

By GUPPI
Recently, Microsoft released VALL-E, a revolutionary new language model for text-to-speech (TTS) designed to significantly outperform other state-of-the-art zero-shot TTS models in terms of both speech naturalness and speaker similarity. VALL-E requires nothing more than a 3-second speech recording from a previously unseen speaker to synthesize high-quality speech.
However, unfortunately, VALL-E is not yet available to the public and since the model is trained solely on English data, it will not be able to generate speech in other languages, such as Dutch.
One obvious use case for these TTS models is to read aloud news articles, blog posts, websites etc. This will advance inclusivity and accessibility of written content by providing easy access to this digital content for the visually impaired or for an audience with language proficiency issues. Additionally, TTS can increase convenience by enabling users to listen to the content on-the-go. Furthermore, TTS can also be used in other industries such as automotive (car navigation), customer service (automated responses), language learning, audio-based entertainment and much more.
Given the numerous use cases and the many benefits, it would be interesting to create our own custom voice in Flemish Dutch. This would allow us to tailor the voice to the specific needs and preferences of our audience.
Problem statement
Since Dutch, and more specifically the Flemish variant of Dutch, is not so widely spoken such as major languages like English, we see that there are fewer resources available, potentially leading to less coverage and a lower quality of generated speech for this language.
As most state-of-the-art research focuses on the English language, we see many more open source English audio datasets as well as openly available pretrained English models being published.
While there are generic Dutch voices (even Flemish) readily available on most cloud providers (such as Azure, AWS, GCP), these are not customized and hence not tailored to the specific preferences of the audience. Furthermore, training a custom neural voice on these cloud providers could quickly become quite expensive.
Given these reasons, we explored the alternative of training a custom TTS model ourselves. Furthermore, since the most commonly used evaluation metric for speech quality, namely the mean opinion score (MOS) which essentially is a crowd-sourced metric where humans evaluate the speech quality, is inherently subjective, we researched methods for quantifying TTS model performance and associated speech quality.
Text-to-speech: an overview
The most intuitive (and straightforward) way of doing text-to-speech is to break down the text and the corresponding audio into smaller units (phonemes for instance) and to then concatenate these short audio samples to form a word and to pronounce sentences. However, this approach does not generate natural-sounding speech as it is often lacking intonation and emotion.
Fortunately, text-to-speech has come a long way since this naive approach. Currently, deep learning methods dominate the text-to-speech field and are becoming increasingly better and more natural sounding.
These TTS deep learning techniques often consist of two stages: the first stage will train an acoustic model that will learn to convert the input text into a mel spectrogram. In simple terms, a mel spectrogram is a visual representation of audio data that shows how the frequencies of the sound change over time. It shows different frequencies on the y-axis, and the color represents the amplitude of the sound at each frequency at each point in time. These predicted mel spectrograms are fed to a neural vocoder to be translated into waveforms (stage 2).
Recently, new text-to-speech models became available that do not need the neural vocoder part to synthesize the speed. These models will directly generate waveforms without requiring the intermediate mel spectrogram representation fed into a neural vocoder.
Our approach
To train a Flemish TTS model, we used Google’s Tacotron2 model (NVIDIA implementation) as the acoustic model. Tacotron2 is composed of an encoder and decoder network with an attention mechanism aligning the text with the audio signals. We use NVIDIA’s Waveglow vocoder to synthesize the speech.
For this experiment, around 5 hours of data was recorded by a voice actor/director.
Additionally, an open source Flemish, male, single-speaker dataset was used to pretrain the model. It contains around 12 hours of Flemish audio data.
Before model training, some additional preprocessing steps must be taken to ensure that the audio conforms to the required format. Tacotron2 requires the audio files to be downsampled to 22050 Hz and to be in mono channel with all silences in the beginning and in the end removed. Furthermore, data should be in the following format:
AUDIO_PATH_2|TEXT_2
AUDIO_PATH_3|TEXT_3
Where “audio_path” refers to the path where that specific audio file can be found and “text” the associated transcripts.
Before training on our own recorded data, we pretrained the model on the open source dataset. We experimented with the number of epochs, learning rate annealing and since the open source voice has some kind of hoarseness within his voice that seemed to be amplified in the synthetic voice, we additionally experimented by training on denoised audio files.
Next, we trained on our own Flemish audio dataset. We started by training a model for 22k training steps with default hyperparameters using the best model trained on the open source data as a warm start. We furthermore experimented with different numbers of epochs, modified learning rates, post processing the output (denoising) and fine-tuning the Waveglow vocoder.
