

By Niels Baptist
When getting introduced to new data, there is always a learning curve in which we need time to explore the data before feeling comfortable and confident about our understanding of it. In this blogpost we’ll go over the different ways we can make this easier. We’ll compare 2 famous tools that can be used to speed up and simplify this step:
- Pandas Profiler
- Sweet viz
For both tools, we will use the same nba_players dataset from Kaggle.
Pandas Profiler
Pandas Profiler is an open-source Python package that generates comprehensive and interactive data profiling reports from a pandas DataFrame. It helps in understanding the data better by providing summary statistics, visualizations, correlations, missing value patterns, and other useful insights. To use Pandas Profiler, follow these steps:
Setup
- Install the package: If you haven't installed Pandas Profiler yet, you can do so using pip:
%pip install pandas_profiling - Import required libraries: Once installed, import Pandas and Pandas Profiler into your Python script or Jupyter Notebook:
import pandas as pd
from pandas_profiling import ProfileReport- Load your dataset: Read your dataset into a pandas DataFrame. For example, if you have a CSV file, you can load it as follows:
df = pd.read_csv('../data/nba_players.csv')- Generate the profile report: Create a profile report from the DataFrame using the
ProfileReportfunction. In this example we are writing the report to an .html file. You can also configure the report with various options to include or exclude certain visualisations.
# Generate the report
profile = ProfileReport(df, title='NBA Players')
# To save the report to a file
profile.to_file('../profiles/nba_players_pandas_profiler.html')
# To show the report in the notebook
profileResults
Let's have a look at what it generated for us!
In the PDF you'll find 3 tabs with various visualisations and statistics, let's go over them.
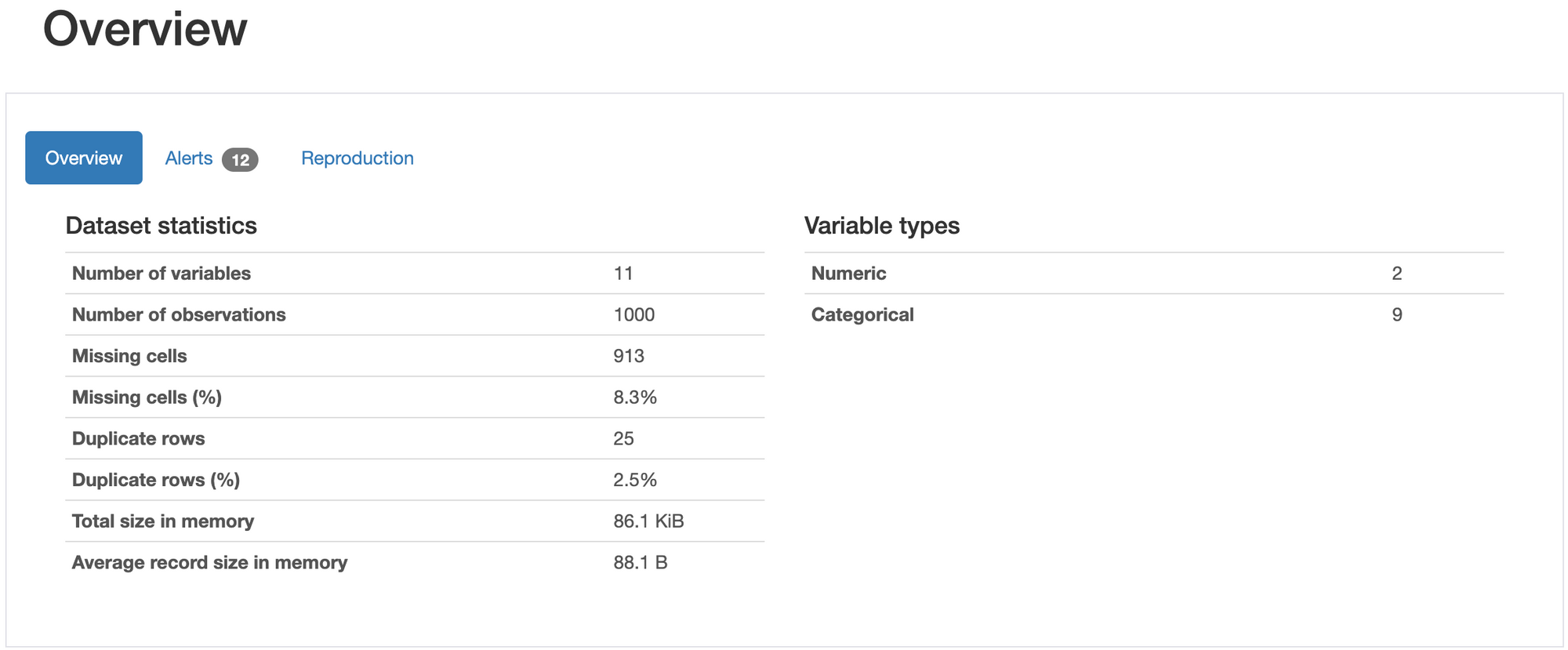
In a Pandas Profiler report, the overview section offers a high-level snapshot of your dataset, allowing you to quickly grasp its characteristics. It reveals the total number of columns (or features) and rows (or data points) in your dataset. Additionally, it provides insights into missing values by displaying the total count and percentage of missing cells across all columns.
The overview section also highlights the presence of duplicate rows in the dataset, showing both the total count and the percentage in relation to the overall number of rows. Furthermore, it gives you an idea of the memory footprint of your dataset by showing the total size it occupies in memory.
Lastly, the overview section sheds light on the distribution of variable types in your dataset, such as numerical, categorical, and boolean data types. With this information, you can quickly assess the structure, completeness, and potential issues in your data, making it easier to plan and execute the data preprocessing and analysis stages.
