

By Nicolas Jankelevitch
The rootsacademy, some believe it's as unrealistic and imaginary as Hogwarts, but nothing is further from the truth. This mythical academy really exists and turns wild partying scholars into professional consultants that are experts in the magical world of data.

After the academy, most employees start working for their first client. For those who haven't found a match with a client yet (or for those whose project will only start in a couple weeks time, like myself) there is the rootsacademy project. This is an internal project in which the participants can gain their first experience, making them even more prepared to start working at a client.
The project
The goal of the project is to implement a traffic monitoring solution in AWS that implements vision transformers with Hugging Face according to best practices. This means implementing, testing and maintaining the model and infrastructure with a set of services that improve the robustness and resilience.
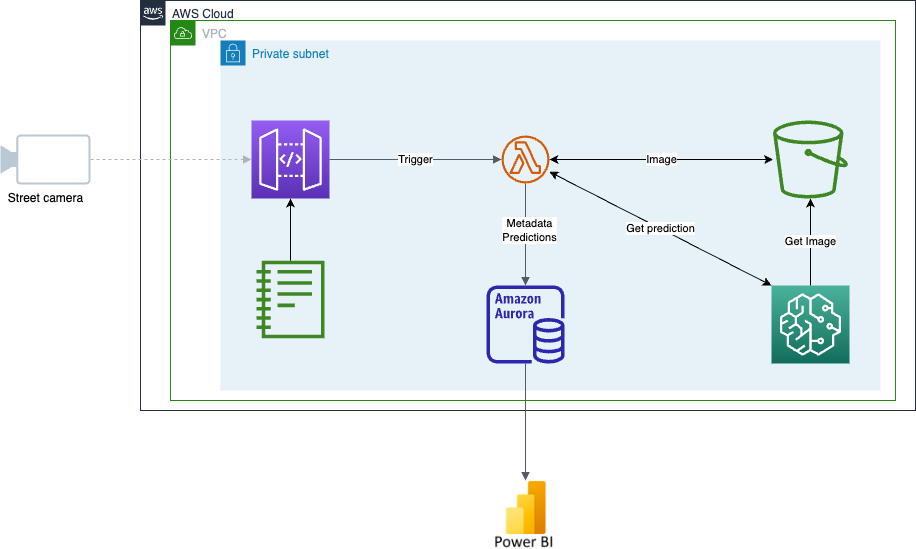
The architecture we used consists of an API gateway, a Lambda function, an S3 bucket, a sagemaker instance and an Aurora RDS database. Images come in through the API gateway, which triggers the Lambda and passes the image and the name as a variable.
e.g. tiensevest_Leuven_Belgium_12-10-2022_10-51-38.jpg
The lambda function has a couple of duties. The first is to extract the metadata from the name of the image and store it in the aurora database as separate values (address, city, country, date, time). Next it does a small check on the image if it isn't distorted. In case it is distorted, the image is written to a separate folder in the s3 bucket and an error message is returned to the API. Then the image is stored in the s3 bucket with as name the id of the metadata in the aurora database. Next the location of the image in the s3 bucket is sent to the Sagemaker endpoint. The endpoint returns the bounding boxes of all the items that it detected in the picture (e.g. a car). These are then returned to the lambda function. These predictions then get aggregated and stored in the aurora database and the image gets annotated with the bounding boxes of the relevant items. The model detects a wide range of items, but in this use case we are only interested in cars, trucks, busses, people, bikes and motorcycles. The rest of the detected items are ignored. Finally the aggregated data is visualised in a Power BI dashboard.
Lambda speed
The duration of the Lambda averages around 2.75 seconds excluding the first run. When a Lambda function is called without an instance of the lambda existing, or when number of requests can't be handled by the existing instances, a new instance is initialised. The first time this new instance runs will take a bit longer than the runs after. The time it takes to initialise varies between 1 and 3 seconds for this lambda. Since we want to do realtime inference, +-3 seconds is a long time. We will now talk about a couple of options to bring this number down.

Optimizations
Code optimizing
The first and easiest way to speed up the process is by optimising the Python code of the lambda. Each time the lambda function is triggered, it will run the "lambda_handler" method. In this method all the work should be done, so in this case write to the database, trigger the Sagemaker endpoint and write to the S3 bucket. All variables are also initialised inside this function (or functions called by this function)
import x
import y
def lambda_handler(event, context):
do all the work
What we do now is initialise all the variables every time the lambda function is triggered, this means also the variables that will stay the same for all calls like for example the Sagemaker endpoint client. Initialising this takes time and this is where the easiest optimisation comes in. Everything that can be reused by each lambda should be initialised just once and be reused by all subsequent calls. The code would then look something like this:
import x
import y
sagemaker_runtime_client = client("runtime.sagemaker")
s3 = client('s3')
...
def lambda_handler(event, context):
do all the work except the initialisations
Besides the Sagemaker endpoint and s3 client, also the initialisations for the Aurora database connection where moved. This resulted in a time around 2.4 seconds, which is a gain of a little over 0.3 seconds.