Evaluation
One of the most commonly used evaluation metrics in the TTS domain is the Mean Opinion Score (MOS). To calculate the MOS, a group of people are asked to rate the overall quality of the audio on a numerical scale based on various factors such as naturalness, fluency, intelligibility, pleasantness and such. The most commonly used scale is a 5-point scale, where 1 is the lowest rating (poor quality) and 5 is the highest rating (excellent quality).
Since we could not use such a crowd-sourced evaluation metric and since this method still remains inherently subjective, we had to look for other, more objective and quantitative ways.
Firstly, we looked at the Tensorboard logs of the validation loss of Tacotron2. However, we quickly discovered that already after the first 1000 training steps this loss stabilized or even increased despite there being noticeable audio improvements as we continued to train the model.
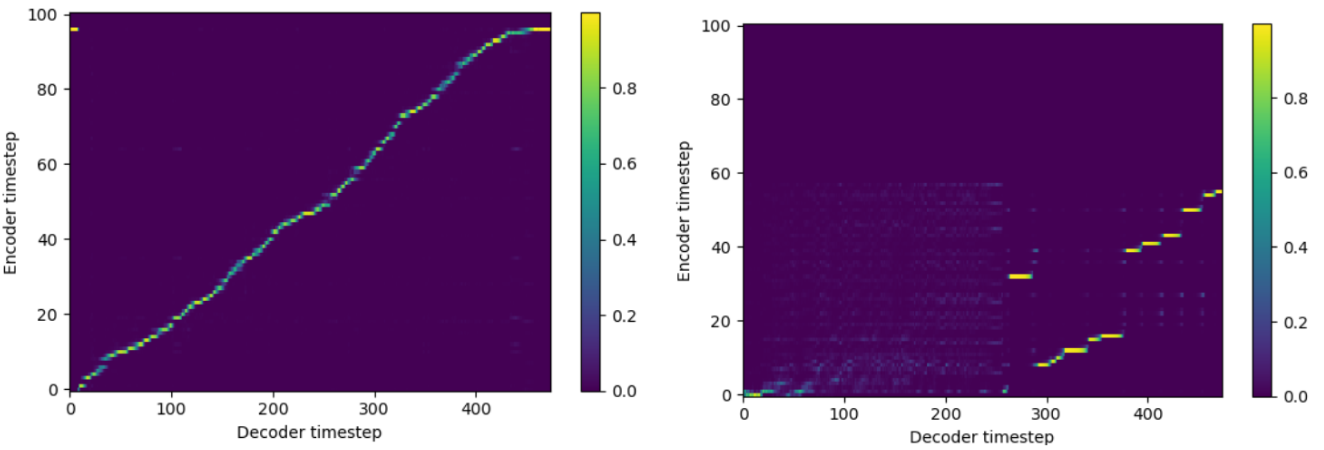
The loss function here is defined as the MSE loss between the predicted mel output (from the model) and mel target (from training data). Additionally, a postnet is used to further refine the mel spectrogram predictions and a MSE loss is also computed between the postnet predictions and the target mel spectrogram. The gate loss is related to predicting when the speech should stop. Furthermore, we could take a look at the alignment plots. If the alignment plot shows a diagonal line, it means that the model is accurately predicting the correct output at each time step: the alignment between input text and audio is good. Since we use the mel spectrograms as a big part of the loss and since even with poor alignment they look similar, this does not seem to be the best metric to evaluate the TTS output.
Alternatively, as we actually want to quantify how far off the synthesized audio is from the original audio, we first decided to embed the original wav files to a 512-dimensional embedding representation using Huggingface’s wav2vec, which captures the underlying characteristics of the audio, and use these embeddings as input dataset for NannyML’s data drift detection. NannyML hence will profile the original data embeddings and will then detect any differences or data drift between the original and the synthesized embeddings (generated from the test audios). The less data drift detected, the better the audio quality is considered to be. This approach allows us to quantify how closely the synthesized audio matches the original audio, providing a more objective measure of audio quality than the traditional MOS. Additionally, the data drift detection method with NannyML allows us to detect subtle changes in the audio that may not be obvious to human listeners, making it a more reliable approach to evaluate the performance of a TTS system.
Furthermore, the same analysis was repeated on the 256-dimensional Resemblyzer voice embeddings. Here, we had the choice to embed utterances (each audio embedded separately) or to embed a speaker (average all embeddings of that speaker and L2-normalize this). We tested both methods. The utterance embeddings were fed into NannyML where all original utterance embeddings were grouped as the train set and the experimental synthesized embeddings as test set. Moreover, we calculated the cosine similarity between the original speaker embedding and the experimental synthesized embedding to see which experiment delivered the most similar voice with respect to the original voice.