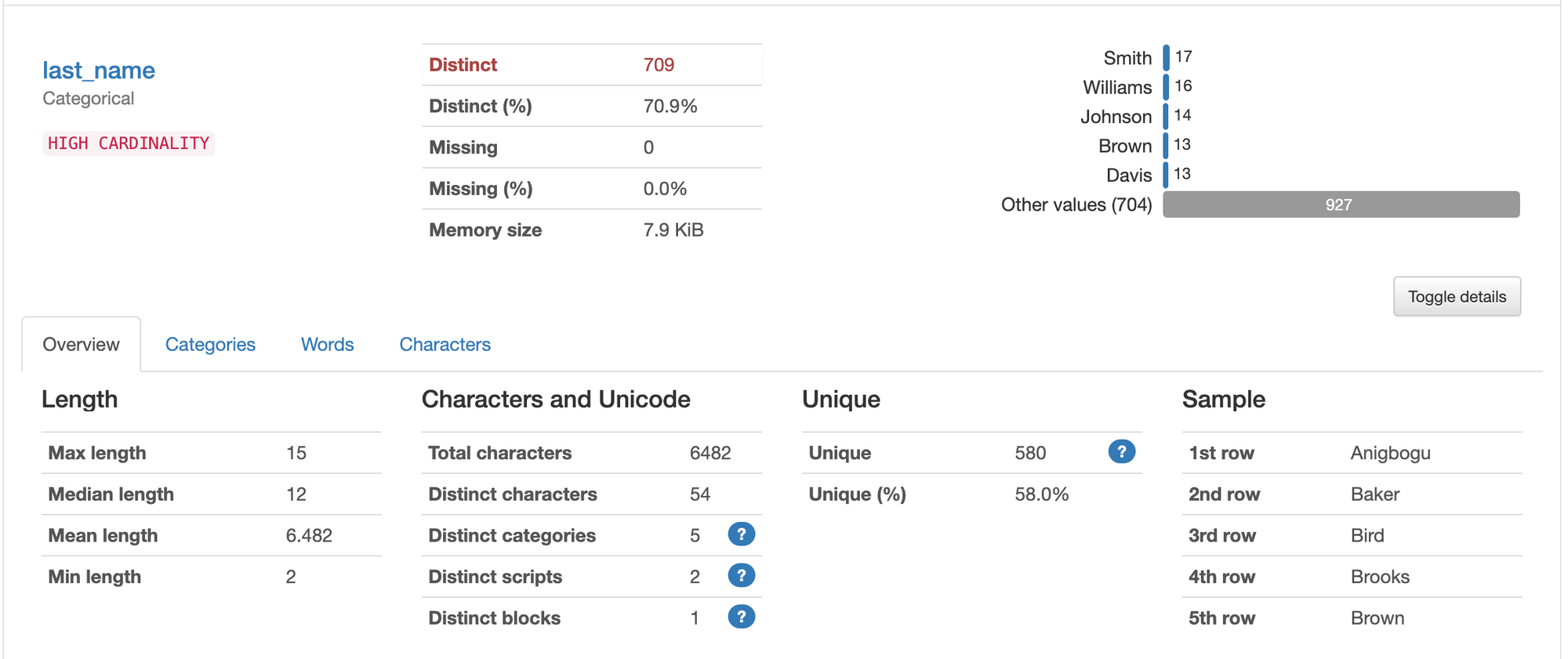
In addition to the high-level summary, the overview section features a detailed table for each variable in the dataset. For each variable, the table provides its name and data type, such as integers, floats, objects, or booleans. It also delves into missing values, showing both the count and percentage of missing values for each variable. This helps you assess the completeness of individual columns in the dataset.
Moreover, the table displays the number of unique values for each variable, which can be particularly useful in identifying categorical columns or detecting potential outliers. Finally, the table shows the inferred data type, which is an estimation of the variable's nature based on its contents, such as categorical or numerical.
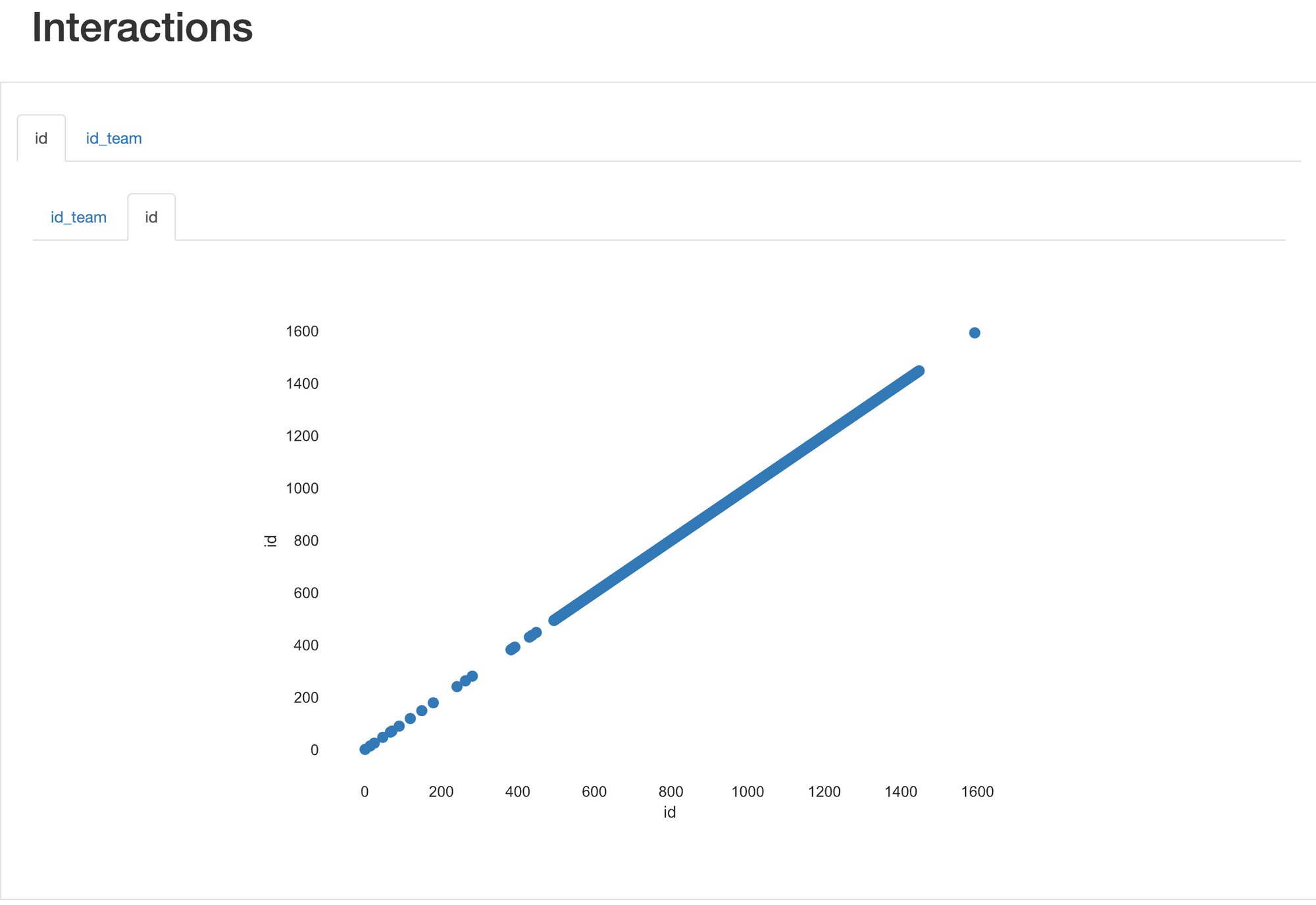
The interactions visualization displays pairwise scatter plots, which can be useful for identifying relationships and interactions between variables. However, in our dataset with only two numerical variables, this visualization may not be as relevant or informative, as there are limited interactions to explore.
