

By Paolo Léonard, Arthur Chionh, Nemish Mehta
Following my article Data Quality Tools 2023, I found it interesting to get back to some of the tools discussed there, see how they improved over the past months, and discover new ones. Last time, we only scratched the surface of dbt testing capabilities. With the right tooling, dbt can become a powerful data quality hammer. In this article, we will explore re_data, Elementary, and updates for Soda and GX!
A big thanks to Arthur and Nemish for helping me write this article!
As last time, we evaluate the tools based on infrastructure compatibility, data integration, and reporting and dashboard integration with additional aspects like ease of use, data quality rule coverage, or meta indicators. Please look at my previous article if you want more information about the evaluation parameters.
Data quality tools
Today we will cover the following tools:
- re_data & Elementary: both tools are based on dbt and as such leverage its capabilities. Infrastructure and data integration are both dependent on dbt's infra and integration.
- Soda: an open-source data quality tool offering a variety of features. They recently released a self-hosted agent for their cloud version and added support for their version of data contracts.
- Great Expectations (GX): is a strong contender in the data quality tooling space. Their cloud version has finally been released and I had the opportunity to take a peek.
re_data
Launched in 2021 and based in Berkeley, California, re_data has quickly established itself as a pivotal tool for data reliability. As an open-source framework designed to integrate seamlessly with dbt projects and data warehouses, re_data focuses on enhancing the observation and maintenance of data quality through comprehensive metrics and anomaly detection techniques. With over 1,500 stars on GitHub, it reflects a growing community and endorsement of its utility. They also launched a SaaS offering that we have yet to try.
re_data is dbt native and as such limits itself to observing dbt projects. It offers the following features and integrations:
- It supports Snowflake, Redshift, PostgreSQL and BigQuery with planned support for Spark and Databricks coming soon. This is currently rather limited but you can still create your integrations, like the community has done for Trino.
- re_data does not offer any particular integration with popular orchestrators. However, running re_data involves a single bash command, it can easily be configured with the major orchestration tools.
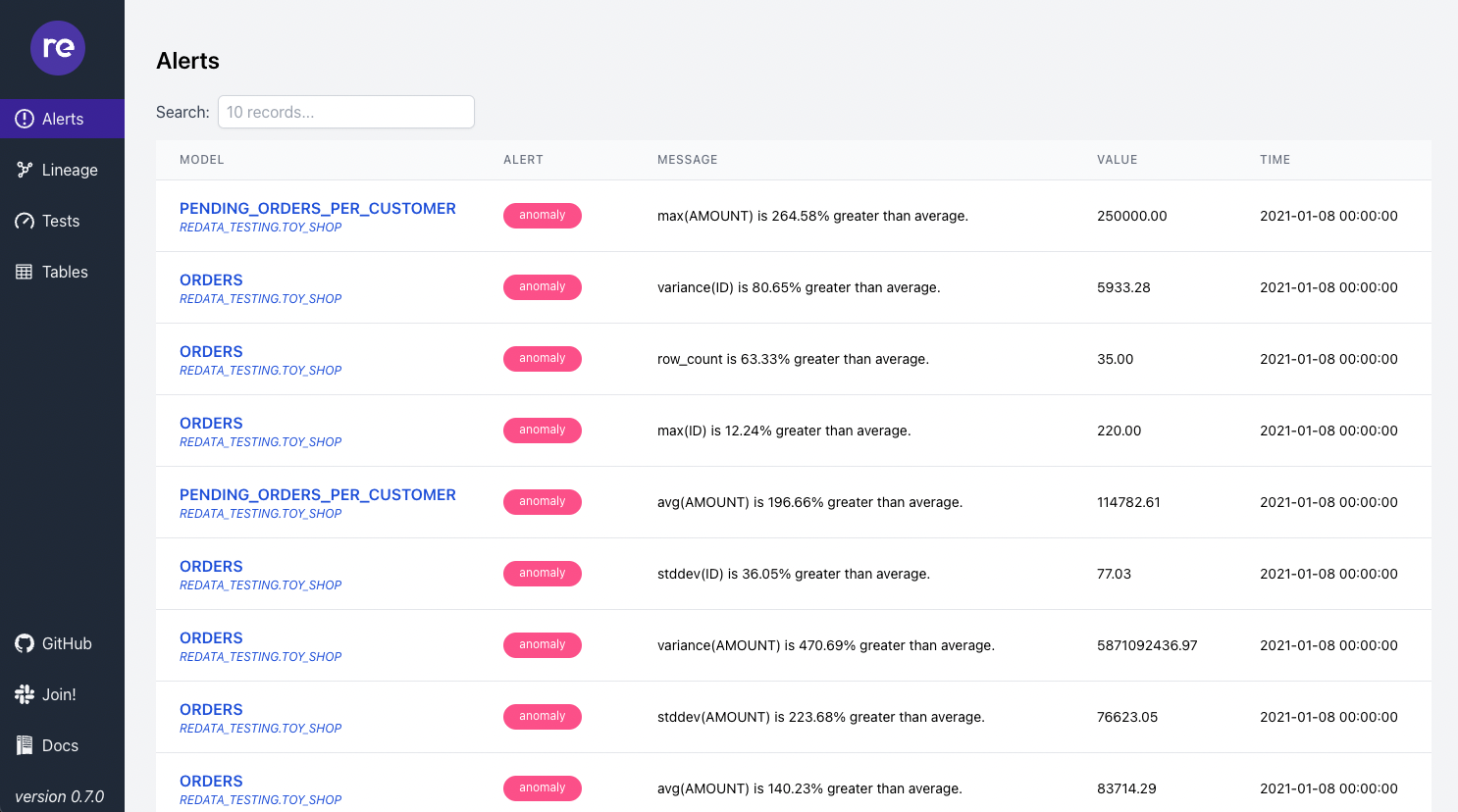
re_data shines with its ease of use. Configuration is flexible, allowing users to specify which tables to monitor directly within their dbt models, schema, or project files. Additionally, you can define specific metrics, metric groups, and anomaly detection parameters to tailor monitoring to their needs. Cherry on the top is you can filter the data on date to only consider the latest data.
Running re_data is a simple CLI command to execute your monitoring and visualise the results in a UI setup. Based on the results you can also send notifications through Slack or email, ensuring your teams are promptly alerted to data issues.
Finally, re_data offers a variety of out-of-the-box data cleaning macros, such as clean_additional_whitespaces and filter_get_duplicates, which facilitate quick and efficient data cleaning/normalisation/validation. Users can also define custom metrics tailored to their needs using SQL, enhancing the tool's flexibility and applicability to diverse data scenarios.
