

By Stijn Dolphen
Edge computing is one of the recent buzzwords in Artificial Intelligence and - according to Gartner - it even has the potential to reach mainstream adoption in two to five years, with transformational business benefits as a result. How are these so-called marginal calculations creating additional value at the edges of a network instead of the centralized server location - or even an infinite pool of cloud resources? Let’s find out.
Setting the scene.
The integration of cutting-edge technologies like IoT, Cloud computing and Artificial Intelligence are transforming the way Industry 4.0 companies operate, from production to distribution.
Introducing analytics and decision making at the lowest level of the operational flow creates a need for an infrastructure where everything is connected and monitored. This also highlights the requirement for smaller packaged models and edge compute capabilities, enabling quick and efficient processing of data at the source for real-time decision making.
Cloud computing is a widely used foundation for this IoT infrastructure where there is as little human intervention needed as possible, replacing them with interconnections and communication between machines and devices. You could even compare Cloud computing to what electricity was to the 2nd industrial revolution - a catalyst.
Every network has its nodes, in this case it can either be a device performing a value-adding action, a sensor that captures useful information - as well as both. Data-capturing nodes contribute to the network by providing the ability to collect and transmit data from industrial systems and machines in real-time. This data can then in turn be used to optimize production processes, reduce downtime and perform actions based on AI predictions or detections.
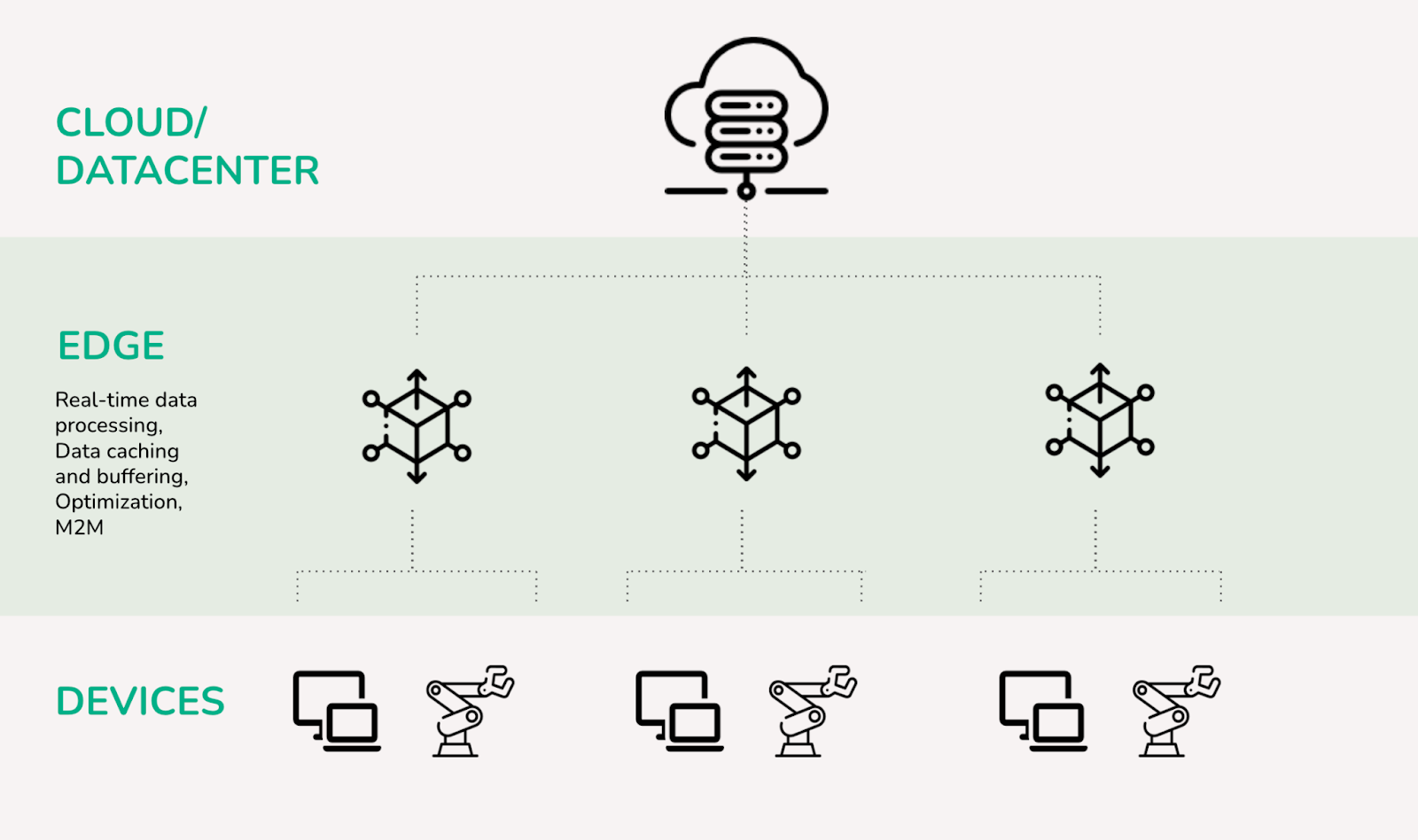
However, leveraging cloud networks also has its limitations in certain environments. Let’s discover how the edge computing layer can be an alternative to cloud. First, the use of cloud-based services requires a reliable and high-speed internet connection. Any interruption or slowdown in the connection can therefore cause problems. In some situations you can just not allow this to happen.