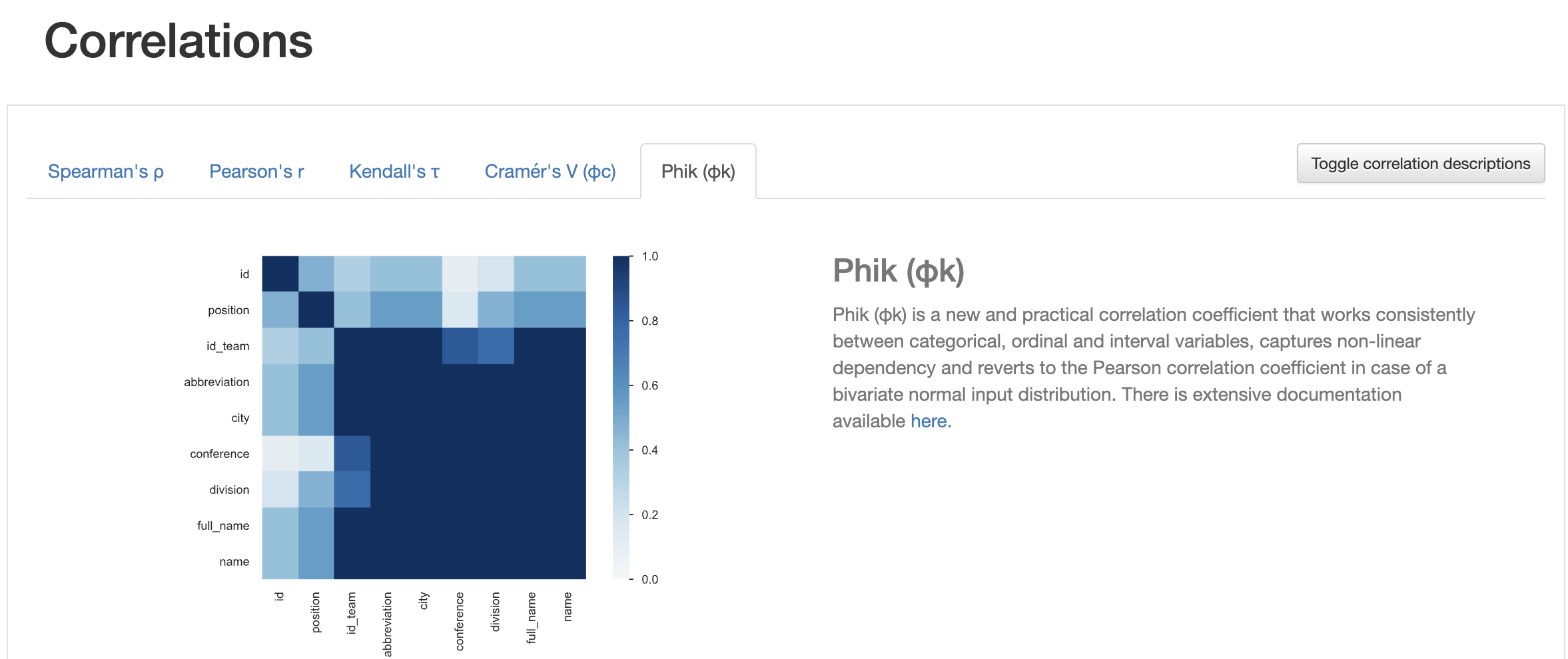
The correlations visualization in the Pandas Profiler report highlights relationships between numerical variables, revealing potential patterns and dependencies that could be useful in building predictive models or understanding data trends. Various correlation coefficients, such as Pearson, Spearman, and Kendall, can help you identify the strength and direction of these relationships.