In our exploration of re_data, we found some challenges:
- No native integration with orchestration tools will require manual adaptation to schedule your re_data runs. Adding support for Airflow/Prefect/Dagster would definitely help users integrate re_data in their data workflow.
- Supported data sources are currently limited which can be limiting the adoption of re_data into teams using other platforms.
In conclusion, launched in 2021, re_data has made a splash in data reliability, focusing on dbt projects. It’s simple to set up, supports popular data platforms like Snowflake and BigQuery, and lets you customise data monitoring to the nines. While it currently lacks direct orchestration tool integration and broader data source support, its user-friendly command-line operations and robust community contributions keep it at the forefront of data observability tools. It's versatile but there's room to grow, especially for teams using different tech stacks.
{kind=link}
Elementary
Elementary provides open-source data observability that can be deployed in minutes without compromising security. It is an Israel-based company founded in 2021, and is backed by Y Combinator and was in Y Combinator’s W22 batch. With over 1,600⭐️ stars on GitHub and a substantial community on Slack, Elementary is gaining traction for its user-friendly approach and powerful features. Elementary is very similar to re_data in terms of capabilities and codebase but we won't cover that here.
Elementary aligns with dbt projects much like re_data, but extends its integration capabilities significantly:
- Elementary supports major databases such as Snowflake, Redshift, PostgreSQL, BigQuery, and Databricks. Plans to include Clickhouse and Athena are also underway.
- While it doesn't have a specific Airflow operator, Elementary can collect valuable metadata from Airflow runs, enhancing its compatibility with existing data workflows.
Elementary stands out as a robust, open-source dbt-native data observability tool that shines with its integration across data warehouses and business intelligence tools like Tableau and Looker. Key features include sophisticated data anomaly detection, customisable Python tests (in beta) for precise monitoring, and a dynamic data observability dashboard that consolidates data quality metrics visually. Alerts can be streamlined to platforms like Slack, enhancing real-time monitoring. Additionally, its comprehensive data lineage graph and automated monitors in the cloud version simplify data observability without increasing compute costs, making it highly efficient. Elementary’s configuration-as-code approach integrates seamlessly into dbt projects, ensuring a smooth setup and maintenance process.
Elementary shares some limitations similar to re_data due to its dbt-native architecture:
- Dependency on dbt: Its functionality is restricted to environments where dbt is already implemented, potentially limiting its use in non-dbt-centric pipelines.
- Integration Constraints: Despite collecting metadata, Elementary lacks native integration with orchestration tools like Airflow, requiring additional setup to align with certain workflows. This might add complexity to its deployment and operational management.
