

By Vitale Sparacello
Intro
AI has changed our world, intelligent systems are part of our everyday life, and they are disrupting industries in all sectors.
Among all the AI disciplines, Deep Learning is the hottest right now. Machine Learning practitioners successfully implemented Deep Neural Networks (DNNs) to solve challenging problems in many scientific fields.
Nowadays, cars can see how busy a crossroad is, it’s possible to have pleasant conversations with imaginary philosophers, or we can simply have fun watching AIs destroying our favourite pro gamers. Until we have enough data to train models, the only limit is imagination.
In very broad terms, the data we use to train Deep Learning models belongs to two main domains:
- Euclidean data: data represented in multidimensional linear spaces, it obeys Euclidean postulates. Examples are text or tabular data (e.g. Dogecoin price over time)
- non-Euclidean data: in even broader terms, data that doesn’t obey Euclidean postulates (e.g. in these domains the distance between two points is not a straight line). Examples are Molecular Structures, Social Network Interactions, or Meshed 3D surfaces.
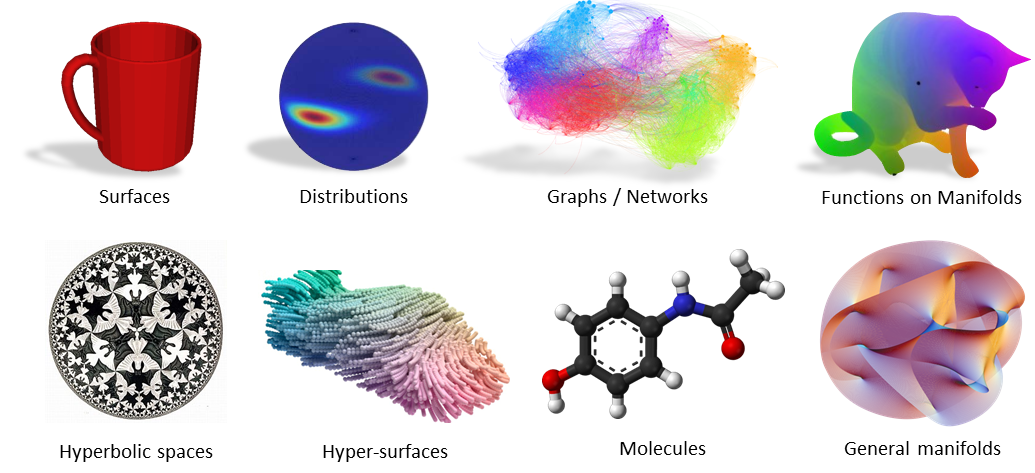
In applied AI, Deep Learning models work very well with Euclidean data, but they struggle when dealing with non-Euclidean data. This is a huge problem because it's common to find data of this nature in all the scientific fields!
Luckily, in the past few years, ML practitioners (❤️ ) coined the term Geometric Deep Learning and started formalizing the theory to solve this issue. This emerging AI field tries to generalize DNNs to tackle non-Euclidean domains using geometric principles.
Why is geometry so important?
Since the Greeks era, Euclidean Geometry has been the only discipline for studying geometric properties. Even now, Euclidean Geometry is a powerful tool to describe many of the phenomena around us. As we saw before, it follows simple principles and is straightforward to understand: e.g. the distance between 2 points is a straight line, or all the right angles are congruent.
However, during the 19th century, many mathematicians derived alternative geometries by changing Euclid's postulates. They also realized that these new geometries were very good at explaining how objects interact in different spaces. Examples include the hyperbolic geometry of Lobachevsky or the Elliptic geometry of Riemann.
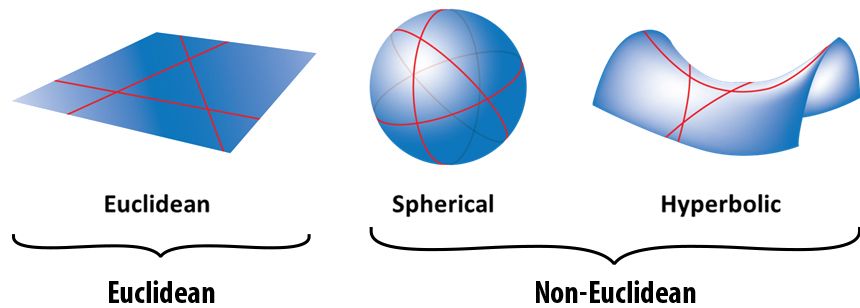
Unfortunately, all these different geometries diverged in multiple independent fields. A legit question at the time was: which is the True One?
Luckily in 1872, professor Felix Klein solved this intricate puzzle with his work called Erlangen Program. He proposed a framework to unify all the geometries by using the concepts of Invariance and Symmetry.

This idea led to a blueprint for defining a geometry by just specifying the domain where the data lives and what symmetries that data must respect.
The Erlangen Program had a significant influence on all the scientific fields, particularly in Physics, Chemistry and Math.
Deep Learning on non-Euclidean data
Deep Learning researchers are exceptional. Every day more than 100 ML articles are published on Arxiv! We are flooded with new models that promise to solve problems better than the others, but we don't have unifying rules to define AI architectures able to generalize their properties on all the possible data domains.