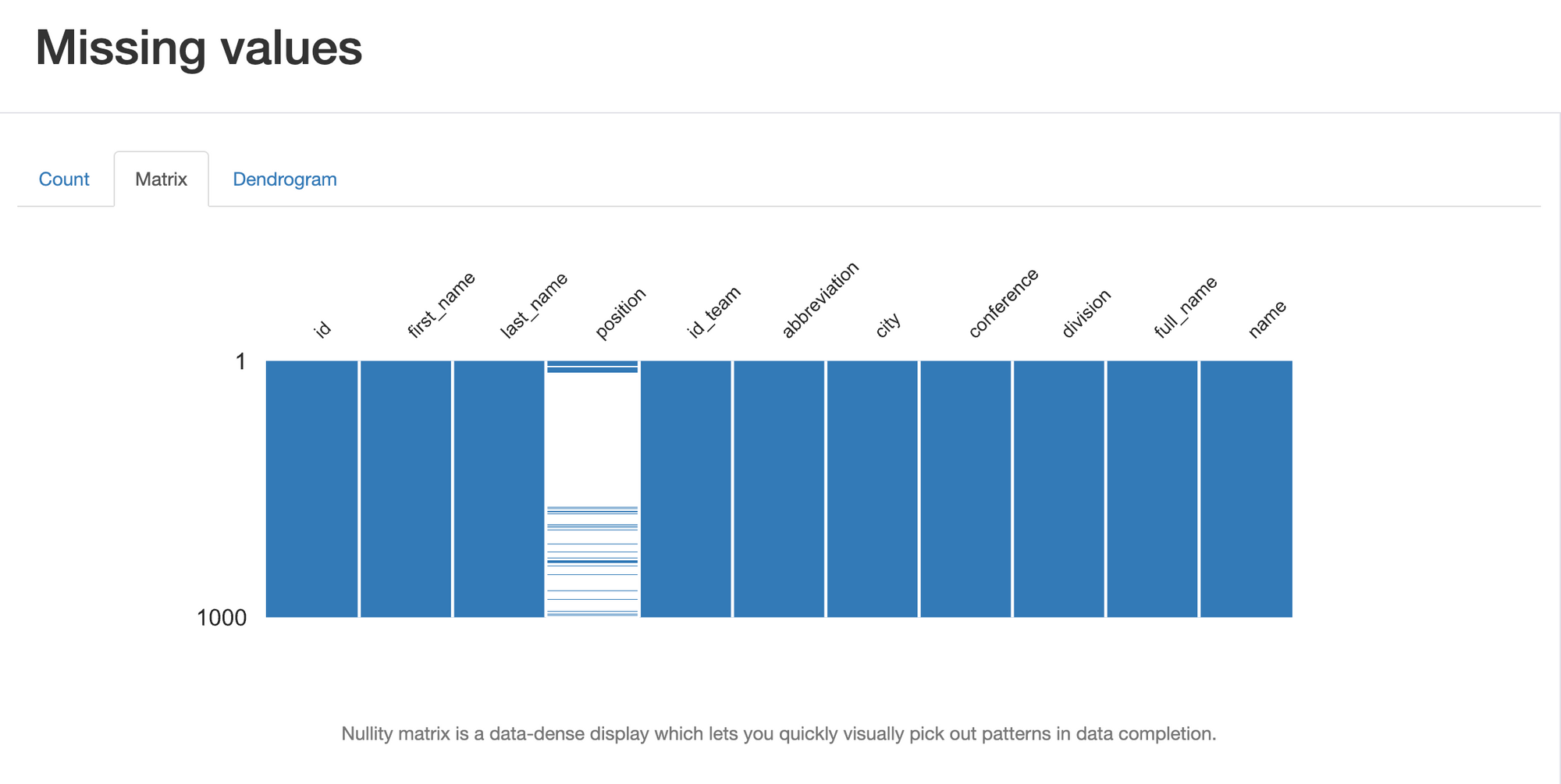
The missing values visualization provides a clear representation of the distribution and patterns of missing data within your dataset. By visualizing the occurrence and quantity of missing values, this plot helps you identify potential issues, make informed decisions about imputations or data removal, and plan effective data preprocessing strategies.
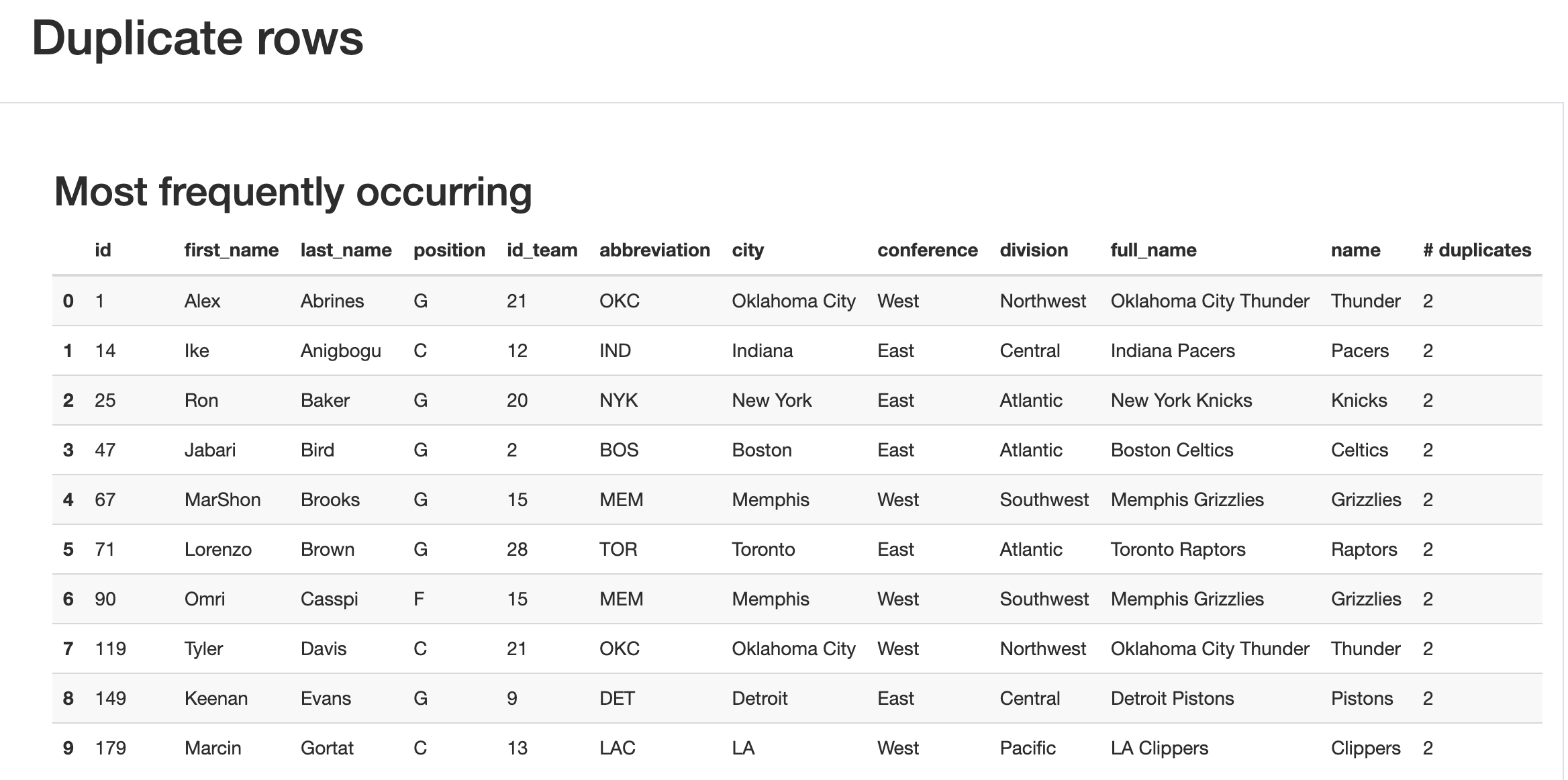
At the bottom of the overview page, you'll find 3 tables of which the 10 first rows, the 10 last rows and the 10 most frequently occuring rows are displayed.
