

By Tim Leers
eXplainable AI or XAI is crucial to ensure stakeholder and public trust, as well as reliability, particularly in high-stake contexts where AI decisions can impact lives.
Open-source contributors, researchers & companies are stepping up their game by providing ever-more ambitious and inventive methods to ensure transparent, interpretable and ultimately, explainable AI. As a consequence, XAI methods are sprouting up like mushrooms, meaning that the decision on which method to use is becoming increasingly complicated.
With great new open-source initiatives and many more start-ups making it their founding mission to cover some or multiple aspects of model & data reliability, explainability and monitoring, combined with the increasing awareness of biases and gaps in existing explainability methods, it can be somewhat overwhelming to keep track of all the new approaches and address explainability and interpretation in a high-stakes, high-paced business context.
Rather than loop you through existing XAI methods, we want to take you on a tour of what's yet to come. We'd like to show you our selection of XAI highlights from NeurIPS 2021 that promise to be gamechangers.
Human-in-the-loop XAI
At NeurIPS 2021 alone, we saw a huge number of promising, novel application methods relying on learning from supervision, and especially interactive learning with humans in the loop, to tackle existing shortcomings in XAI.
Human-advisable reinforcement learning with visual feedback
EXPAND is a significantly more powerful technique to integrate human feedback for data augmentation compared to other SOTA explanatory interactive learning methods. EXPAND achieves this by leveraging a powerful symbolic lingua franca (shared vocabulary) to bridge the human-AI communication gap: Instead of numerical label feedback, humans provide visual feedback by drawing bounding boxes on salient areas of the image which allows the AI agent to integrate human knowledge.

At the current time, reinforcement learning agents are oftentimes very costly to train. EXPAND promises to enable the integration of visual rather than numerical feedback which is much more informative and thus sample-effective, enabling us to train RL agents faster, better and cheaper.
Data quality & interactive learning with suspicious labels & maximally informative counterexamples
Faulty labels are a pervasive issue that can significantly impact the ultimate performance and useability of AI-driven solutions.

CINCER, is a new data cleaning method which re-examines label noise using sequential learning and a human-in-the-loop to optimize existing label cleaning methods and cover some of their drawbacks.

Specifically, CINCER selects mislabeled samples and presents it to a human for rellabelling. It's core mechanism is centered around identifying "suspicious" samples and selecting an appropriate counterexample which should maximally clarify that either the suspicious sample, or the counterexample, is mislabelled.

The authors of CINCER [1] described well what the method does better than its competitors:
CINCER identifies the reasons behind the model’s skepticism and asks the supervisor to double-check them too. Like most interactive approaches, there is a risk that CINCER annoys the user by asking an excessive number of questions. This is mitigated by querying the user only when the model is confident enough in its own predictions and by selecting influential counter-examples that have a high chance to improve the model upon relabeling, thus reducing the future chance of pointless queries.
Novel methods in post-hoc XAI
These approaches lend themselves well to nearly any application domain, data modality or model type. However, their generalizability means their contribution to XAI is usually more limited to transparency, and at best interpretability, for all stakeholders, and explainability only to developers and domain experts.
InputIBA - Information Bottleneck Attribution revised

Feature attributions indicate how much each feature in your current data instance contributed to the final prediction. In the image domain, that can translate to showing the extent to which each pixel contributes.
Feature attribution methods were already extensively applied in the past, but InputIBA uses a novel approach based on information bottleneck attribution (IBA) that enables a much more robust approach in the image domain:

As well as in the language domain, for example by identifying informative words & symbols, enabling increased human interpretability:

SimplEx - Leveraging latent explanations of black-box models using examples
SimplEx elegantly combines feature explanation techniques and example-based techniques, tying together two powerful XAI frameworks.
The most common approach to provide example-based explanations for a wide variety of models mirrors feature importance methods. The idea is to complement the model prediction by attributing a score to each training example. This score reflects the importance of each training example for the model to issue its prediction. [5]
In the image below, our model classified the left-most image as a three. On the right, we can see what examples in our corpus (a representative dataset composed by the human user) were most important for the model prediction. The scores represent the extent of the importance. What's different, compared to traditional example-based methods, is that each image also shows the importance of each pixel (from red to green, with dark-green representing most important).
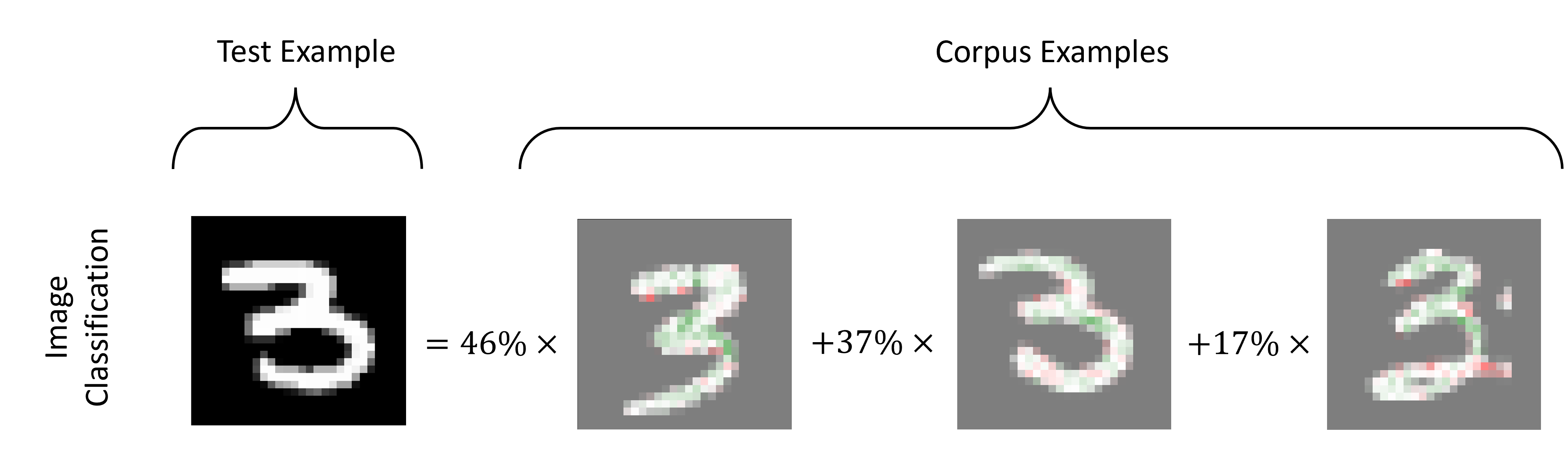
In a more traditional machine learning context utilizing tabular data, SimplEx both provides individual examples from its corpus, and provides the importance of each feature in that example.

What does SimplEx provide compared to its contemporary counterparts? What makes it so revolutionary? We cannot put it any more succintly or appropriately than the authors themselves [5]:
(1) SimplEx gives the user freedom to choose the corpus of examples whom with the model’s predictions are decomposed. (...) there is no need for this corpus of examples to be equal to the model’s training set.
This is particularly interesting for two reasons:
(a) the training set of a model is not always accessible
(b) the user might want explanations in terms of examples that make sense for them.
For instance, a doctor might want to understand the predictions of a risk model in terms of patients they know.
(2) The decompositions of SimplEx are valid, both in latent and output space. (...) SimplEx offer significantly more precision and robustness than previous methods (...)
(3) SimplEx details the role played by each feature in the corpus mixture. (...) This creates a bridge between two research directions that have mostly developed independently: feature importance and example-based explanations
Uncertainty quantification of XAI methods
Existing explainability methods are being rightfully re-examined and improved, especially using uncertainty quantification. In industry, feature importance and similar metrics (typically based on Shapley or LIME) are frequently used uncritically to assess model reliability and establish a high-level interpretation that can be communicated to stakeholders. By allowing developers and users to assess the uncertainty of such methods, we can, to some extent, mitigate their shortcomings.
Uncertainty estimation for feature importance methods such as LIME or Shapley
In many cases the uncertainty of existing feature importance methods were not or incorrectly reported, which may inflate confidence in a model that provides erroneous predictions.
In Reliable Post hoc Explanations: Modeling Uncertainty in Explainability [6], this issue is being tackled. Instead of providing a point estimate of the feature importance, a distribution is estimated instead:

Distributional reasoning about feature importances opens up much more advanced approaches or at the very least rightfully portrays the inherent uncertainty in estimating feature importances, and hopefully provides some protection from using them uncritically for making important decisions.
Uncertainty estimation for neural networks by bootstrapping
NeuBoots [7] can be used for bootstrapping neural networks and as such deriving uncertainty metrics enabling the usage of conventional statistical uncertainty measures (e.g. confidence intervals).
Bootstrapping, in a nutshell, means that we fit a model multiple times, while re-sampling the data in a statistically rigorous manner to assess the resultant variability in our model parameters and/or predictions.
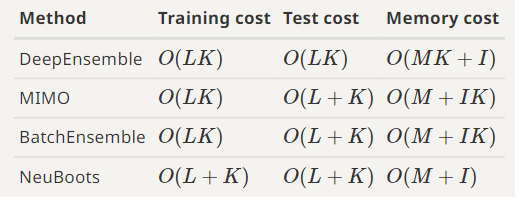
In statistics, bootstrapping is a reliable approach for parameter estimation, especially when no closed form solution exists. Unfortunately, in the context of deep learning, bootstrapping is oftentimes too computationally complex. Bootstrapping neural networks can be approximated by using ensemble methods, but NeuBoots is more efficient:
NeuBoots is comparable to a standard bootstrap at estimating confidence intervals in the context of neural networks:
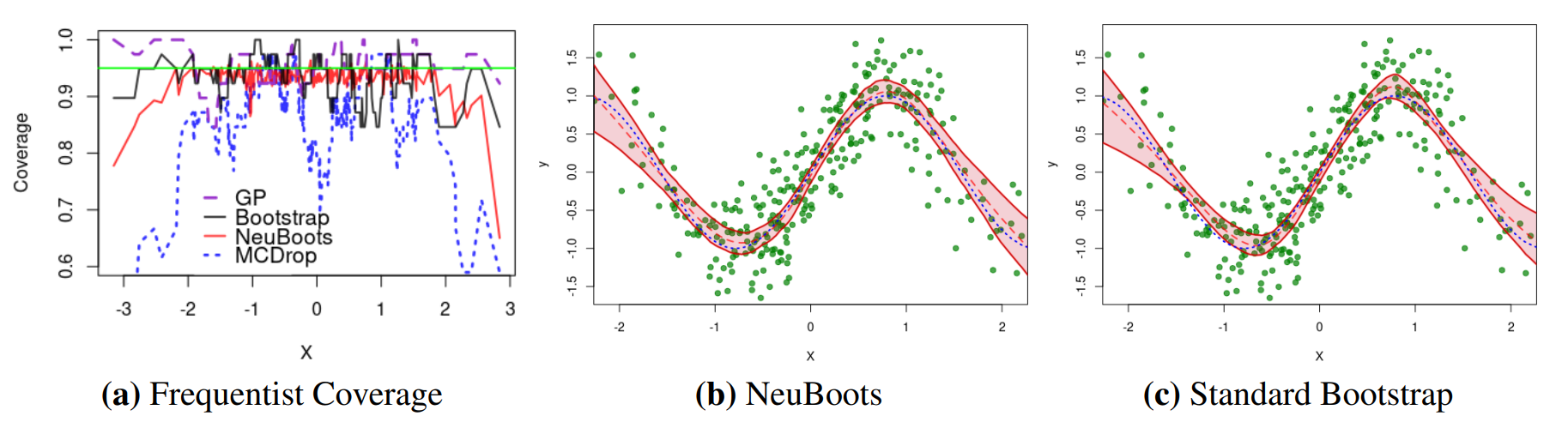
(And of course, it is much more efficient. For the above comparison, the authors had to train 1000 neural networks, whereas the NeuBoots algorithm evaluates the network only once.)
Moreover, NeuBoots can be efficiently used for prediction calibration. In image classification, the probabilities of a particular class being present in an image are rarely representative of the actual confidence in that classification. Given that these models are often optimized for top-1 or top-5 accuracy, the internal representation of the layers is not necessarily optimized to represent the likelihood of other classes outside of that top 1 or top 5. In a way, NeuBoots enables AI to put its money where its mouth is: When the model outputs 90% confidence, it expects to be correct 90% of the time.
In conclusion, NeuBoots promises to be computationally efficient, scaleable approach to bootstrapping and uncertainty estimation that can be applied to many different types of neural networks. There's many more interesting functionalities in the context of XAI enabled by the power of uncertainty estimation, but for a complete overview, we recommend you have a look at the paper.
Want to know more about these new approaches? Did we miss an important method? Let us know and we may just dedicate a post to it!
Confused about what method to use for your usecase? Contact us to see if we can help you out.
Stay tuned for more posts to come: subscribe to our RSS feed and our LinkedIn page.
At dataroots research we'll be exploring what methods are crucial for enabling the continuity of services in the face of upcoming AI regulations, and translating academic output to industry-ready XAI tooling to accelerate integration into your business processes.
References
[1] CINCER: Teso, S., Bontempelli, A., Giunchiglia, F., & Passerini, A. (2021). Interactive Label Cleaning with Example-based Explanations. arXiv preprint arXiv:2106.03922.
[2] InputIBA: Zhang, Y., Khakzar, A., Li, Y., Farshad, A., Kim, S. T., & Navab, N. (2021). Fine-Grained Neural Network Explanation by Identifying Input Features with Predictive Information. Advances in Neural Information Processing Systems, 34. arXiv preprint arXiv:2110.01471
[3] InputIBA - Open Review: https://openreview.net/forum?id=HglgPZAYhcG
[4] Simplex - Open Review: https://openreview.net/forum?id=PIcuKeiWvj-
[5] SimplEx: Crabbé, J., Qian, Z., Imrie, F., & van der Schaar, M. (2021). Explaining Latent Representations with a Corpus of Examples. Advances in Neural Information Processing Systems, 34. arXiv prepint arXiv:2110.15355
[6] Slack, D., Hilgard, A., Singh, S., & Lakkaraju, H. (2021). Reliable post hoc explanations: Modeling uncertainty in explainability. Advances in Neural Information Processing Systems, 34. arXiv preprint arXiv:2008.05030
[7] NeuBoots: Shin, M., Cho, H., Min, H. S., & Lim, S. (2021). Neural Bootstrapper. Advances in Neural Information Processing Systems, 34. arXiv preprint arXiv:2010.01051
[8] On Probability Calibration and Overconfidence in Image Classification (2019), by Jonathan Wenger: https://jonathanwenger.netlify.app/project/uncertainty_representation/