Convolutional Neural Networks (CNNs) are one of the most important algorithms in Machine Learning. CNNs can acquire high level information from images, videos or other visual inputs. For this reason they have been widely used to solve Computer Vision problems.
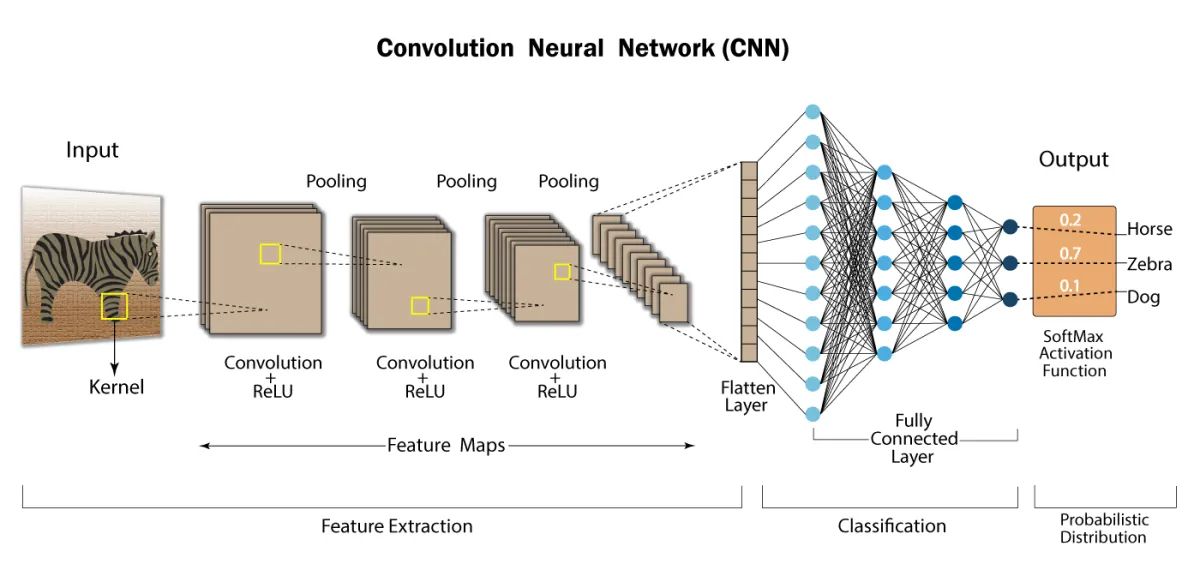
The term Convolution refers to a very simple operation: slide a little matrix (usually called filter) over an image and perform an element-wise multiplication followed by a sum to produce another matrix (see gif below). With this operation is possible to extract low level features from the input image like edges, shapes or bright spots.