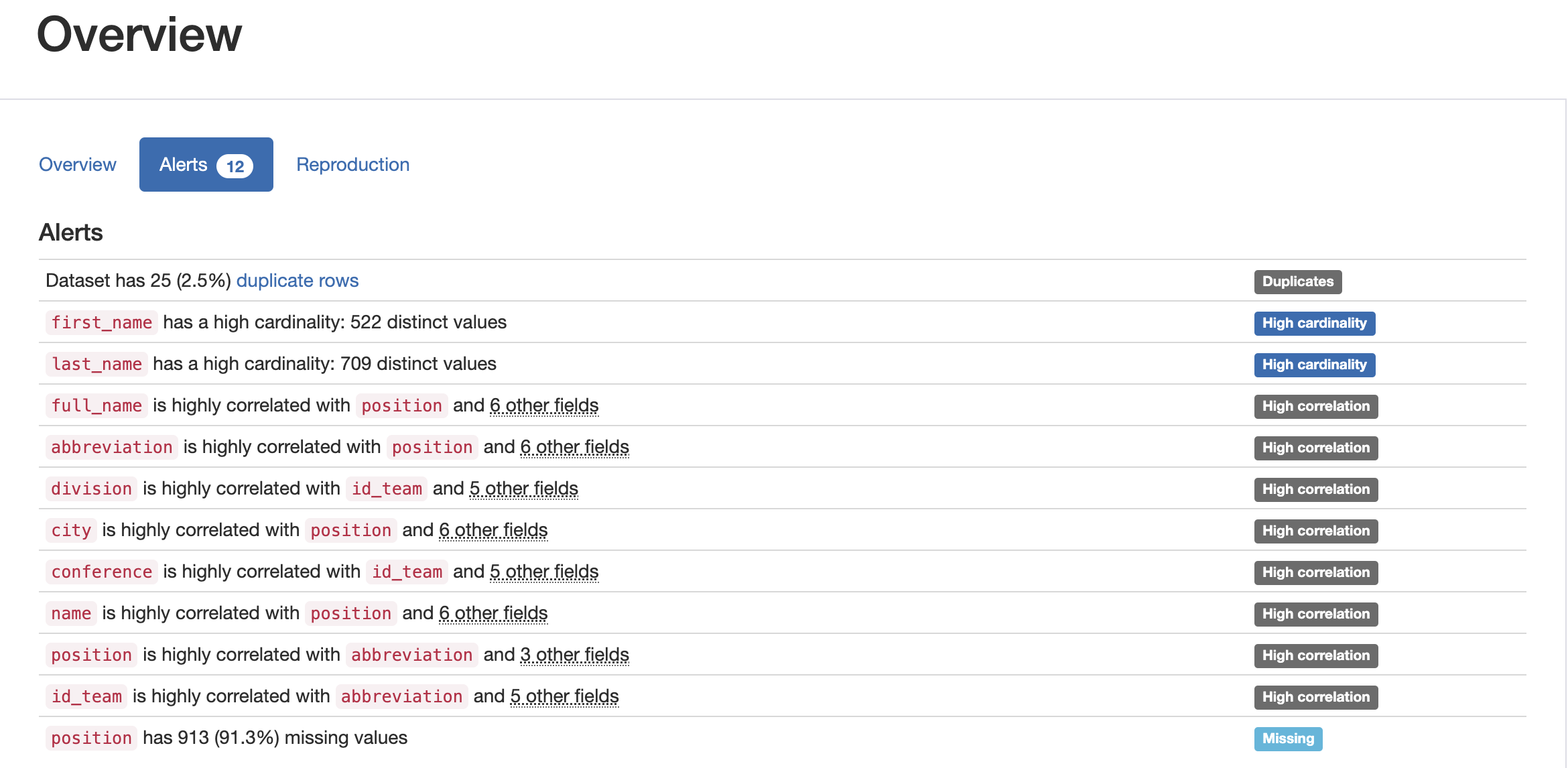
The alerts page in the Pandas Profiler report is designed to bring your attention to potential issues or anomalies within your dataset. It highlights areas that may require further investigation or preprocessing before conducting data analysis or building machine learning models. The alerts can range from high missing values, high cardinality, significant correlations, or presence of zeros in numerical variables, among other potential concerns.
