

By GUPPI
Training large (transformer) models is becoming increasingly challenging for machine learning engineers. With new and massive transformer models being released on a regular basis, such as DALL·E 2, Stable Diffusion, ChatGPT, and BLOOM, these models are pushing the limits of what AI can do and even going beyond imagination. One thing these transformer models have in common is that they are big. Very very very big. For instance, the famous GPT-3 model has around 175 billion parameters, BLOOM has even around 176 billion parameters, the Megatron-Turing NLG 530B model has a whopping 530 billion parameters and PaLM even surpasses this unbelievable size with 540 billion parameters. Reason enough to run out of memory right?

Where does the memory actually go during training? Well, first of all, a part of the memory goes to the model itself (its parameters/weights). Secondly, during training, most of the memory actually is absorbed by model states (optimiser states, gradients and parameters). Thirdly, the rest of the memory is consumed by residual states such as activations, temporary buffers and fragmented memory.
Obvious techniques to reduce memory usage involve reducing the batch size or to use a smaller model with fewer layers and/or parameters, but this comes at the expense of time and model’s accuracy. Reducing the batch size too much could result in slow loss convergence and hinder the optimisation process. Similarly, reducing the model size could result in decreased accuracy, as the model may not be able to capture all the relevant features of the data. While switching to a GPU with a larger memory capacity is an option, this may not be feasible for everyone, as it can significantly increase the cost of the project.
So what other solutions are available for machine learning engineers to democratise access to large model training without sacrificing accuracy or spending an excessive amount on additional or larger GPUs?
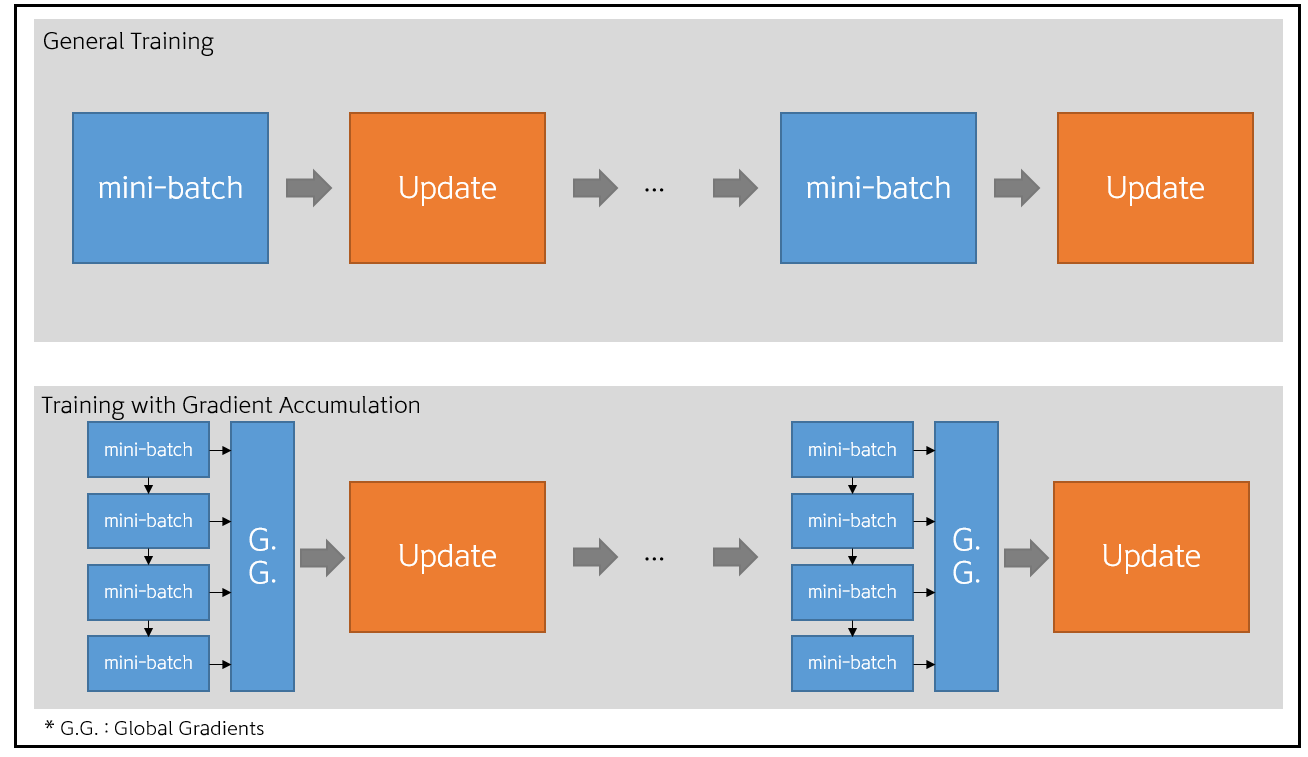
Gradient accumulation
The first technique we will discuss is gradient accumulation which effectively simulates a larger batch size without requiring a larger GPU memory.
Instead of updating the model parameters after every forward-backward pass with a small batch, the optimiser accumulates the gradients over several batches before performing a single update step.
Suppose we have a batch size of 64, but GPU memory can only accommodate a batch size of 4, by setting the gradient accumulation steps equal to 16 (thus accumulating gradients over 16 batches) we achieve the same effect as having a batch size of 64.
The advantage here is that we can effectively use a larger batch size resulting in more stable updates, better generalisation and faster convergence. However, it might slightly increase training time due to the additional forward-backward passes before each step update and the computational overhead due to the accumulation and storing of the gradients.
Gradient checkpointing
Usually, during back-propagation, gradients are calculated recursively using the saved intermediate activations from the forward pass. As the number of layers in a model increases, this could create a significant memory overhead due to the need to store all these intermediate activations.
Gradient checkpointing reduces the memory requirements for back-propagation by selectively recomputing some of the intermediate activations during the backward pass, rather than storing them all in memory. While this technique can reduce memory usage, it increases computation time since we need to recompute some intermediate activations. Therefore, this technique poses a trade-off between memory usage and computation time.

