

By Kevin Missoorten
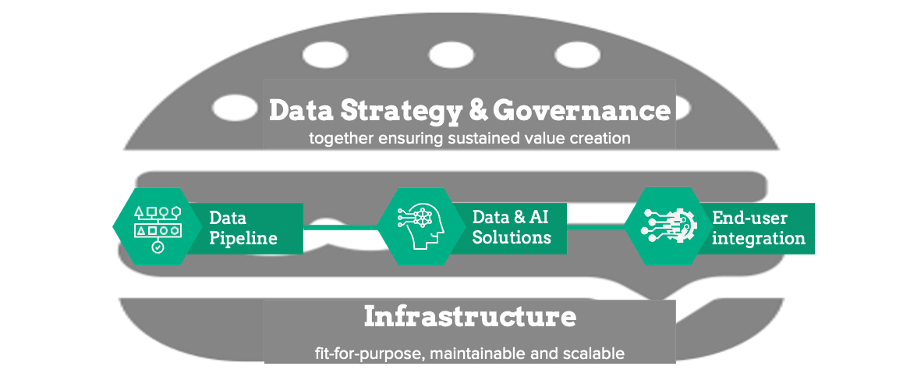
At dataroots, we like to present our service portfolio by means of a burger.
Like a burger, the ‘pièce de résistance ‘ is the Artificial Intelligence value-chain, with data pipelines transporting & providing quality data from source to model, simple or complex models mashing the data into insights and finally integration of those insights into the day to day business processes to put these hard earned insights to work.
Also like a burger, the way to facilitate the efficient consumption of the actual meat or vegan hamburger with all of its delicious juice and sauce, is by means of a solid data architecture to transport the data - the bottom slice of bread.
The data & AI strategy and governance is there to ensure direction and to keep the data in check - hence the top slice of bread.
Like a burger, industrialised AI requires all these components to work in sync, focusing on the individual components would be either very messy or very dry.
The perception is that AI and Data Science are the most challenging piece of that puzzle – it’s true that this is often very complex. Yet, from experience we have learned and continue to see that strangely enough this is often not the most blocking challenge.
We actually see 4 recurring challenges when it comes to industrialising AI:
- First, the solutions are not customer centric, so value is missed
- Secondly, a lack of data literacy slows down adoption
- Third, monolithic teams and platforms reduce time to insight
- Finally, teams miss the bigger picture of industrialisation and transformation
Challenge 1: Developing solutions without the “customer/consumer in the loop”
To stick to the burger analogy, I don’t know of any burger-place where the waiter tells the cook what burger to make based on assumptions about the customers’ taste. I do know of some data teams that only involve the customer at the very beginning and the very end.
Recently I was lucky enough to facilitate a workshop with a client that is so close with their clients, the clients truly inspire every product feature, customers test every feature before release, and I was amazed by the quality of the initial product and the true product mindset for the data component of the product – they didn’t think in use-cases but in data products with a roadmap of incremental feature releases.

To deliver value for the consumer of a data product – whether that’s a dataset, a dashboard, or a complex AI prediction, you need to involve the client at every step in the process – not via proxy-product-owners but as actual product owners. This is the only way to ensure the effort invested is focused on the most value adding insights.
Lack of data literacy
I recently heard someone say: ‘technology is the easy part, it’s the processes that are hard and it is the people who are impossible’. It stuck with me. The AI tech and processes are there but when you want to involve your stakeholders, you need to make sure you find a common tongue, that business understands enough about how data & AI works and what is possible for them to give relevant requirements and feedback. Even worse, if they don’t understand, they won’t trust the solution and thus they are unlikely to use and adopt it. This “understanding” of how the data and AI value chain works and high level how the models work is what we mean with data literacy. This requires investment in dedicated info sessions. These will generate immediate ROI as people become more conscious of the impact of inputting bad data and even more as adoption of AI solutions picks up.

Important to note that it's not a one-way street. It’s not only the business who needs to learn the data team's language. It's also the data team who needs to search for a common tongue with business. Having data scientists focus on a business domain will definitely help. Furthermore, explainable AI (X-AI) is a field in AI that is actively trying to translate models in a way that for example deep learning “black box models” can be explained and reviewed with business without going into complex statistics. The learnings this will generate on innate bias will likely have a profound impact on the ethics of business, exciting!
Challenge 3: Relying too much on monolithic teams and platforms? Why not Mesh it up!
This closing of the gap between business and data & analytics is also noticeable in the way data & analytics is organised corporately. As information is power and thus a risk, for decades organisations have invested in a central and secure data ecosystem but as every system from every business unit in an organisation generates valuable data these days, data literally comes from everywhere and needs to go everywhere. Put a central piece in the middle and you inevitably get a bottleneck.

This construct – a logical step 10 years ago – in today’s digital world tends to create frustration with both the consumers who suffer slow time-to-insight and the data team who are under constant pressure.
The recent advent of the data mesh provides a promising and elegant alternative that combines central enablement – both on architecture and governance - with decentralised autonomy. For many in the field - and certainly for me -, Zhamak’s presentation resulted in an “aha” moment followed by the thought “this makes perfect sense, why didn’t anyone come up with this sooner?”.
This governed decentralisation will radically accelerate the pace at which business processes get enhanced as data literate business teams with business literate data experts jointly build smart customer optimised solutions.
Challenge 4: Missing the bigger picture of industrialisation and transformation
The proliferation of data and analytics today is not always performed with industrialisation in mind. Due to the intrinsic experimental nature of AI - many organisations still suffer from the PoC syndrome or pilot purgatory: many organisations are actively exploring AI but don’t seem to be able to make it past the PoC or pilot phase. Often because they set out to build a PoC, so their tunnel-vision means they don’t prepare to take the concept to the next level.

By adopting/defining an MLOPS framework, organisations can provide data scientists with a clear best-practice path from experimentation (cfr PoC/pilot) to deployment and Industrialisation.
This is a crucial framework to develop today as - as mentioned earlier - tackling the challenges of business involvement and decentralisation will likely result in an acceleration of data and AI solutions. No organisation wants to run behind the facts in setting up data and AI governance when that tidal wave hits!
To wrap up (pun intended)
As you can read, much like a good burger requires much more than the hamburger in the middle, delivering a successful AI use-case is about a lot more than the data & the AI alone. It's about the users' needs and their buy-in, its about governance and flexibility, its about solid production enabling frameworks and much more.