By summarizing these critical aspects of your data, the alerts page allows you to focus on addressing data quality issues or making informed decisions on data transformation and feature engineering. Ultimately, it helps ensure that your dataset is prepared effectively for subsequent analysis and modeling tasks.
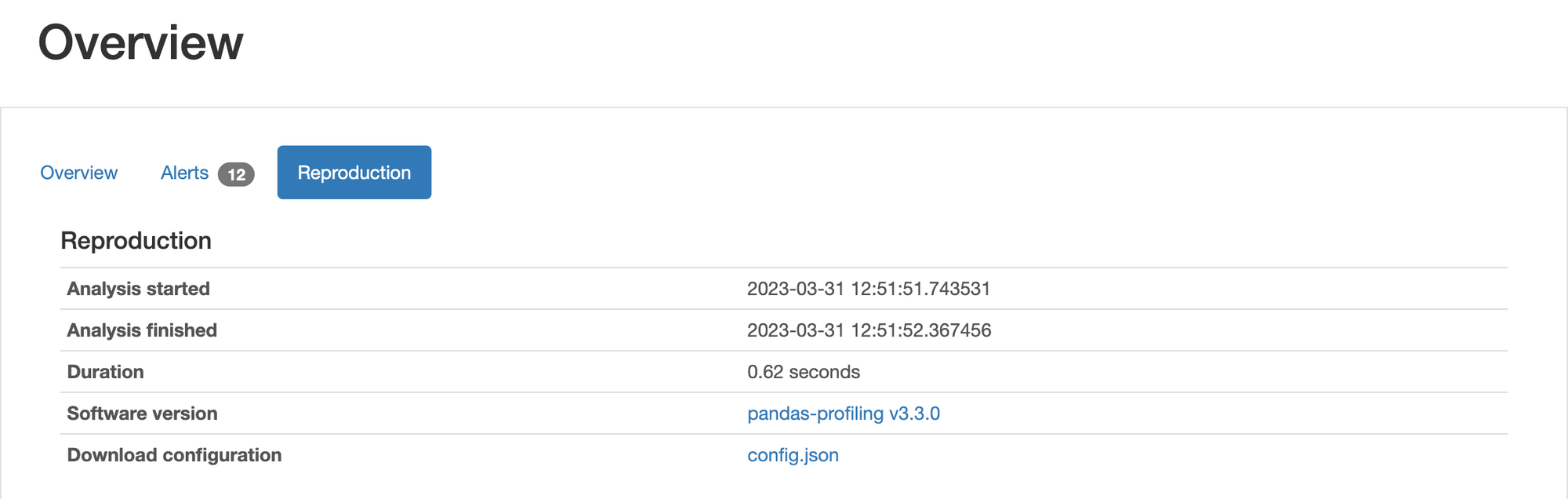
Finally, there is a reproduction page, that contains meta information about the profiling report, with regards to the software versions, but also when it was started, when it was finished and how long it took. Useful in case you are planning to store the profile results afterwards.
Sweetviz
Sweetviz is another open-source Python library that generates insightful and interactive data profiling reports from pandas DataFrames. It offers a quick and efficient way to perform exploratory data analysis (EDA). Here's a step-by-step guide on how to use Sweetviz:
Setup
- Install the package: If you haven't installed Sweetviz yet, you can do so using pip:
%pip install sweetviz- Import required libraries: Once installed, import Pandas and Sweetviz into your Python script or Jupyter Notebook:
import pandas as pd import sweetviz as sv- Load your dataset: Read your dataset into a pandas DataFrame.
df = pd.read_csv('../data/nba_players.csv')- Generate the Sweetviz report: Create a Sweetviz report from the DataFrame using the
analyze()function. You can also configure the report with various options, such as specifying the target feature for classification or regression tasks. You can either display the report in your Jupyter Notebook or save it as an HTML file.
# Generate the report
report = sv.analyze(df)
# To display the report in a Jupyter Notebook:
report.show_notebook()
# To save the report as an HTML file:
report.show_html('../profiles/nba_players_sweetviz.html')Results
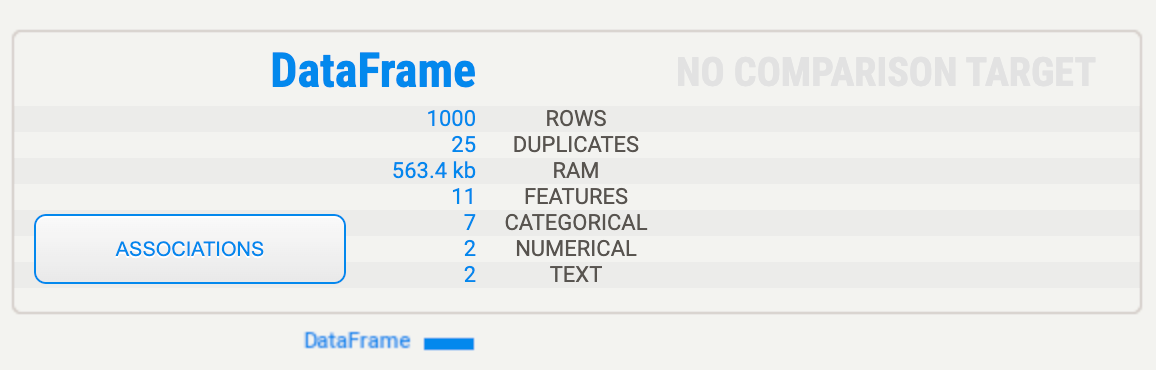
In comparison to the pandas profiler report, the Sweetviz report is a lot more condensed. The overview section containing a number of metrics about the dataframe such as the amount of records, how many of these are duplicates, the amount of columns per data type. And also the amount of RAM it took to load the data.