Second, data is being transmitted over this internet connection, setting the time it takes for the data to be processed or used by the next application. Next to the physical distance between the user and the cloud server, possible network congestion or bandwidth constraints, the amount of data that is being transferred also has a significant impact - making big data transfers to a centralized server location sometimes inefficient in terms of latency.
Imagine a sensor device capturing temperature data and sending that data to the cloud as an input for AI models to classify or detect a risk - in turn sending that information to an action-performing node to trigger an alarm. Whether the action-performing device is a tablet enabling human intervention, or an automated machine flow intervening - it’s all about speed and reliability.
Processing data at the source - or in this case the edge - can lead to faster analysis and actions, making it ideal for time-sensitive applications like real-time control and monitoring. A real-time control system can be a self-driving car for example, receiving sensor data in real-time and immediately using it to make decisions about acceleration, braking, and steering. The control system must be quick and precise in responding to any changes in the car's surroundings to ensure the safety of passengers and other vehicles on the road.
Moreover, you want this capability to be consistent - even in low-connectivity zones. Self-driving cars also rely on cloud-based services such as mapping, traffic data, and real-time updates to navigate. Low connectivity can disrupt the communication with these services and can lead to the car not having access to the most up-to-date information. Edge computing is able to reduce this dependency by processing sensors locally, rather than relying on a remote server.

This famous quote from ‘Gone with the Wind’ could be your first reaction to how this technology benefits self-driving cars. However, these advantages can be applied in different industries as well. Let’s go back to our example of a manufacturing chain where one particular sensor needs to capture temperature and make a decision based on that information.
In a fast-paced industry, as is the case for the manufacturing sector, every millisecond counts. Shortening the physical distance the data has to travel during the data transfer results in faster response times and therefore lower latency. The same can be said for the reliability of the system for avoiding outages and bottlenecks in the production process.
In addition, the ability to handle low-connectivity gives you an opportunity to increase your security. If there is a connection in place, incoming data might have been hacked and an altered decision can enter the system - causing a security breach. By processing data at the edge, near where it is generated, you can keep data locally, thus out of the reach of potential attackers.
Finally, storing and transferring the data in the cloud may also create additional charges - and these charges can sometimes be difficult to predict. Cloud service providers may charge based on the amount of data transferred, which can lead to unexpected costs if data transfer usage is higher than expected. Additionally, there may be fees for extra services or features, such as increased security measures or data backup, that can also add to the overall cost. As a result, it's important for organizations to carefully consider the costs of cloud computing and to factor in any potential hidden costs when making decisions about their infrastructure.
In summary, edge computing allows for more efficient and reliable processing of data, as it enables devices at the edge of the network to handle certain tasks without having to send all the data to the cloud. Furthermore, edge computing enables organizations to tailor their computing infrastructure to meet the specific needs of each application and use case. This results in quick and cost-effective processing of data, as it eliminates the need for large and expensive data transfers that may not be optimized for the specific needs of each use case. Finally, if decision-making can be done at the edge level, it would also require less storage for data collection and a smaller carbon footprint associated with it. Although the latter is still an interesting point of discussion for the future.
You might also like