Mixed precision training (FP16)
FP16 mixed precision training is a technique for training deep neural networks that uses half-precision floating-point (FP16) arithmetic for some parts of the training process. The idea is to use the lower precision format to speed up the training process while still maintaining a reasonable level of accuracy.
In FP16 mixed precision training, the model's weights are stored in FP16 format, which takes up half as much memory as the standard FP32 format. During forward and backward passes, the activations and gradients are also computed in FP16 format. However, some computations (such as the weight updates in the optimiser) may still require the higher precision of FP32 and hence a master copy of the FP32 weights are stored too.
A drawback is that this low-precision data type is more susceptible to numerical instability potentially leading to gradient underflow and gradient overflow. Gradient underflow occurs when the gradients become too small to be represented in the low-precision format, underflowing to zero and resulting in a loss of information. Gradient overflow on the other hand occurs when gradients become too large to be represented in the format, leading to NaN or infinite values. This problem can be addressed by performing gradient clipping (prevent gradient explosion) and (dynamic) loss scaling.

8-bit Adam optimizer
The 8-bit Adam optimizer is a memory-efficient variant of the Adam optimiser. The 8-bit version uses quantised values with 8 bits instead of the full-precision 32-bit values used in the standard version hence reducing memory footprint while maintaining the performance levels of using 32-bit optimiser states. The quantised values are used to store the optimiser state at a lower precision which will be dequantized during the optimisation process only. This is similar to the idea behind FP16 training where using variables with lower precision saves memory.
While we have discussed various techniques for fitting a large model on a single GPU, another approach is to leverage Deepspeed ZeRO's offloading capabilities, which we will discuss in the following section on multi-GPU training. Multi-GPU training is typically used when model training is too slow or the model parameters cannot fit in a single GPU’s memory. In such a setup, the work is distributed across multiple GPUs, leveraging some form of parallelism, such as data parallelism or model parallelism.
Data parallelism and model parallelism
Data parallelism (DP) involves replicating the same model across multiple GPUs, with each device training on a different subset of the training data. Gradients are then averaged across the devices to update the model parameters. Since the model is replicated on each GPU, it will not reduce the memory per device, however it will allow for larger batch sizes as the workload is distributed across multiple devices.
In contrast, model parallelism (MP) involves splitting the model across multiple GPUs, with each device responsible for computing the forward and backward passes for a specific part of the model. MP enables training of larger models that do not fit on a single GPU by partitioning the models, but comes with increased communication overhead slowing down training. Furthermore, it is essential to load balance the partitioning of the model in such a way that each device is working on an equal amount of work.