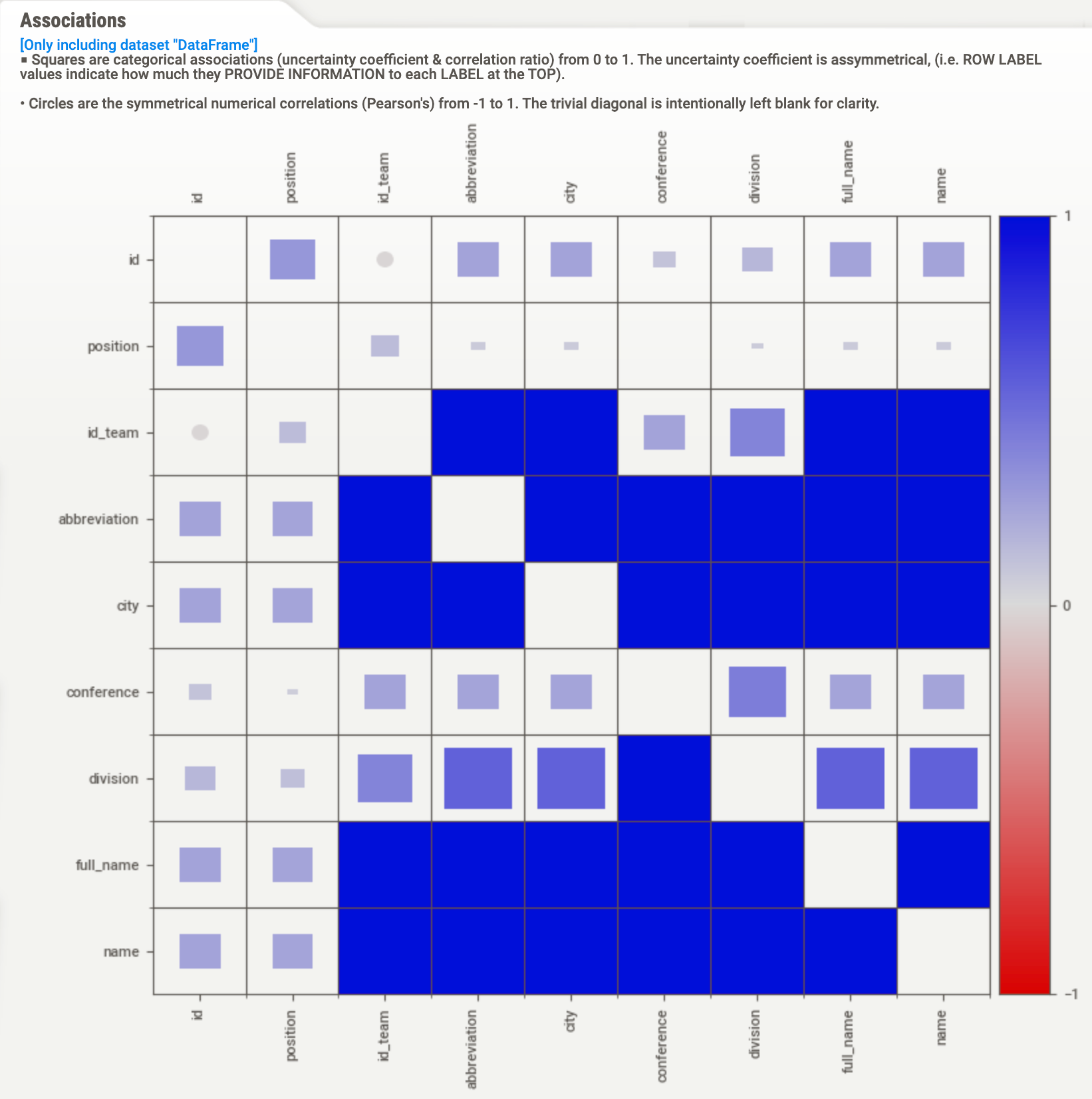
You may have noticed the entire right hand side being empty up until now, this is not a design flaw, but a deliberate choice. Once you click on the associations button, or hover over any of the columns in the list, it gets occupied with a visual of what you're focused on.
The associations pane shows how the different columns are correlated with each other, here the different types of correlations (numerical vs categorical) are placed on top of each other and seperated by shapes, which makes it again more compact.
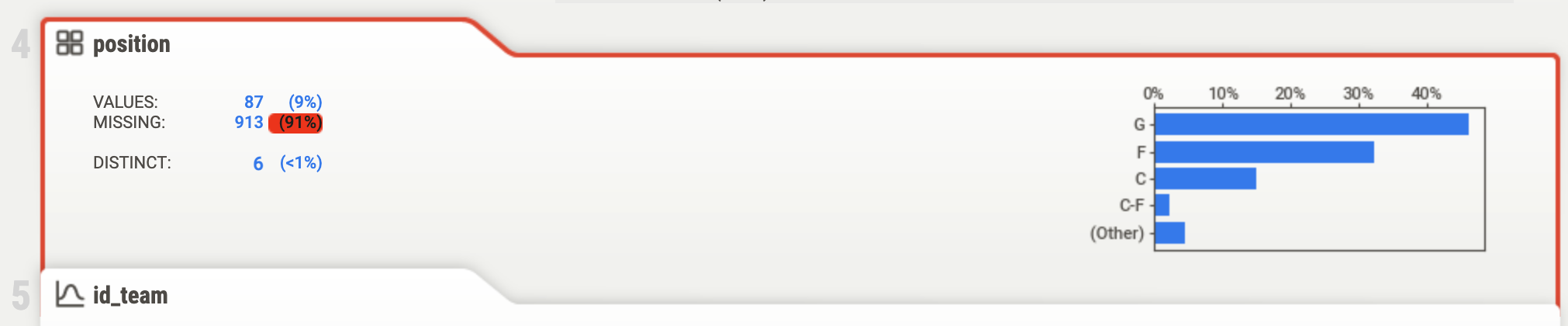
For every variable, there is an entry in this list, which shows a brief summary of the contents, more specificly the non-missing values, the missing values, and the amount of distinct values. It also has some conditional formatting to catch your attention if there is an outlier.