Results
We started with an initial experiment running 500 epochs with default hyperparameters with a warm start from the best model trained on the Flemish open source data. Initial results sounded already quite good: the synthesized speech had learned to pause before commas. This was made possible due to the fact that the training data contained longer sentences sometimes split by commas. Furthermore, as audio files were often longer, they could contain multiple sentences separated by a period. As a result, the model learned to mimic the pauses in human speech which led to a more natural-sounding synthesized audio.
Moreover, the voice was clearly recognizable as our training voice and similar intonation patterns were captured. Here as well, still, the voice sounds slightly hoarse. Additionally, not all words are correctly pronounced, certainly words derived from other languages (e.g. comité, medaille, mademoiselle), abbreviations (N-VA, Open VLD), some special vowels (België, knieën). This could be due to the limited size of train audio in which not all phonemes and sounds are recorded. Moreover, words derived from another language often differ in pronunciation from how they are typically pronounced in the Dutch language.This highlights the importance of having a diverse training dataset.
Following experiments were conducted and for each experiment 100 audio files were generated based on the textual input from the test set.
The analysis chunks represent following experiments:
- 500 epochs trained on our voice using default hyperparameters and warm start from the best open source model
- 100 additional epochs with lower learning rate of 10e-4 using the previous model as warm start
- 100 epochs on top of the previous model with a lower learning rate of 10e-5
- Checkpoint 1000 from initial model: first checkpoint of model training to see if further learning improved the quality of the synthesized speech
- Last checkpoint from first iteration with denoising as post processing (using the noisereduce Python library)
- 300 epochs directly trained on our voice with warm start from the English pretrained model (hence no Flemish open source pretraining)
- 100 epochs with an annealed learning rate of 10e-4 with a warm start from the 10k training steps model checkpoint
- Synthesized files from the open source voice. Used as a sanity check. Should always give the most drift due to the fact that it’s a completely different voice
Upon analyzing the multivariate drift plot of the wav2vec embeddings, we notice that the denoised synthesized audio files seem to be slightly superior to the other experiments (more in the middle between the two red dashed reference lines). This plot supports the observation that there is minimal difference in audio quality generated from the various experiments, with the exception of the last experiment which is the synthesized open source voice and should indeed be assigned the highest drift value.
However, although chunk 4, representing 1000 training steps, had a relatively similar drift value on the plot, it was noticed that further training resulted in improvements in audio quality. Specifically, in short sentences, we noticed a silence in the end, indicating that the prediction of when to terminate the speech was still imprecise. Additionally, in some cases, the generation of "alien language" was observed.
Moreover, the wav2vec embeddings were also visualized in 2 dimensions by applying PCA. The 2 PCA components used in the analysis explain 22% of the variance. We do this to observe whether a clear distinction between the embeddings can be spotted. Upon examination of the PCA plot, it was found that all experiments and the original embeddings overlapped, demonstrating that there were no large differences between the embeddings. This result concurs with the findings obtained from NannyML, which suggest that the experiments do not deviate significantly and that audio quality is relatively consistent across all experiments.


After rerunning the analysis with the Resemblyzer embeddings, we noticed that the results have slightly changed. Resemblyzer passes our sanity check by detecting by far the highest drift on the open source voice. In contrast to our initial analysis with wav2vec embeddings, which showed a slight preference for the denoised audio files, the Resemblyzer voice embeddings of the denoised audio files drift the most in comparison to the other synthesized audios. The first and second experiments did not drift, and thus were closest to the original voice according to this model. Interestingly, we noticed that the first and second experiment worked quite well according to the wav2vec embeddings too.

Let’s now look at the cosine similarity between the original speaker embedding and the synthesized ones. We visualize the scores in a heatmap.

We see that here too the open source voice gets the lowest similarity score. The denoised audio files don’t seem to score well either (experiment number 4). According to this method, experiment 2 is slightly better than the first two experiments, however, the difference is very small.
While analyzing the PCA visualization below, we notice that Resemblyzer does seem to be able to distinguish between the original embeddings (clustered more to the right as well) and the experimental embeddings. However, it is worth noting that the 2 principal components used in the analysis only explain 15.4% of the variance.

Fine-tuning the vocoder
As previously stated, current deep TTS methods are composed of two steps: training the acoustic model and synthesizing the speech using a neural vocoder. Initially, we focused on training the acoustic model. However, although the Waveglow vocoder is universal, which allows it to synthesize speech in every language or voice, fine-tuning the vocoder has the potential to yield better results. Consequently, the final experiment involved fine-tuning the vocoder for 25k training steps.