Elementary provides rapid data observability tailored for dbt projects, with extensive integrations including major databases and business tools. Despite its dependency on dbt and integration challenges with orchestration tools, it excels with features like anomaly detection, a dynamic dashboard, and comprehensive data lineage. While we haven't tested Elementary Cloud, its data catalog and column-level lineage appear promising for advanced data management needs.

{kind=link}
Soda
Soda has recently enhanced its OSS and Cloud offerings. Key updates include:
- Soda-hosted agent: Quickly integrate data quality processes with a new Soda-hosted agent, initially supporting Snowflake, BigQuery, PostgreSQL, and MySQL. Self-hosted agents for other databases remain an option.
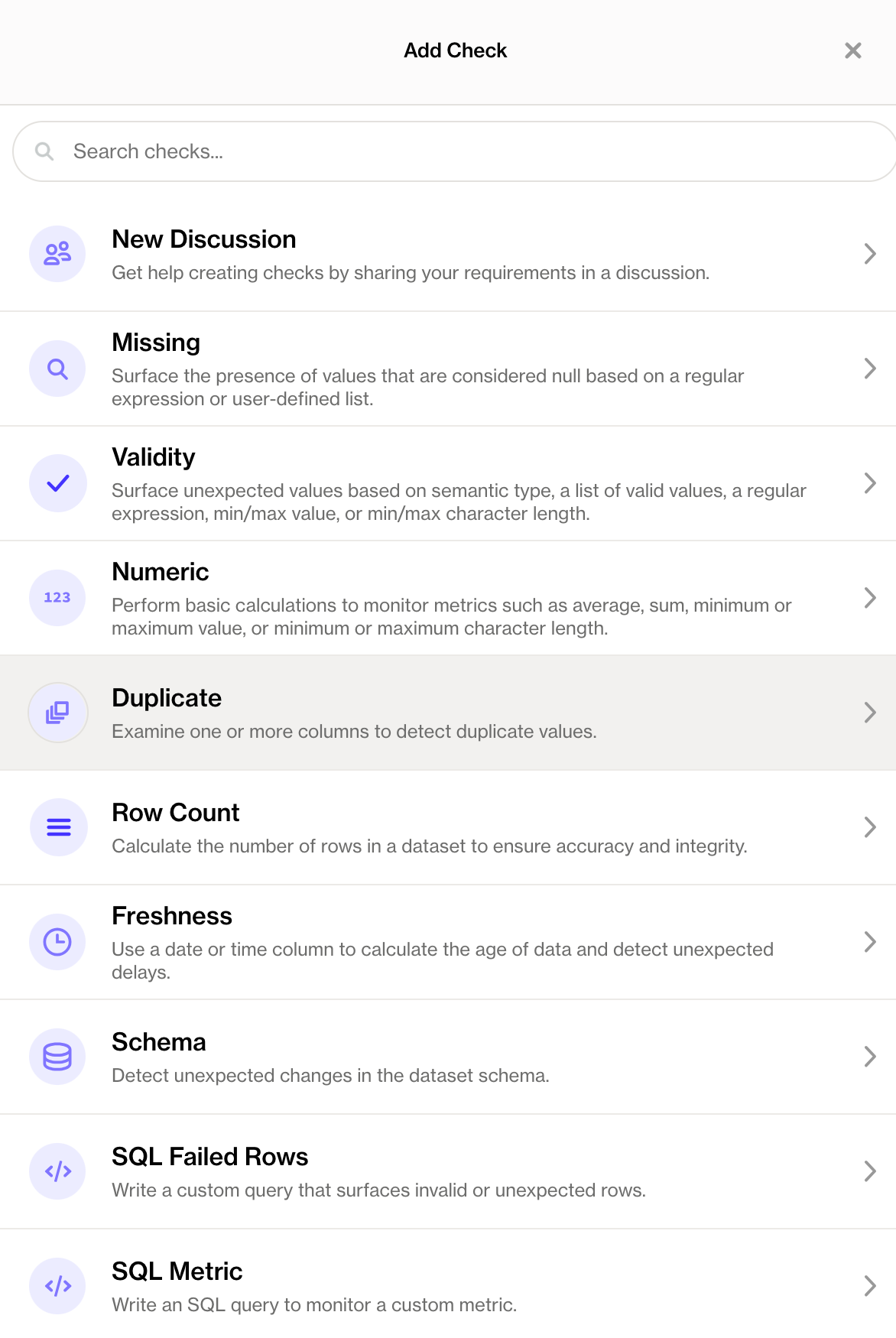
- No-code data quality checks: Soda introduced no-code data quality checks allowing business users to directly create their own DQ checks within Soda Cloud without touching any YAML file.
- Data contracts: Tom Bayens has introduced preliminary support for data contracts, anticipating further developments in this area.