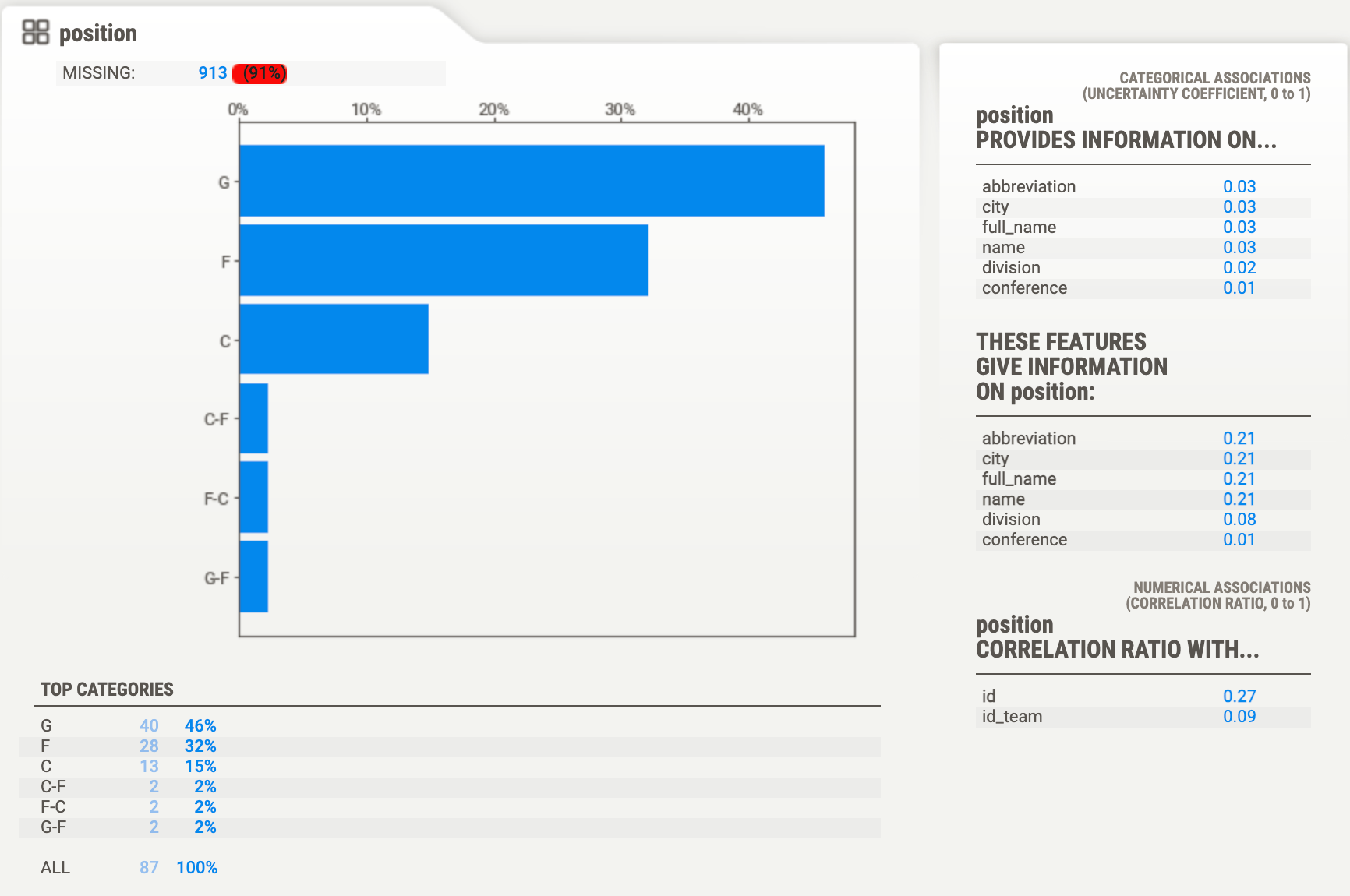
Hovering over the column in the list, opens up a pane on the right side, providing even more insight in the column contents. Here we can find a visualisation depending on the data type, and a number of metrics on the correlations this column might have with others.
Conclusion
In conclusion, this blog post has provided a comprehensive comparison of two popular data profiling tools, Pandas Profiler and Sweetviz, for simplifying exploratory data analysis (EDA). Both tools offer powerful features and visualizations, enabling users to gain valuable insights into their datasets quickly and efficiently.
Key differences between Pandas Profiler and Sweetviz include:
- Report layout and structure: Pandas Profiler provides a more detailed report structure with separate sections for correlations, interactions, and missing values, whereas Sweetviz offers a more compact report with a focus on the associations between variables.
- Visualization styles: Pandas Profiler presents a variety of visualizations for each variable, while Sweetviz uses a more condensed approach, displaying detailed visualizations only when a specific variable is selected or hovered over in the list.
- Report interactivity: Sweetviz generates interactive reports that allow users to explore different aspects of their data by hovering over or clicking on specific columns. In contrast, Pandas Profiler reports are less interactive but provide a more comprehensive overview of the dataset at a glance.
- Correlations: Pandas Profiler displays separate correlation coefficients (Pearson, Spearman, Kendall) for numerical variables, whereas Sweetviz combines different types of correlations into a single associations pane.
- Alerts: Pandas Profiler includes an alerts page to highlight potential data quality issues or anomalies, while Sweetviz does not have a dedicated alerts section.
Based on these differences, you can choose the most suitable tool for their needs. Pandas Profiler might be preferred for a more in-depth analysis with detailed sections and alerts, while Sweetviz can be a better choice for users seeking a more compact and interactive report.
Ultimately, both are powerful tools for speeding up the EDA process and gaining insights into new datasets. And many more alternatives exist. The choice depends on the user's preferences, dataset characteristics, and specific requirements for their data analysis tasks.
Resources
https://pypi.org/project/sweetviz/
https://pypi.org/project/pandas-profiling/
https://www.kaggle.com/datasets/darshanpatel3112/nba-players-dataset
You might also like
 GitHub
GitHub