 |
 |
 |
|---|
Add compute power to the sagemaker endpoint
As mentioned earlier, calling the Sagemaker endpoint takes by far the most time. So speeding up the endpoint would mean speeding up the lambda! 📈 Since we're using a Hugging Face model, there isn't anything we can do in the model itself to speed it up. What we can do is make the model do inference faster by giving it more resources. The speed tests where done on instance type ml.m5.large. If, for example, we would upgrade to ml.m5.xlarge, the endpoint would have double the amount of cpu & memory allocated. A downside to this is that it would also double the cost.
Sometimes all you need is a million euros -me
But will this actually speed up the inference? What I originally saw as an obvious fix was actually proven not to be, very quickly. When we look at the memory and CPU utilisation we can clearly see that after a small stress test of 20 calls to the endpoint, we're not even close to maxing out the resources of the endpoint.
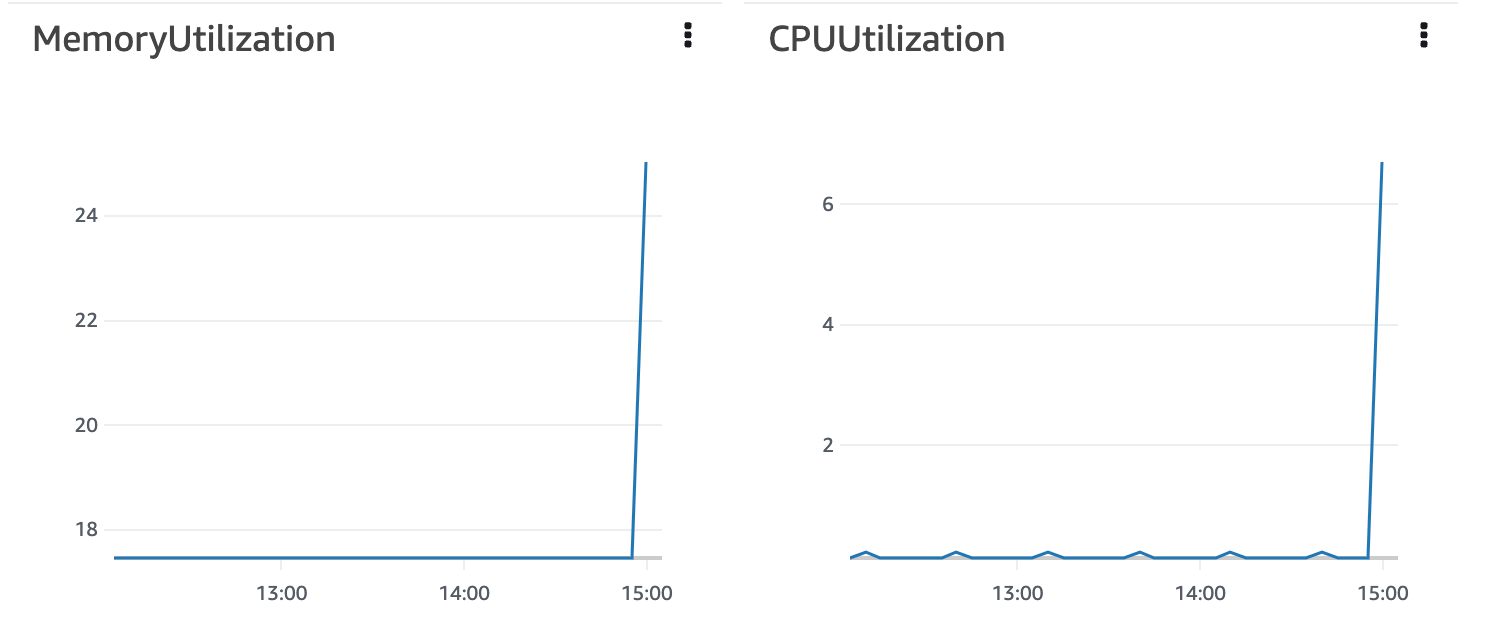
Adding more resources would then just mean that we would be able to do a lot more concurrent calls, but it wouldn't speed up the individual inferences.
Using a VM with GPU's instead of CPU might be a better option than just increasing the number of CPU's and memory. This option was not tested though.
Change the architecture
Since the code optimisations didn't cut enough of the time and the nature of the model prevents us from speeding it up, it is time to look at more drastic measures to get a faster response from the API. Since the project was limited in time this alternative wasn't implemented, but it is an option in case someone continues working on the project later on.

What happened now is that the lambda is split in 2 separate lambdas. The first lambda now only handles the image check and calls the endpoint to get the predictions. It then triggers a second asynchronous lambda that handles the writing to s3 and the aurora database so it doesn't have to wait for this and can immediately send the response to the API gateway.
Now you're probably thinking "wow this Junior forgot about the fact that the Sagemaker endpoint needs the link of the image in the s3 bucket".
The reason we decided to sent the location in the s3 bucket instead of the image itself is because of a shortcoming in the used model. It doesn't work with images of the latest PIL version and it happens that we use the latest version. The model does, however, work with older versions of the PIL package. For this architecture to work, we would then use an older version of the package and make some changes to the Sagemaker endpoint so it no longer expects the s3 bucket link but a PIL image.
Conclusion
The rootsacademy, and by extension the rootsacademy project, are a great way to kickstart a career in the world of data. You gain valuable insights that will make the first weeks at a first client easier. During the project everyone has had to deal with unforeseen problems that occurred by choices or assumptions we made. Luckily the best way to learn is from making mistakes. It's important to always keep in mind the big picture when making decisions and try to foresee possible unwanted side-effects of those decisions so you can proactively avoid them becoming a problem.
You might also like