Great Expectations
IT'S OUT!!
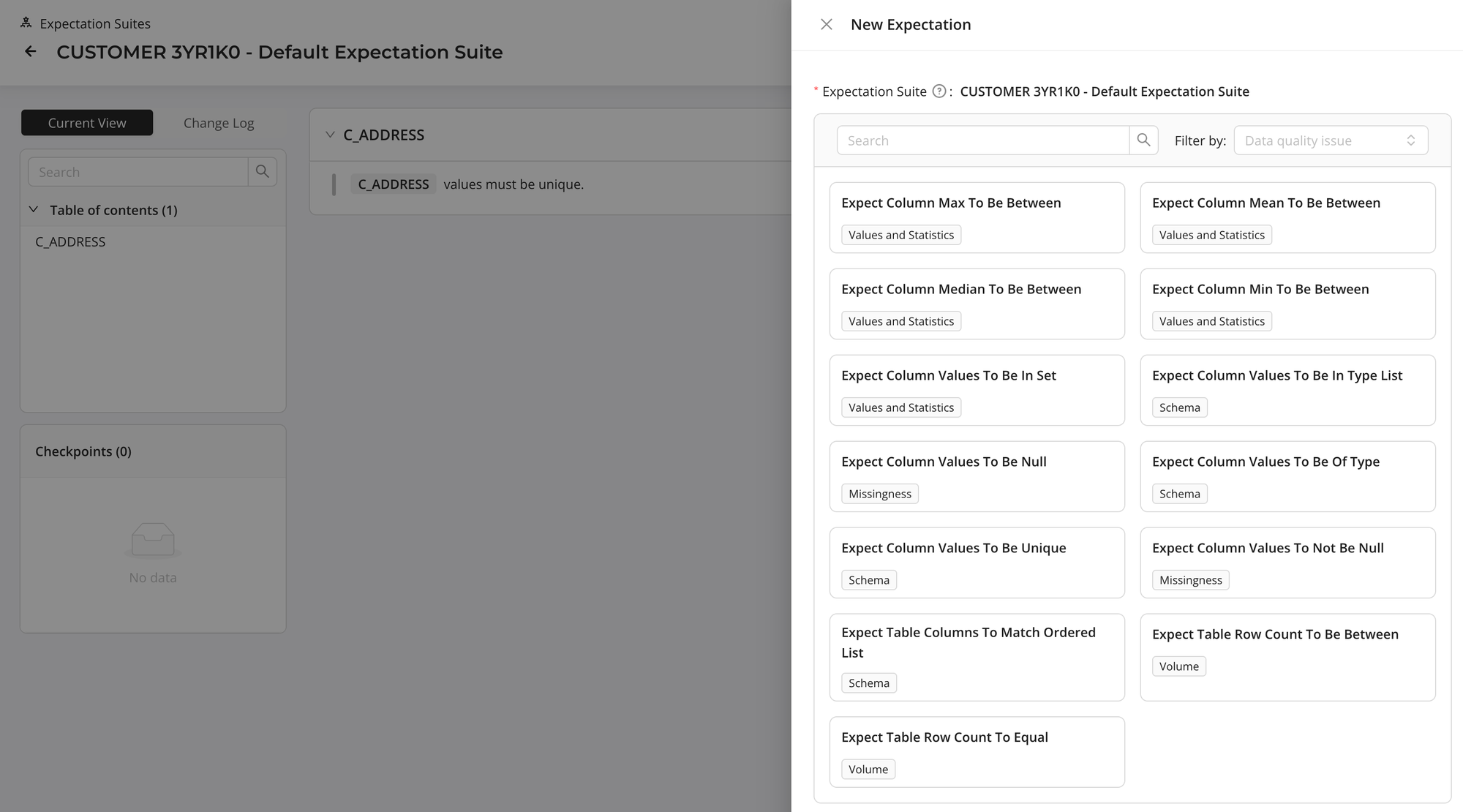
GX has launched their new SaaS offering for their OSS library. Although it's not yet perfect, they are making significant progress towards delivering an excellent product. Key advantages include no-code data quality expectations, versioning of expectations, and competitive pricing. However, it still needs further refinement in terms of UX and integration (only natively supports Snowflake and PostgreSQL at the time of the writing) to function as a comprehensive data quality tool.
Conclusions
This edition of the State of Data Quality Tools featured some very interesting options. While I still consider Soda the best data quality tool due to its versatility and advanced SaaS capabilities, both Elementary and re_data are strong contenders for those using dbt in their projects. Additionally, GX Cloud is worth keeping an eye on.
I hope you enjoyed the read, don't hesitate to write a comment if you have any questions and stay tuned for the next issue where we will explore the big three cloud DQ offerings!