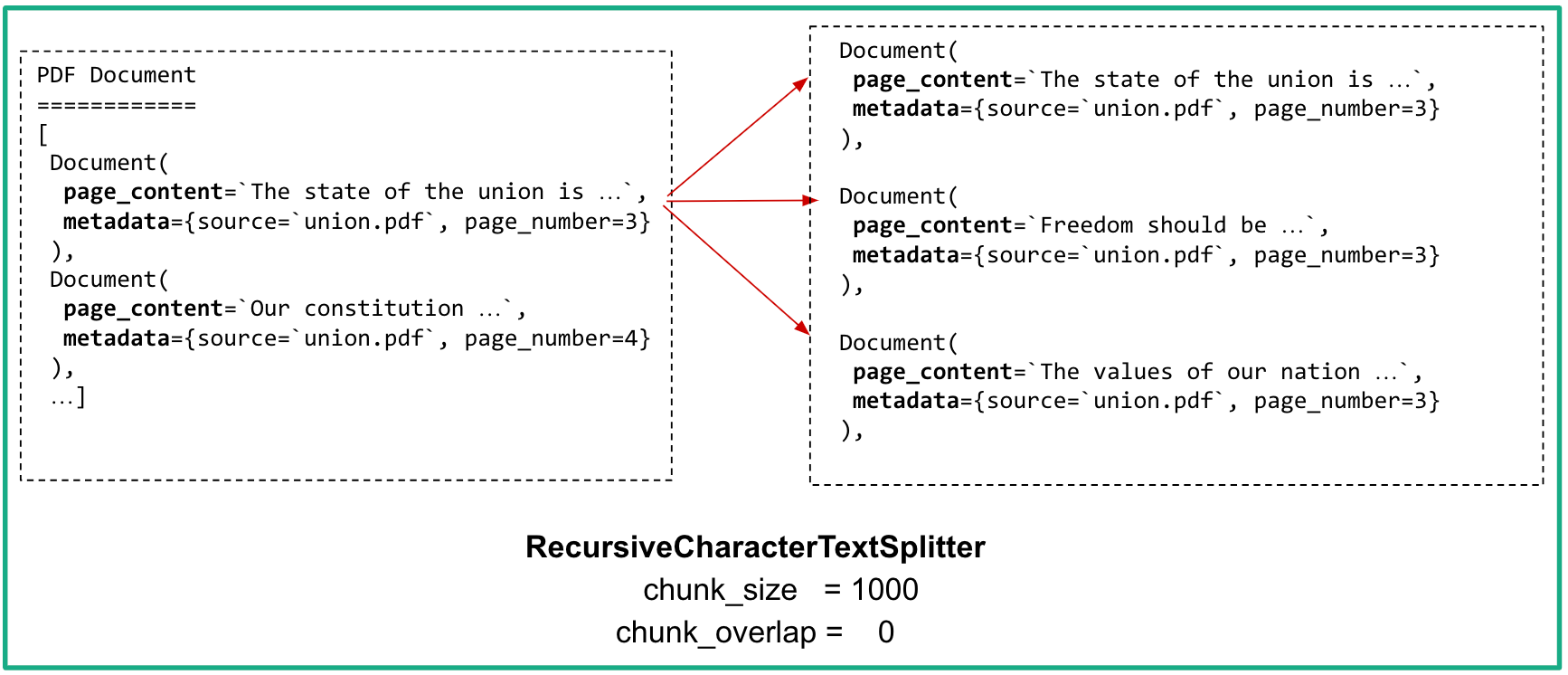
By employing this method of dividing documents into smaller chunks, we enhance the application's efficiency to navigate through the documents, extract relevant information, and provide accurate responses
Step 3: From Document Chunks to Vector Stores
Having several structured text chunks is not enough to exploit the full capabilities of LLMs and implement an efficient retrieval mechanism: that is where vector stores come to the rescue!
A vector store refers to a data structure or database that stores pre-computed vector representations of documents or sources. The vector store allows efficient similarity matching between user queries and the stored sources, enabling our application to retrieve relevant documents based on their semantic similarity to the user's question.
We can break the process of defining a vector store into two different steps.