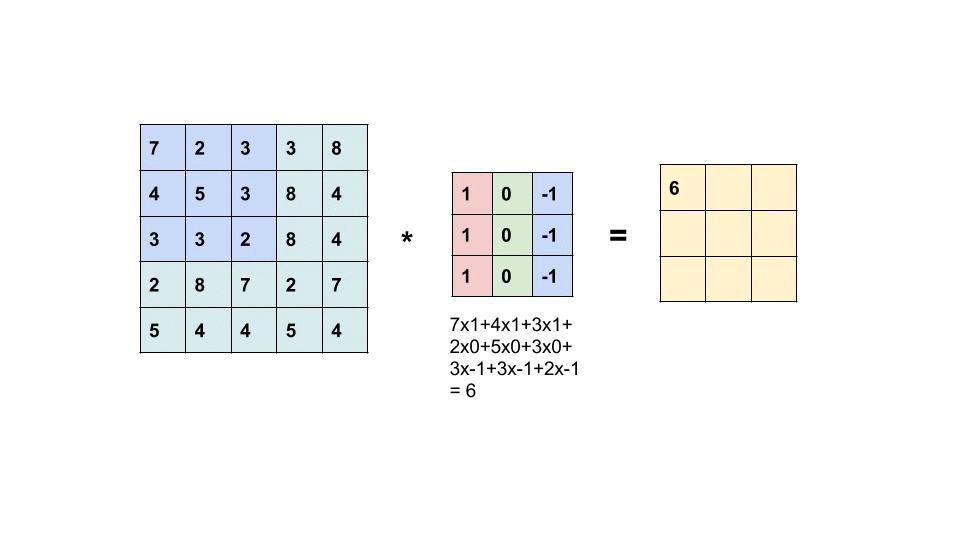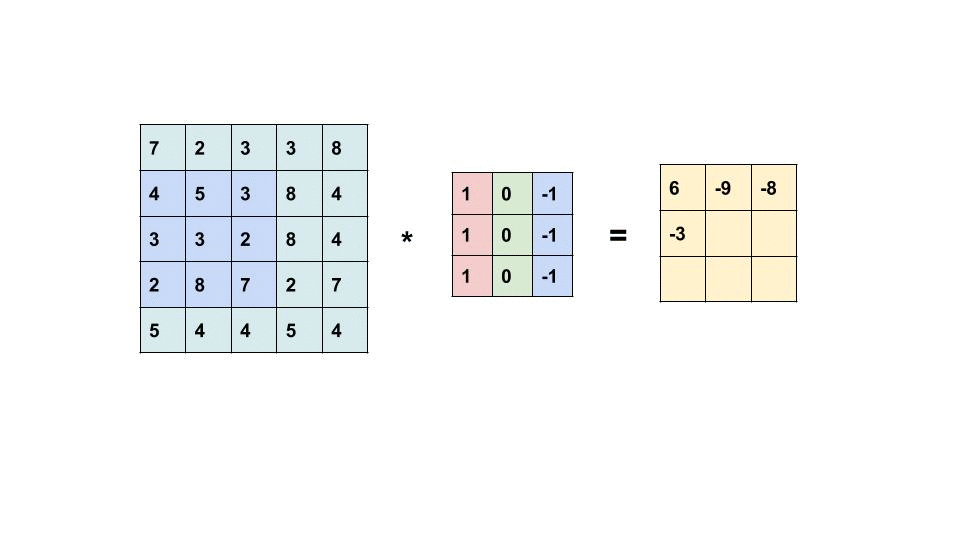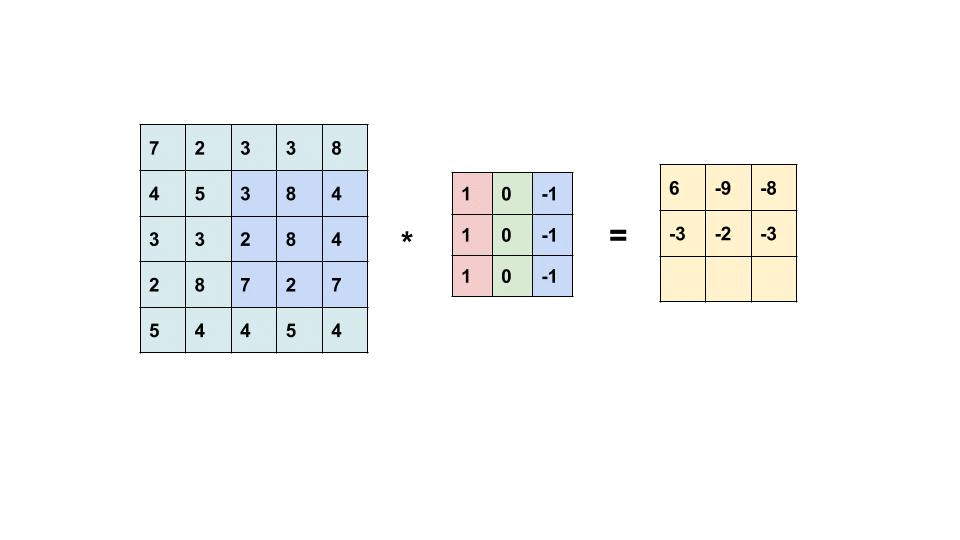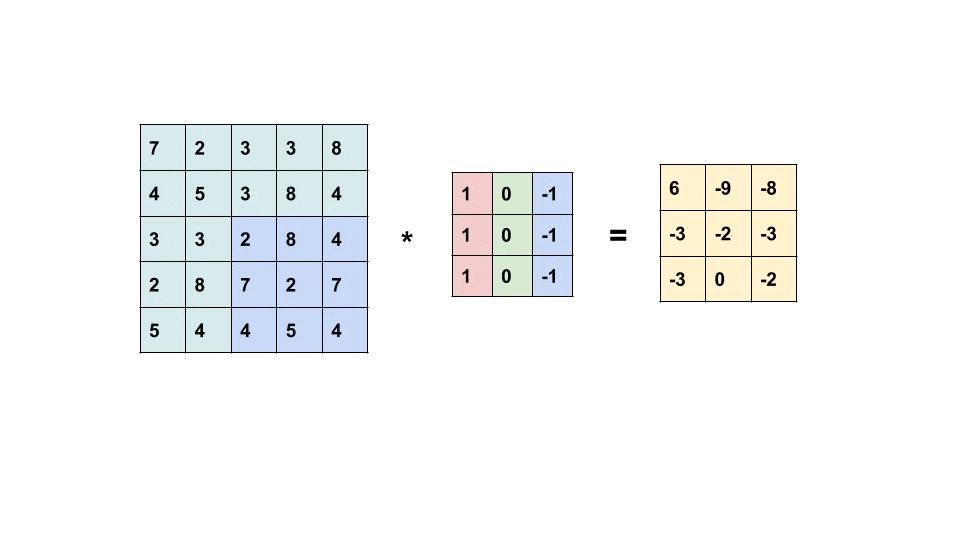
Convolutions work because we represent images using a 2-D data structure. In this way it’s possible to share the network weights using convolutional filters, and extract information regardless of shifts or distortions of the input images (the same filter is applied through all the image). This has been the first example of problem simplification by using the geometry of the input data.
