

By Murilo Cunha
Snowflake announced on June 2022 that they are offering Python support with Snowpark! 🎉 What does that mean, you ask? Well, that means that now we can do all sorts of things with Python on Snowflake ecosystem, even some machine learning 🦾. "How?!?!", you ask? Short answer is: UDFs and stored procedures. Long answer is, as you could've guessed, a bit longer.
What is Snowflake?

If you're new to Snowflake, it's basically a managed SQL warehouse solution. It's deployed on top of the main cloud providers (AWS, Azure and GCP) where they offer storage and compute. Compute comes in clusters, called warehouse in Snowflake, available in "T-shirt sizes" 👕 (X-small, small, medium, large, X-large, ...), and you manipulate your data with SQL queries.
But that's not where the story ends. It's basically a SQL warehouse on steroids 💪. The kind of steroids that lets you create workflows, ingest data real time, store unstructured data, run Java, Javascript, Scala and Python code. In "Snowflake world", those are stages, tasks, stored procedures, Snowpipe and Snowpark.
Still not sure of what those mean? Let's define them!
The batteries
Stages
Snowflake stages are, in a nutshell, support for unstructured data. That means that Snowflake can store basically any data that you want. Images, text files or even model weights. That makes Snowflake a suitable solution for a data lake as well.
You can push/retrieve data to stages using the Python SDK for Snowflake (aka Snowpark), with the PUT/GET SQL commands or even via REST API.
Tasks
Tasks are the essential component of workflows. If you are familiar with Airflow, they are the same kinds of tasks. These tasks are basically an operation that will manipulate the data somehow. In Snowflake, these tasks are SQL statements. They can call UDFs or stored procedures. You create a workflow by chaining these tasks forming a Directed Acyclic Graph (DAG).
Stored procedures
Stored procedures allows users to execute procedural programming - that is, step by step instructions. In practice that lets you write for-loops or branching. With SQL that lets you write dynamic statements. But Snowflake also let's you write some procedures using Java, Javascript, Scala or ✨Python✨ (with Snowpark). That enables users to write code in other languages that will be executed in the Snowflake infrastructure (with some restrictions).
Snowpipe
Snowpipe works with stages. It allows users to load data into tables faster, in micro batches. In effect, that means you can have near real-time data (minutes) into your tables. You could have streaming data loaded into a stage and subsequently loaded into a table with Snowpark. Pretty cool, right?
Snowpark
Snowpark is the Snowflake SDK. It's available for Java, Javascript, Scala and (recently) Python! For Python, it's an improvement over their previous package - snowflake-connector-python. You can also install the Snowpark for Python with pip with pip install snowflake-snowpark-python. As this is also the star of the show, let's dive in a bit deeper.
At the time of writing, Snowpark for Python is also in "public preview", meaning it's a new feature, available for everyone, but you should expect bugs and maybe-not-full-support. They don't give any guarantees everything will work as expected and the absence of side effects.
Snowpark Session and SQL statements
In my experience, before you were more restricted as to how to execute SQL statements. You were able to query the data with from regular Python strings. Though it works, it's also a bit awkward to dynamically generate SQL statements, and it exposes vulnerabilities if you fetch inputs from external services - ie.: SQL injection.
Imagine you have a table with students, and you create a system for professors to retrieve grades. You build your query likef"SELECT grade FROM students WHERE name = {student_name}". Bad actors could do all sorts of nefarious things by injecting more SQL statements in the string (i.e.:student_name="John Doe; DROP TABLE students).
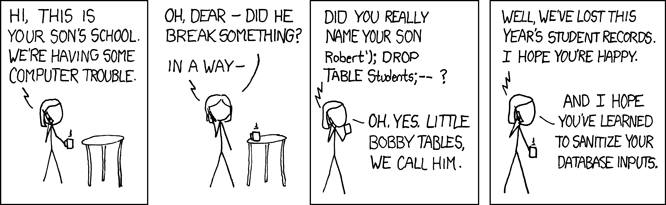
In Snowpark for Python you can also write SQL queries from Python code, via a Session object. For example, SELECT grade FROM students WHERE name='Murilo' becomes
import os
from snowflake.snowpark import Session
from snowflake.snowpark.functions import col
connection_parameters = {
"account": os.environ["snowflake_account"],
"user": os.environ["snowflake_user"],
"password": os.environ["snowflake_password"],
"role": os.environ["snowflake_user_role"],
"warehouse": os.environ["snowflake_warehouse"],
"database": os.environ["snowflake_database"],
"schema": os.environ["snowflake_schema"],
}
with Session.builder.configs(connection_parameters).create() as session:
session.table("students").select(col("grade")).where(col("name") == "Murilo")Snowpark UDFs and stored procedures
With Snowpark, you can also create stored procedures with the decorator @sproc, create Snowflake UDFs with the @udf decorator or with the @pandas_udf decorator. Creating a UDF looks like
A decorator is basically a Python function that takes a function as an argument and returns another function. More info here.
import os
from snowflake.snowpark import Session
from snowflake.snowpark.functions import pandas_udf
from snowflake.snowpark.types import PandasSeries
# `connection_parameters` omitted
with Session.builder.configs(connection_parameters).create() as session:
@pandas_udf(
name=f"udf_name",
is_permanent=True,
stage_location=f"@stage_path",
replace=True,
imports=["custom_imports"],
packages=[
"conda_import==0.1.0",
"another_conda_import==0.2.0",
],
)
def run(ds: PandasSeries[int]) -> PandasSeries[float]:
"""Adds 1 and converts to float."""
return ds.add(1).astype(float)After the code is executed, the UDF_NAME function should be available in Snowflake when you call SHOW USER FUNCTIONS; and should be available when you call SELECT YOUR_DB.YOUR_STAGE.UDF_NAME(1);. You could also call the UDF in a stored procedure like
import os
from snowflake.snowpark import Session, Table
from snowflake.snowpark.functions import call_udf, col, sproc
from snowflake.snowpark.types import DecimalType
# `connection_parameters` omitted
with Session.builder.configs(connection_parameters).create() as session:
@sproc(
name="stored_procedure_name",
packages=["conda_dependency==0.1.0"],
)
def run(sproc_session: Session) -> Table:
"""Run stored procedure - build plots and store them in a Snowflake stage."""
# More Python code here
return sproc_session.table("table").select(
col("column"), call_udf("udf_name", col("int_col")).cast(DecimalType())
)
session.call(sproc_name="stored_procedure_name")
Limitations
This looks pretty cool. But there are some tight restrictions when it comes to what you can do with it in practice.