We evaluated the generated audio quality in the same manner as we did for the previous experiments. We consider the following experiments as benchmark to the newly generated audio using the fine tuned vocoder:
- 500 epochs trained on our voice using default hyperparameters and warm start from the best open source model
- 100 additional epochs with lower learning rate of 10e-4 using the previous model as warm start
- 100 epochs on top of the previous model with a lower learning rate of 10e-5
- Last checkpoint from first iteration with denoising as post processing
- Fine tuned Waveglow model for 25k steps synthesizing the output from the first experiment




Here again, the conclusions derived from the wav2vec and Resemblyzer embeddings disagree. The wav2vec embeddings suggest that fine-tuning the vocoder led to a decline in audio quality as it for the first time caused drift. In contrast, the Resemblyzer embeddings indicate that fine-tuning the vocoder raised the audio quality as evidenced by the highest cosine similarity value and the PCA reconstruction error of NannyML's multivariate drift detector being well within the acceptable range. Listening to the synthesized input after fine-tuning the vocoder, although a subjective evaluation method, shows a reduction in noise/hoarseness in the synthetically generated voice.
It appears that somehow Resemblyzer’s embeddings are able to capture more detailed and nuanced variations in voice characteristics, as evidenced by the multivariate drift detector’s capability to detect drift using these embeddings, whereas no signs of drift were observed in the wav2vec embeddings.
Furthermore, the PCA visualizations demonstrate that a clear separation between the original and synthesized Resemblyzer embeddings can be found. In contrast, the synthesized wav2vec embeddings and the original embeddings overlap, suggesting that this model cannot clearly distinguish between the original embeddings and the synthesized ones. This demonstrates that Resemblyzer is more sensitive to subtle differences and hence is able to discern when the audio is synthesized, whereas wav2vec can only capture the high-level characteristics ultimately leading to the embeddings failing to sufficiently capture the dissimilarities between the original and synthetic voice.
Next steps
The initial results of our custom voice were already quite good. As seen on the NannyML drift detection plots, some synthetic voices did not even give drift. However, our voice remains still far from perfect. As mentioned above, we still hear some mispronunciations, certainly loanwords adopted from a foreign language, but also certain phoneme combinations and abbreviations are not always pronounced correctly.
As a consequence, we believe we could further improve on our results by training on more high-quality audio data and also ensuring that the data contains the most important phoneme combinations. It should also cover the common words and phrases most likely to be used in your specific use case, such as domain-specific words or acronyms. For instance, if your use case is about generating speech for political texts, then it would be beneficial to fine-tune on more politically-oriented data.
Moreover, since there might be discrepancies between the recorded speech and the associated transcripts due to human errors, a speech-to-text model could be run first to detect these errors and raise the quality of the transcripts.
Thirdly, more thorough experimentation with different model architectures and hyperparameter tuning could boost the results. Since TTS models are continuously being improved upon and more complex models and techniques are being developed, synthesized audio quality will in the future progress even further.
Finally, leveraging advanced post processing techniques such as pitch shifting, formant shifting, adding a small amount of background noise or correcting the duration of the generated speech might ameliorate the synthesized voices as well.
Conclusion
Text-to-speech has many applications that are becoming increasingly more important in today’s society. Despite the growing importance of TTS, the majority of research still focuses on the English language, leading to the development of many pretrained English TTS models. However, since Flemish Dutch is an important language in Belgium and since this language is less prevalent than for instance English, we see fewer openly available pretrained models in this language. This led us to training a Flemish TTS model on our own audio recordings using the Tacotron2 model. Additionally, to quantify synthesized speech quality, we generated vector embeddings for the original train audios to capture voice characteristics and used NannyML to profile this training set. Finally drift detection was run on the synthesized voice embeddings from all experiments.
Initial results already showed great potential, but there is still room for improvement. Despite this, we do believe that this is already a good first step to create a custom Flemish voice and it opens up many opportunities to further advance the generated audio quality by for instance increasing the dataset size and diversity, fine-tuning on domain-specific data and experimenting with different new architectures and techniques.
Resources:
- https://towardsdatascience.com/text-to-speech-lifelike-speech-synthesis-demo-part-1-f991ffe9e41e
- https://theaisummer.com/text-to-speech/#speech-synthesis-with-deep-learning
- https://towardsdatascience.com/text-to-speech-one-small-step-by-mankind-to-create-lifelike-robots-54e19f843b21#:~:text=In%20concatenative%20text%2Dto%2Dspeech,to%20form%20a%20complete%20speech.
- https://medium.com/sciforce/text-to-speech-synthesis-an-overview-641c18fcd35f
- https://towardsdatascience.com/all-you-need-to-know-to-start-speech-processing-with-deep-learning-102c916edf62