How can we formalize and extend this idea for other domains? Maybe applying geometric principles can help us as it happened in the past.
Why is learning on non-Euclidean data complicated?
Unfortunately, non-Euclidean data suffers from dimensionality curse! To explain it better, let's consider one of the main ML applications: Supervised Learning. Its primary goal is to learn to solve a task by approximating a function using training data. (Functions are the result of DNNs training, we'll use the word function in the following section)
Thanks to the universal approximation theorem, we know that we can use even a simple Neural Network to reproduce any continuous function (to any desired accuracy).
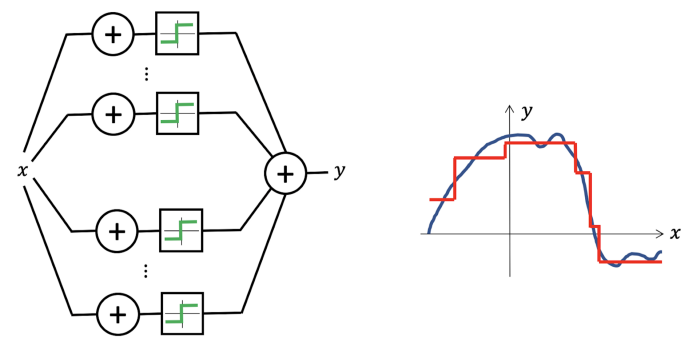
Unfortunately, things get complicated in high dimensions: we need an exponential number of samples to approximate even the most straightforward multidimensional function.
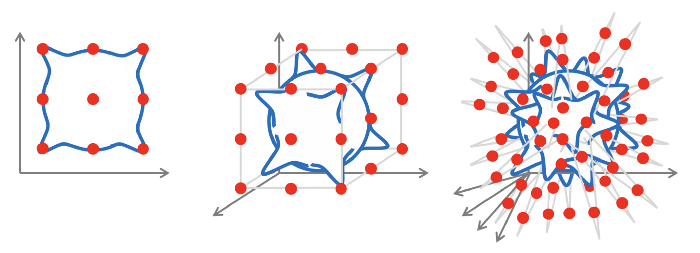
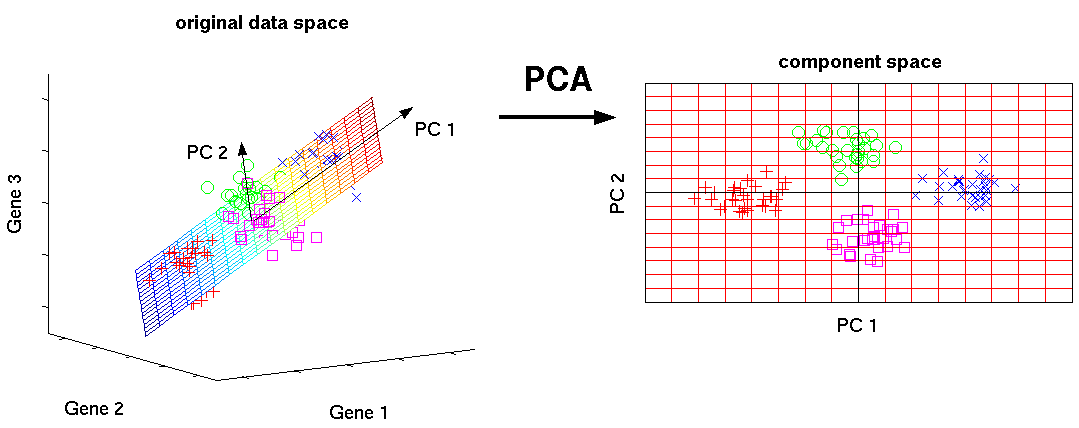
A common fix for this issue is to project high dimensional data to a low dimensional space (for example reducing dimension using the PCA algorithm) However, this is not always possible because we may discard important information.
To overcome this problem, we can use the geometric structure of input data. This structure is formally called Geometric prior and it is useful to formalize how we should process the input data.
For example, considering an image as a 2-D structure instead that a d-dimensional vector of pixels is a Geometric prior. Priors are important because by using them, it's possible to restrict the number of functions that we can fit with the input data and make the high-dimensional problem tractable.
For example by considering geometric priors, it is possible to identify functions that:
- Can process images independently of any shift (CNNs);
- Can process data projected on spheres independently of rotations (Spherical CNNs);
- Can process graph data independently of isomorphism (Graph Neural Networks).
Geometric Deep Learning identifies two main priors our functions must respect to simplify the problem and injecting geometric assumptions to input data:
- Symmetry: is respected by functions that leave an object invariant, they must be composable, invertible, and they must contain the identity;
- Scale Separation: the function should be stable under slight deformation of the domain.

These two principles are not theoretical definitions but they are derived from the most successful Deep Learning architecture (like CNNs, Deep Set and Transformers).
The Geometric Deep Learning priors give us the blueprint to define Deep Learning architectures that can learn from any data. If the class of functions we define respect these properties we can tackle any data domain.