Dependencies. The dependencies is a subset of conda dependencies. By conda I mean the same Anaconda that you may know as a package index or for your virtual environments. The dependencies are not always the latest sometimes. It also means that other pip packages that are not available in conda are not easily available. You may still be able to include vendorized packages in your project to bypass this restriction. Package names occasionally differ from pip and conda (for example, PyTorch is installable as torch in pip, but pytorch in conda).
"Vendorized package" basically means copying all the files locally and treating them as part of your current project. If you choose to vendor a dependency, you should follow the pip guidelines. In fact, since you needpipto install packages,pipitself comes with some vendorized packages.
Custom code. You can upload custom files to your UDF and stored procedure. That's the imports keyword argument in the example above. These artefacts are loaded in the machine, and you can access them dynamically with import_dir = sys._xoptions["snowflake_import_directory"] in your UDF code. If the import path points to a directory, Snowflake will zip the contents into a .gz file and upload it to a stage that will be available for the UDF/stored procedure. That means that you could have some custom logic (which you'll probably want) and include that in your UDF via zip imports. Taking one step further, you could have package wheels and upload those - in practice they are similar to a zipped directory with some package metadata.
Package wheels are the.whlfiles that are uploaded topipto distribute packages. If you are familiar with Poetry,poetry buildactually builds the wheels that are used before publishing withpoetry publish.
Pushing a local package to be used in a UDF becomes
import os
from snowflake.snowpark import Session
from snowflake.snowpark.functions import pandas_udf
from snowflake.snowpark.types import PandasSeries
# Omitting `connection_parameters`
with Session.builder.configs(connection_parameters).create() as session:
@pandas_udf(
name="udf_with_custom_package",
is_permanent=True,
stage_location="@stage",
replace=True,
imports=["path/to/your/local/package.whl"],
)
def run(ds: PandasSeries[str]) -> PandasSeries[dict]:
"""UDF with local package."""
import os
import sys
import_dir = sys._xoptions["snowflake_import_directory"]
sys.path.append(os.path.join(import_dir, "package.whl"))
import pandas as pd
from package import __version__
from package.script import function
predictions = pd.DataFrame(
{"prediction": function(pd_kwarg=ds), "package_version": __version__}
)
return pd.Series(predictions.to_dict("records"))
This is a bit more verbose than I'd like. And it feels like a hack rather than a feature. But it works (or at least it did work on my machine 😅).
Implementation. Maybe this is just me here, but the first time I saw a demo on Snowpark UDFs I remember seeing that you could use it to deploy machine learning models. You could load the models in the global scope and simply use it in your UDF logic, and Snowflake should "know you are using these weights and pickle them in your function UDF". But what if these model weights are defined in another function? Does it also pickles functions that are in scope? This feels a bit magical and a bit uncomfortable, as the contract between local and Snowflake machines gets a bit blurry.

Hardware. Related to these imports and model weights. I've also encountered some limitations. My first idea was to implement transformer models from Huggingface. But I quickly ran into a couple of problems. Firstly, I could not download pretrained models directly into Snowflake for training. I solved that by downloading them locally and pushing them to a stage. But, to my surprise, when I tried to load them from the stage I quickly ran into out-of-memory errors. I even tried increasing the warehouse size with no success. As there's not a lot of clarity in the hardware for the warehouse (memory, compute, etc.) it's a bit hard to know what will work and what won't. So no fancy big models in Snowflake just yet. As a side note (but not a deal breaker), there is no accelerated compute hardware available for Snowflake (to my knowledge). There's then little added benefit from training models from a stored procedure.
Error handling. This is maybe the biggest of the "issues" I have from my Snowpark experience. If you're creating a UDF, you often get not-so-straightforward errors, especially since the functions are passed dynamically by the decorator. Or even if the UDF creation succeeds, you may encounter errors in the Snowflake side, when calling the UDF. I was not able to find tracebacks in the Snowflake IDE. Nonetheless, I must admit I don't see easy ways out of this. Snowpark's flexibility comes at this expense.
This feels like a lot of complaining, but it's worthwhile to emphasise that Snowpark is on public preview. And though I've hit some walls along the way, I was still able to carry on with my toy ML use case all the way to deployment.
What "toy ML use case"??
Ah yeah, I mentioned that these opinions come from first hand experience, but the experience itself was trying to deploy a full machine learning solution with Snowflake only.
What do I mean by "full machine learning solution"? Can we orchestrate workflows with tasks? Version and store models with stages? Can we train with stored procedures? Can we deploy with UDFs? CICD?
Short answer? Yes, you can! 🙌 Long answer? Well, you know the drill... but I'll leave this one for another time...

If you made this far, thanks for reading! I'll discuss the actual solution on a next post! I'll also throw in a bit of Confluent Cloud, Terraform Github Actions and Streamlit. If you're impatient, feel free to take a peek at the project repo! I'll see you next time! 🚀
You might also like