First, we need to transform each text chunk into a numerical vector, called embedding. Embeddings are the representations or encodings of tokens, such as sentences, paragraphs, or documents, in a high-dimensional vector space, where each dimension corresponds to a learned feature or attribute of the language (e.g. semantic meaning, grammar, ...).
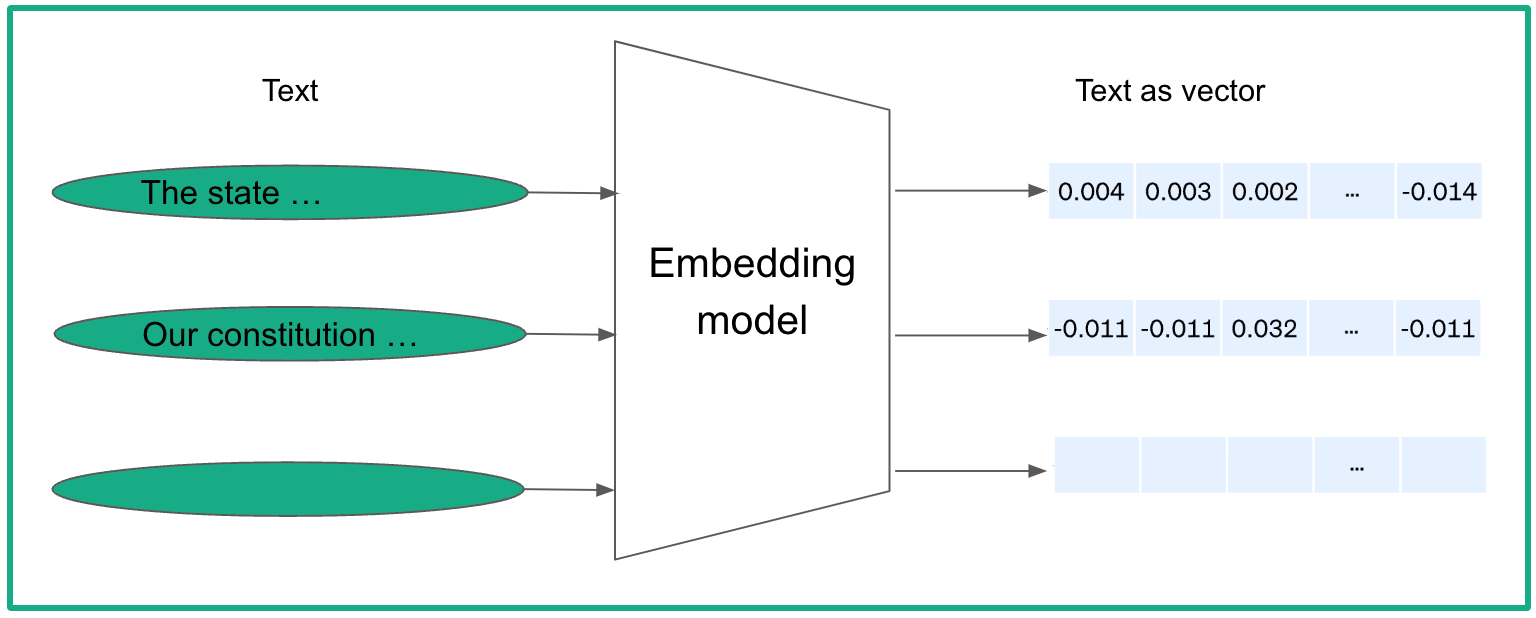
As for the embedding model, there is a wide range of options available, including models from OpenAI (e.g. text-embedding-ada-002, davinci-001) and open source versions from HuggingFace.
Once a model is chosen, a corpus of documents is fed into it to generate fixed-length semantic vectors for each document chunk. We now have a collection of semantic vectors that encapsulate the overall meanings of the documents.
The second step consists in defining indexes, data structures that organize vectors in a way that enables efficient search and retrieval operations. When a user asks question, the index basically defines the search strategy to find the most similar, hence relevant documents in our vector store. Such indexing strategies range from a simple brute force approach (FlatIndex) that compares all vectors to the query, to more sophisticated methods suitable for large-scale searches.
Indexes and embeddings together constitute a vector store. There are different types of vector stores, including Chroma, FAISS, Weaviate, and Milvus. For our application we opted for one of the most widely used libraries for efficient similarity search and clustering of dense vectors: FAISS (Facebook AI Similarity Search).
For a more detailed analysis of some indexing strategies provided by FAISS, you can have a look here:
Deep dive into FAISS indexing strategies
- **FlatIndex**: The simplest indexing strategy, where all vectors are stored in a single flat list. At search time, all the indexed vectors are decoded sequentially and compared to the query vectors (brute force approach). It is efficient for small datasets but can be slow for large-scale searches. Flat indexes produce the most accurate results but have significant search times. - **IVF** (Inverted File): This strategy partitions the vectors into multiple small clusters using a clustering algorithm. Each cluster is associated with an inverted list that stores the vectors assigned to that cluster. At search time, the system computes scores for the clusters based on their relevance to the query and selects the cluster with the highest relevance score. Within that cluster, the system retrieves the actual vectors/documents associated with the inverted lists and makes the comparison with the query to find the most relevant sources.IVF is memory-efficient and suitable for large datasets. It offers high search quality and reasonable search speed. - **PQ** (Product Quantization): This strategy partitions the vector space into subspaces and quantizes each subspace independently. The query is quantized in a similar manner as the vectors during preprocessing. The system compares the quantized subspaces of the query with the quantized subspaces of the indexed vectors. This comparison is efficient and allows for fast retrieval of potential matches. It reduces memory usage and enables efficient vector comparison. However, it may lead to some loss in search accuracy. - **HNSW** (Hierarchical Navigable Small World): This indexing strategy constructs a graph where each vector is connected to a set of neighbors in a hierarchical manner. Using the structure of the graph, the system navigates through the graph to explore the neighbors of the starting point, gradually moving towards vectors that are closer to the query. HNSW is particularly effective for high-dimensional data. It is one of the best performing indexes for larger datasets with higher-dimensionality.The choice of indexing strategy depends on the data characteristics and specific application requirements. Something to evaluate is trade-offs between accuracy, memory usage, and search speed. For example, when working with a small number of documents, using brute force with a FlatIndex should be sufficient.
Query and Document Comparison
Now that our data has been structured into a vector store for efficient retrieval, we can go through the last step: how to retrieve relevant documents when a user asks a question.
Firstly, the query gets embedded into a numerical vector, using the same embedding model that was utilized for the documents. This vector is then compared to the vector store, which contains pre-computed vector representations of the documents.
Using the chosen indexing strategy and similarity measure, the LLM application identifies the top K most similar documents to the query. The number K can be adjusted according to preferences.
For example, let's say we have a small set of documents and we created a vector store using the FlatIndex strategy, the Euclidean similarity metric, and we set K=3. When a question is asked, it is mapped to the embedding space and our application retrieves the top 3 most similar documents chunks.
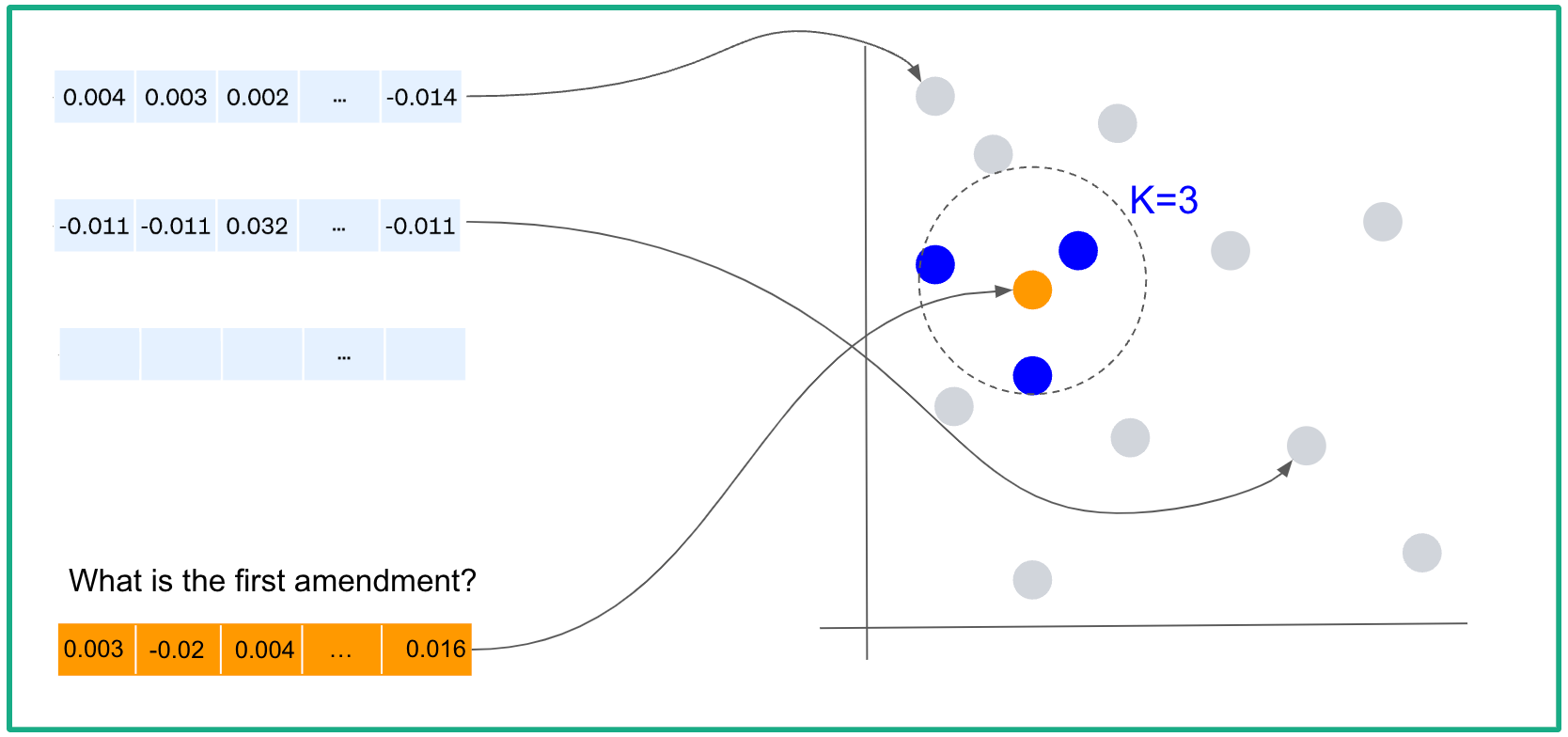
These documents chunks are then passed to the LLM prompt (together with a set of instructions and the user's question) and the app will provide an answer based on the available information.
The Struggle of LLMs in Tackling Structured Data Queries
While the approach described earlier works well for textual data like PDF files or web pages, it faces limitations when dealing with structured data such as CSV files or databases. These types of data present challenges in preserving the global structure of the underlying tables when they are split into multiple document chunks.
To address this, specific data loaders have been developed to split each row of the structured data into a separate document and replicate the table structure. However, due to the limited context of the language model, for a table with hundreds of records, passing all hundreds of documents during retrieval is not feasible. This approach may still work for specific queries that require a few rows of the table to provide a good answer. However, for more general queries like finding the maximum value in a column, the model's performance suffers.
In such cases, it is preferable to use a LLM agent that can execute SQL statements or Python code to query the entire database. This alternative approach has also its own limitations. It introduces longer latency as the agent needs time to process and reason, and the accuracy may be affected as agents can be prone to instability in certain cases.
Conclusion
In this blog post, we have discussed the key components involved in developing an app that utilizes Large Language Models to provide accurate answers based on a corpus of documents. Our main focus has been on the data preparation step, where we have outlined effective techniques for preprocessing documents to optimize the retrieval process. By structuring and dividing the data into manageable chunks and employing advanced embedding methods, our app creates a vector store. This structure enables the comparison of user queries to retrieve relevant information in a fast and efficient way.
We have also acknowledged that there are certain limitations when it comes to structured data, which may require a different approach than the one provided by LLMs.
Furthermore, there exist numerous open challenges within these applications and the broader context of LLMs. These challenges include tackling model hallucinations by implementing protective measures, ensuring robustness and fairness, and considering privacy and compliance aspects. By actively addressing these challenges and continuously advancing the field, we can enhance the capabilities of apps powered by LLMs. This will result in more reliable, responsible, and effective systems that provide users with valuable and trustworthy information.
You might also like
 timleers
timleers