Geometric Deep Learning applied in Graph Neural Networks
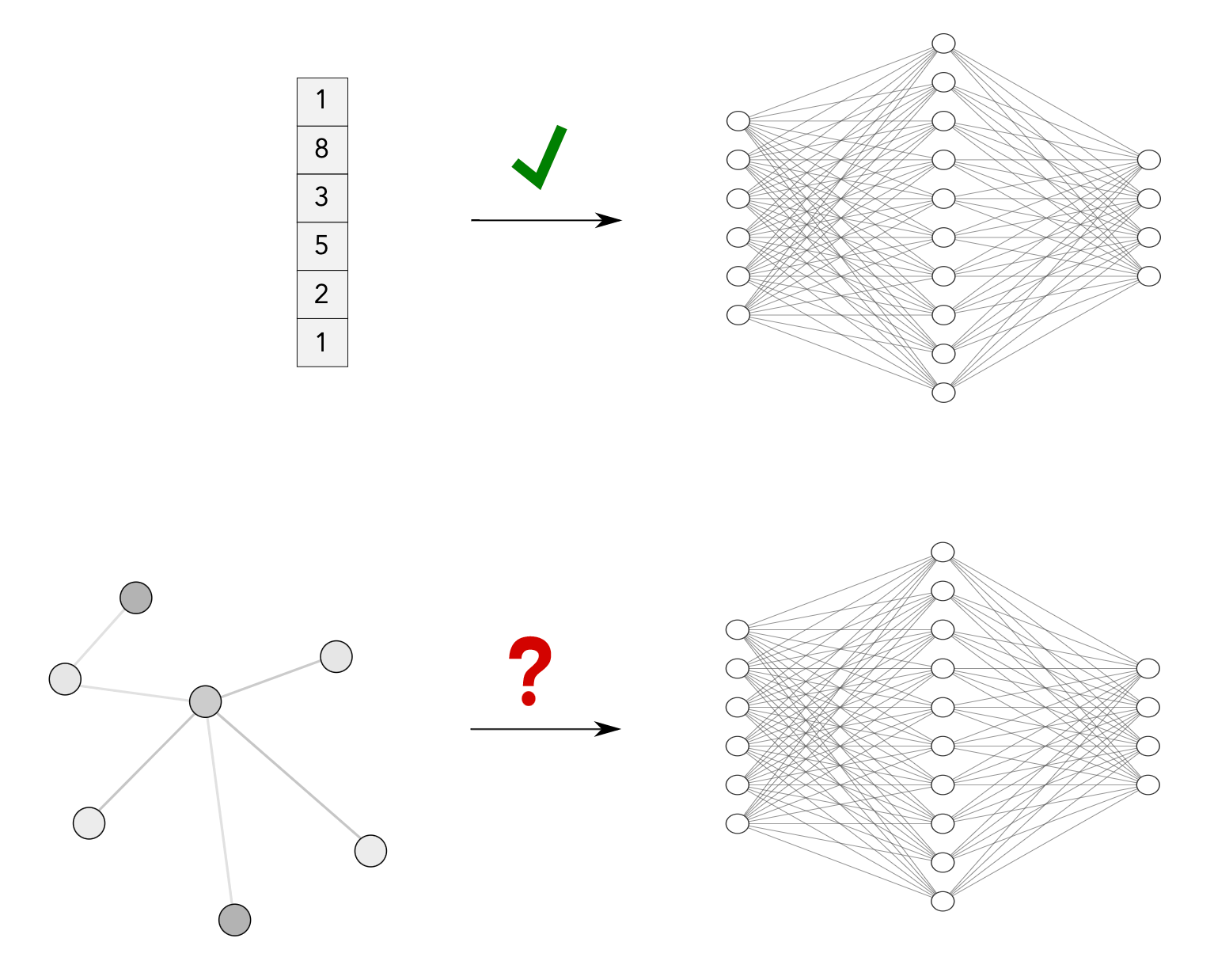
Graphs are the most flexible data representation. Objects in the real world usually have relationships or connections with other objects, representing them as graphs is the most straightforward approach.
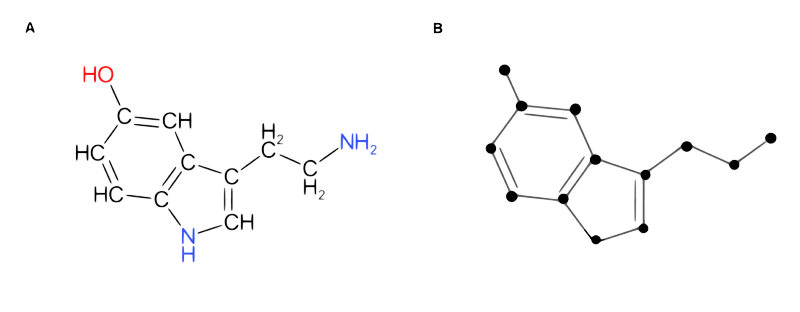
{kind=link}
We can see graphs like a collection of entities (Nodes) and the relationships between them (Edges). If there is a directional relationship between nodes the graph is called Directed, otherwise is called Undirected.

Mathematically we can define a graph with: $$G = (V, E)$$ Where V is the set of nodes, and E are the edges between them.