Deepspeed ZeRO
ZeRO (Zero Redundancy Optimiser) is a set of memory optimisation techniques for effective large-scale model training.
Let’s start with one of ZeRO's functionalities that can also be used in a single GPU setup, namely ZeRO Offload. ZeRO Offload allows offloading the optimiser memory, gradients and model weights to CPU or NVMe, thereby freeing up GPU memory and enabling the training of models that would otherwise exceed device memory. However, it is important to note that this may induce slower training times due to additional communication overhead. In general, it is best to avoid using ZeRO if the model can fit on a single GPU while still allowing a decent batch size since it only might slow down training. As soon as the model won’t fit on a single GPU or the batch size that can be used is too small, then it would be beneficial to use CPU/NVMe offload.
ZeRO has 3 main optimisation stages:
- Stage 1: partition the optimiser state across multiple GPUs
- Stage 2: add gradient partitioning across multiple GPUs
- Stage 3: add parameter partitioning across multiple GPUs
ZeRO-3 is likely to be slower than ZeRO-2 (if the configuration remains the same) because the former needs to gather the model weights on top of what ZeRO-2 does. If the model is large, but can still be trained using ZeRO-2, it is generally recommended to use ZeRO-2 as it will result in faster training times than ZeRO-3. However, note that ZeRO-3 has a much higher scalability capacity, but comes at the cost of slower training times.
ZeRO-3 is further extended by the addition of ZeRO-Infinity. ZeRO-Infinity comes with the infinity offload engine allowing the support of massive model sizes on limited resources by exploiting both CPU and NVMe memory simultaneously. Furthermore, it introduces memory-centric tiling, a technique that supports extremely large individual layers that would otherwise not fit in GPU memory even one layer at a time. Additional functionalities include bandwidth-centric partitioning for reducing bandwidth costs and an overlap-centric design for scheduling data communication.

As always, here too, there is a trade-off between memory usage and speed. In general, we could say the following holds true:

Conclusion
In this article, we covered a range of techniques to overcome the common issue of running out of GPU memory when training large models. From gradient accumulation, checkpointing and mixed precision training to 8-bit Adam optimiser and Zero Redundancy Optimiser, we explored various options for fitting large models on a single GPU as well as distributing the workload across multiple devices in a multi-GPU setup. Ultimately, the choice of technique depends on the specific requirements of the project, and a balance between training speed and memory usage must be carefully considered.
These techniques can eventually democratise machine learning by enabling the training of large models on a single GPU or by distributing the workload across multiple GPUs. This can make it easier for researchers and organisations with limited resources to participate in the development of state-of-the-art models, and can ultimately lead to more innovation and progress in the field of machine learning
You might also like



Resources:
https://huggingface.co/docs/accelerate/usage_guides/deepspeed
https://huggingface.co/docs/accelerate/v0.11.0/en/deepspeed
https://github.com/microsoft/DeepSpeed
https://www.microsoft.com/en-us/research/blog/zero-infinity-and-deepspeed-unlocking-unprecedented-model-scale-for-deep-learning-training/
https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
https://www.deepspeed.ai/tutorials/zero/#offloading-to-cpu-and-nvme-with-zero-infinity https://huggingface.co/docs/transformers/main_classes/deepspeed#gradient-accumulation
https://huggingface.co/docs/transformers/v4.18.0/en/performance#dp-vs-ddp
https://huggingface.co/docs/transformers/v4.18.0/en/parallelism#zero-dppptp
https://towardsdatascience.com/i-am-so-done-with-cuda-out-of-memory-c62f42947dca
https://oracle-oci-ocas.medium.com/zero-redundancy-optimizers-a-method-for-training-machine-learning-models-with-billion-parameter-472e8f4e7a5b
https://towardsdatascience.com/understanding-mixed-precision-training-4b246679c7c4