To simplify the notation, a graph can be also represented with an adjacency matrix \(A \), the elements of the matrix indicate whether pairs of nodes are adjacent or not in the graph.

Let \( x_i \in R^k \) be the feature vector of the node \( i \). We can stack all the feature vectors in a matrix $$X= (x_1, ..., x_n)^T $$ of shape \( n * k \) , where \( n \) is the dimension of the feature node and \( k \) is the number of nodes.
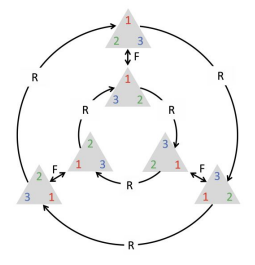
However, by doing this we are specifying a node ordering! This can cause a lot of problems because we need to process graph data independently of isomorphism. For example the following graphs are the same but they are arranged differently:
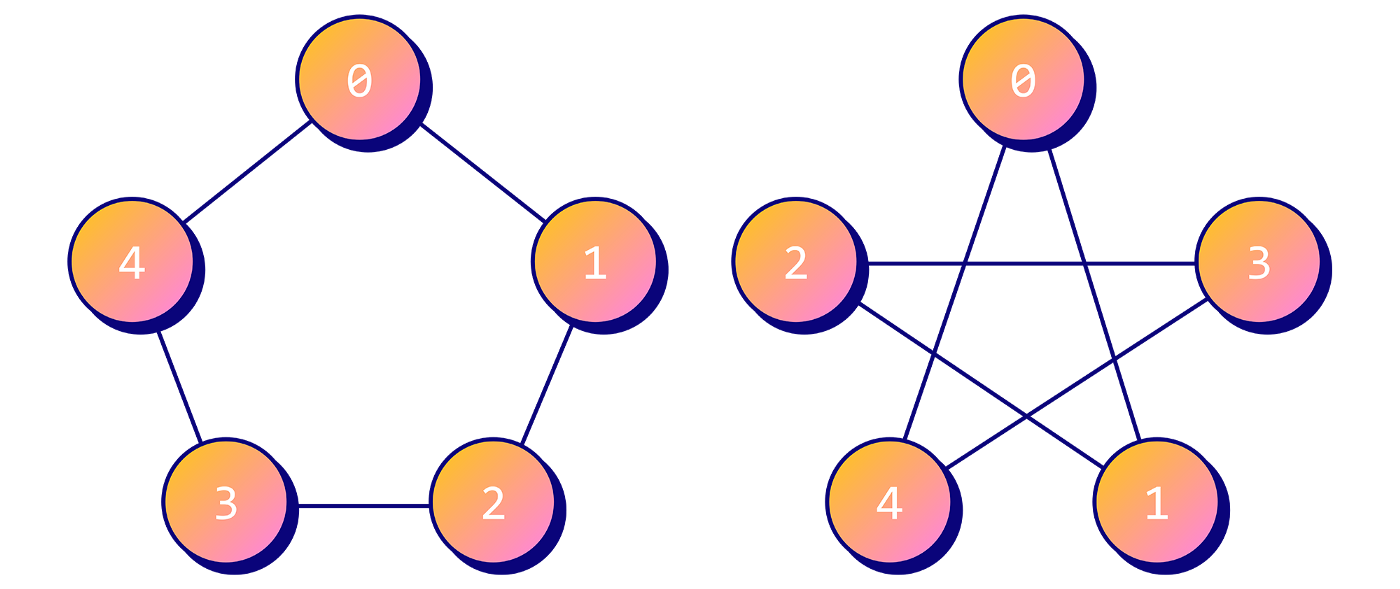
Let’s use the Geometric Deep Learning priors to simplify the problem by defining a class of functions (Graph Neural Networks) able to process graph data. What we want is a way to process graph data independently of node organization:
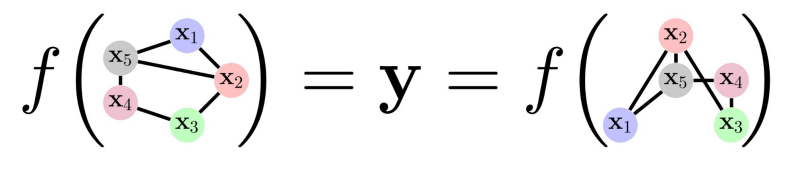
All the possible node combinations are defined by a mathematical operation called Permutation. Permutations are simply defined by a matrix \( P \) that can be left-multiplied to the feature matrix \( X \) or to the adjacency matrix \( A \).
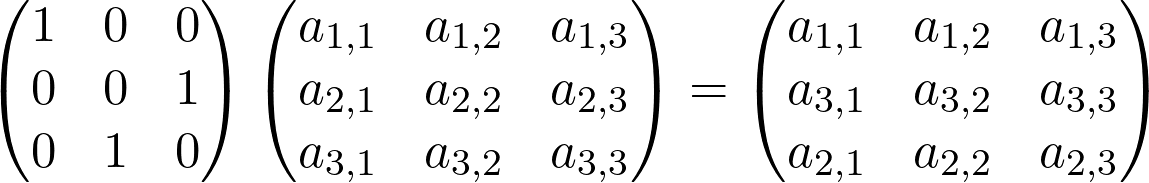
Given these definitions we can identify two main properties our function must respect:
- Permutation Invariance: applying permutations shouldn’t modify the result. In mathematical terms \( f(PX, PAP^T)=f(X, A) \)
- Permutation Equivariance: it doesn’t matter if we apply permutations before or after the function. \( f(PX, PAP^T)=Pf(X, A) \)
These two properties are directly correlated to the first Geometric Prior defined above. As we discussed before, we solved a similar problem in Convolutional Neural Networks (it doesn't matter if pixels are translated) by using Convolutions on pixels neighbours (more formally: using local equivariant processing layers).
It turned out that is possible to build the same permutation Invariant and Equivariant layers in GNNs considering node’s neighbourhoods! Convolutions at the end are multiplications followed by a sum, we can define similar operations introducing a function able to process groups of nodes neighbours.
Let’s define the set \( N_i \) of the neighbours of node \( i \) as \( X_Ni={x_j: j N_i} \). In this setting we can simply identify a function \( g \) able to process locally all the nodes:
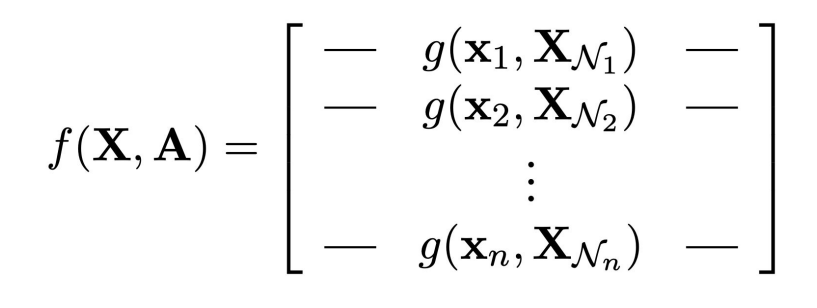
Let’s visualize how these mathematical definitions translate in graph processing. By considering the local neighbourhood of the node \( x_b \) is possible to create an hidden representation \( h_b \) using the aggregation function \( g(x_b, XN_b) \).
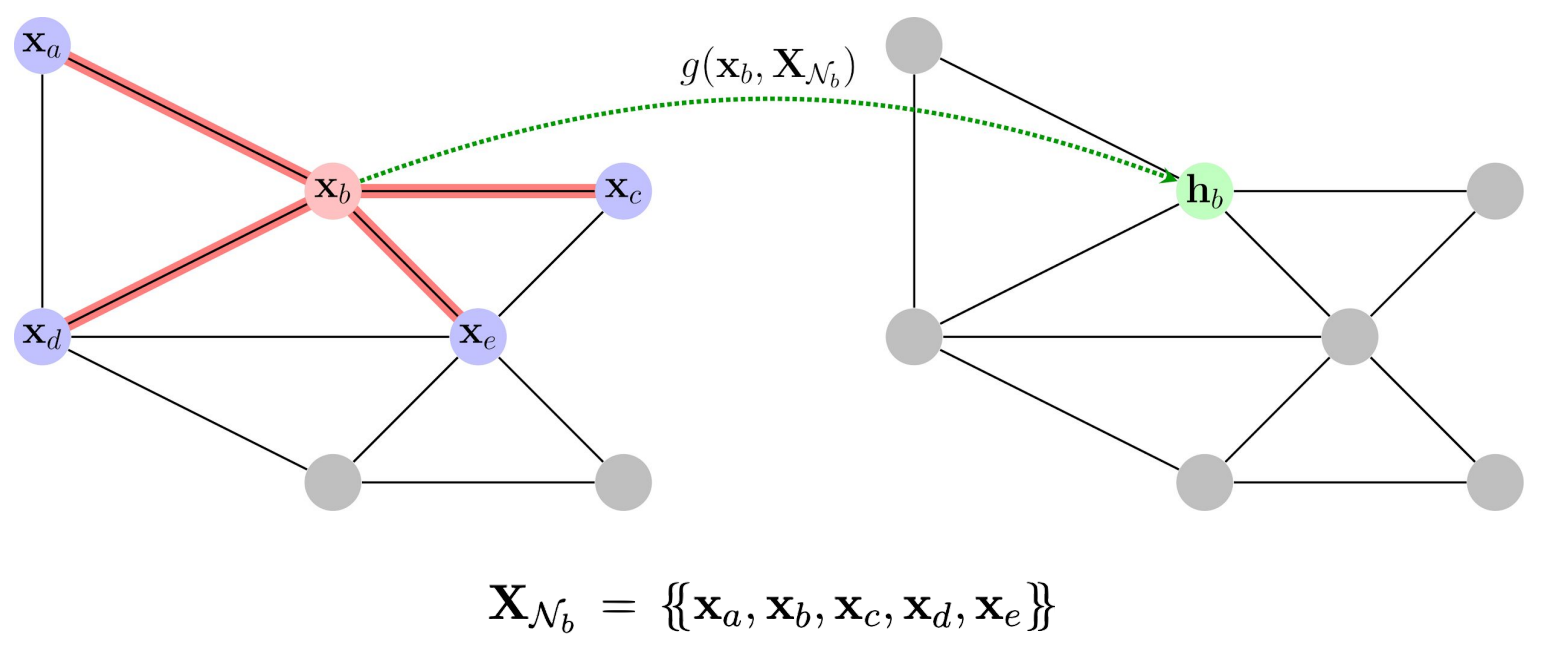
Deep Graph Neural Networks are built by stacking multiple of these layers! 🥳
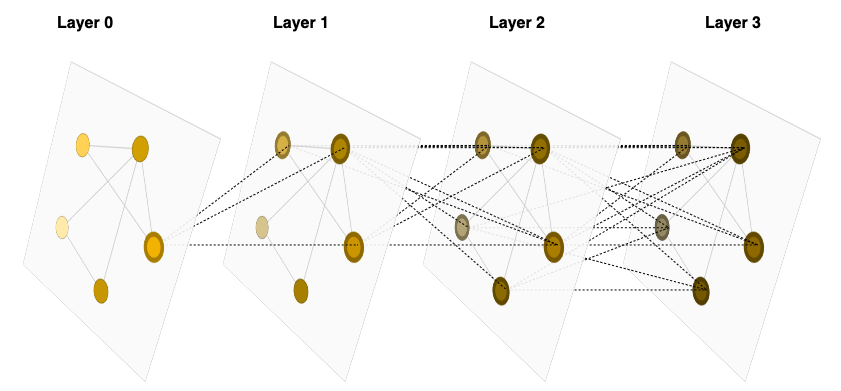
Using this blueprint is possible to train GNNs able to solve the following tasks:
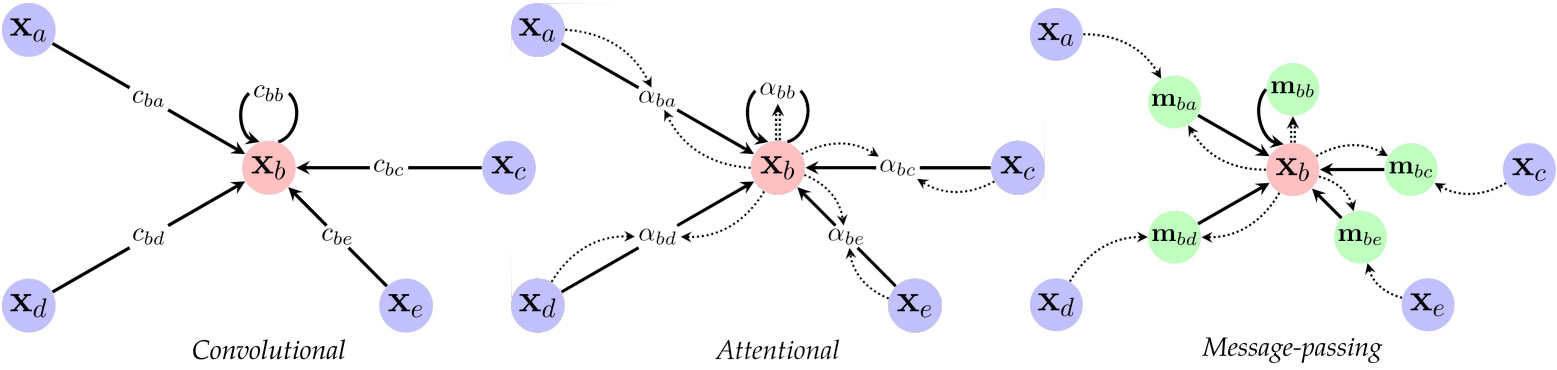
Defining how we compute the latent representations, using the aggregation function \( g \) (aka the hidden layers) we can have different flavours of GNNs:
- Convolutional GNNs: they use the neighbours to compute the hidden representation of the current node. Using this approach is possible to mock CNNs by computing localized convolutions.
- Attentional GNNs: they use a self attention mechanism similar to Transformer models to learn weights between each couple of connected nodes.
- Message passing GNNs: they propagate node features by exchanging information between adjacent nodes.
But wait! ... This is only an introduction on GNNs. We will go in more detail in one of the following articles! Don't forget to check our blog regularly 🥳
The main takeaway here can be summarized with this quote (which I couldn't find the original author):
Data has shape, and shape has a meaning
In traditional ML shape is usually lost in data representation, Geometric Deep learning tells us that we can leverage the power of DL models by considering the geometrical properties of the input data domain.
Conclusions
In this small article we saw that it is possible to generalize modern Deep Learning architectures to learn in all possible data domains by considering the underlying data Geometric Structure.
We saw how Geometric Deep Learning can help formalize the properties our Neural Network must follow in order to exploit the geometry of input data.
We finished the article discussing the Geometric Deep Learning principles applied in the most common non-Euclidean Deep Learning model: Graph Neural Networks.
Main references
A big thanks to professor Michael M. Bronstein and his team.
Useful links: