

By Ilion Beyst, Arnaud Fombellida
When it comes to scaling out Python workloads, the landscape is filled with options. Among the prominent choices available today are PySpark, Dask, and Ray. As these systems differ significantly in their design and approach, capabilities and benefits, determining the optimal fit for your specific use case can be difficult.
In this blog post, we aim to provide clarity by exploring the major options for scaling out Python workloads: PySpark, Dask, and Ray. By understanding the differences and nuances between these systems, you can navigate the complexities of scalability and select the best-suited framework.
PySpark
Spark was conceived as a more flexible and more performant alternative to MapReduce.
The main abstraction in Spark is the Resilient Distributed Dataset (or RDD). It represents an immutable collection of values, divided into a set of partitions. Internally, an RDD is represented as a plan to compute its partitions.
Such a plan can be built by either reading data from stable storage, or by applying a transformation to existing RDDs. This way, a partition can always be recomputed in the event of data loss (eg. due to node failure). This is what makes the RDD resilient.
As a consequence, not all partitions of an RDD have to be materialized at all times. In fact, Spark will attempt to delay materialization for as long as possible, only doing computation on your data when you request to perform an action on it, such as collecting a result or persisting data.
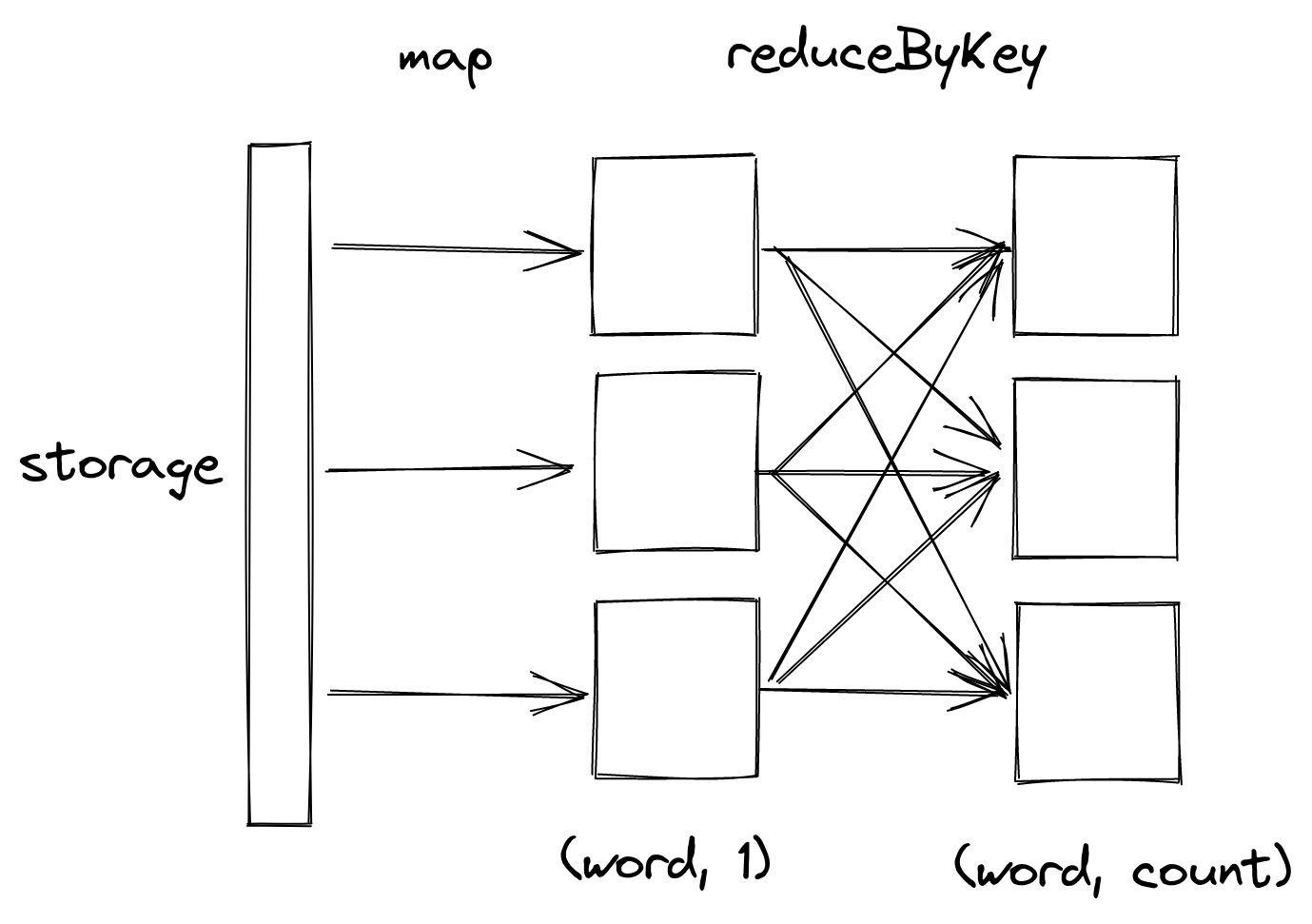
Due to this design, partitions, not individual values, are the level of granularity in Spark. It is thus best suited for course-grained bulk processing, where you apply the same operation to a large amount of values.
On top of this core, Spark offers a SQL and DataFrame API for working with structured, SQL-style tabular data. These are more sophisticated than just putting a set of records in an RDD: structured operations are expressed as a logical plan, which then get translated into an RDD-based physical plan by Sparks Catalyst Optimizer.
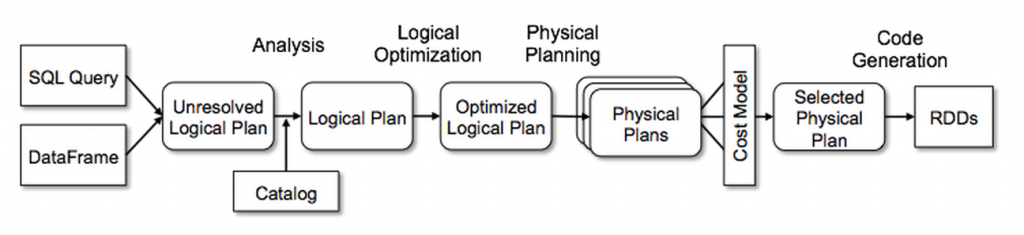
When you want to do bulk processing of tabular data, Spark is certainly a solid choice.
When using Spark with Python, there are a few caveats:
First of all, since Spark runs on the JVM, using user-defined functions written in Python requires an additional serialization/deserialization step, which can result in significant memory and compute overheads. Since Spark 2.3, it is possible to alleviate this with Pandas UDFs, using Apache Arrow for in-memory serialization of dataframe chunks.
Secondly, the PySpark API is not fully feature-par with the Java and Scala APIs. It is for example not possible to implement custom readers, writers, or aggregators in Python. For aggregators, Pandas UDFs can again be helpful: GROUPED_MAP type UDFs allow for implementing a split-apply-combine pattern: df.groupBy(..).apply(grouped_map_udf).
Dask
Dask is a library for natively scaling out Python - it's just Python, all the way down. It was initially created to be able to parallelize the scientific Python ecosystem.
At its core, Dask is a computation graph specification, implemented as a plain python dict, mapping node identifiers to a tuple of a callable and its arguments. Identifiers of other nodes can be used as arguments, creating edges.
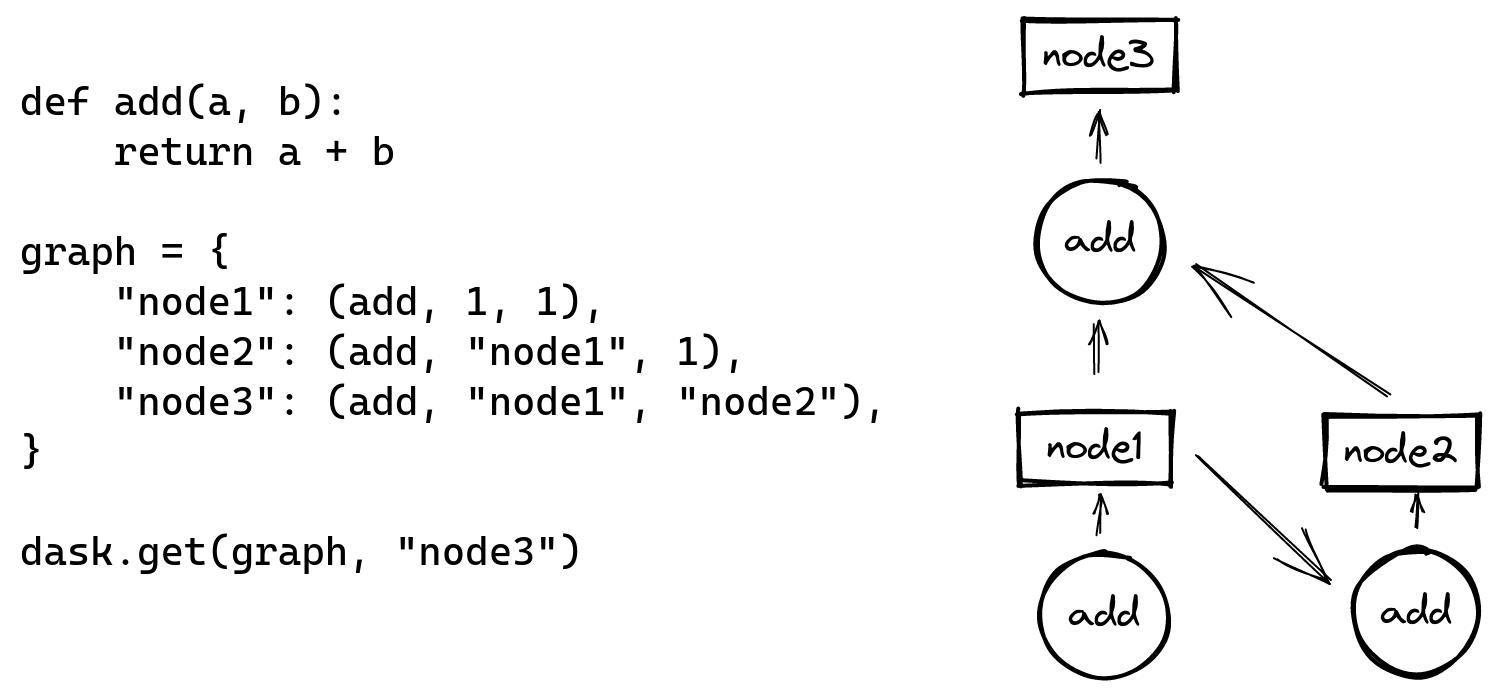
In this graph, nodes represent computations, and edges represent plain Python values. Users are not expected to write these graphs by hand - they should serve as a common format that is output by higher-level APIs. Dask comes with a few of these, the simplest is the delayed API:
@dask.delayed
def add(a, b):
return a + b
a = add(1, 1)
b = add(a, 1)
c = add(a, b)
c.compute()
The other higher level APIs allow manipulating distributed collections: bags as generic collections of objects, dataframe for structured data (based on pandas), and array for blocked arrays (based on numpy). Note that Spark does not have support for blocked arrays.
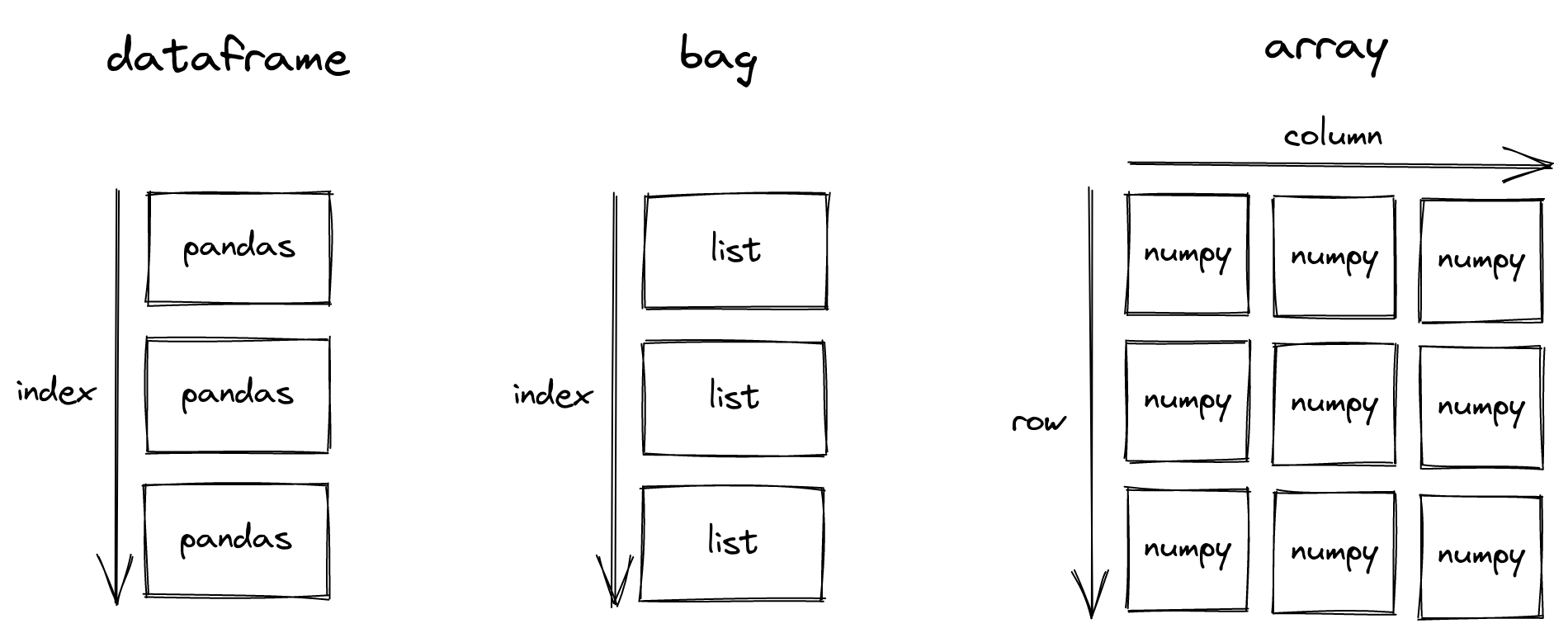
This design allows Dask to leverage the existing PyData ecosystem, and offer seamless integration with these libraries. On the flipside, this means Dask also inherits the downsides.
Dask is a great choice when you need tight integration with the Python ecosystem, or need some more flexibility than Spark will allow. On the other hand, Spark will usually offer better performance, as it has a logical optimizer and a more optimized shuffle implementation.
Ray
Ray is a universal library for distributed computing for machine learning workloads. While Spark and Dask are distributed data processing frameworks which you can use to build machine learning pipelines, Ray is a framework that focusses on building distributed machine learning pipelines. It is made of 6 libraries that make up the Ray AI Runtime (AIR):
- Data: Scalable, framework-agnostic data loading and transformation across training, tuning, and prediction.
- Ray Train: Distributed multi-node and multi-core model training with fault tolerance that integrates with popular training libraries.
- Ray Tune: Scalable hyperparameter tuning to optimize model performance.
- Ray Serve: Scalable and programmable serving to deploy models for online inference, with optional microbatching to improve performance.
- Ray RLlib: Scalable distributed reinforcement learning workloads that integrate with the other Ray AIR libraries.
These different libraries are built on top of Ray Core which defines the core abstractions for the distribution of workloads. These workloads come in 2 flavours: Tasks and Actors. A task is an arbitrary Python function which can be run on a worker. An actor is stateful task which is pinned to a worker. Actors can be used to run inference on a model, with the model being part of the state of the actor. Both tasks and actors allow defining specific CPU and GPU requirements to control on which workers they get scheduled on.
Ray Data is the library of AIR that provides the data loading and transformation features. The core construct is a Dataset which his a list of references to blocks. Each block holds a set of items in either Arrow table format or as a python list.
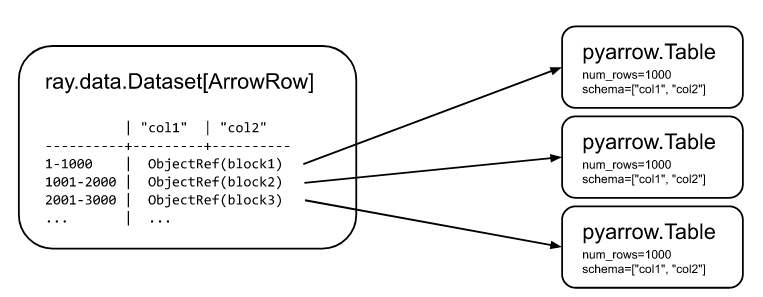
Similarly to Spark, operations on a Dataset are executed lazily and fault tolerance is achieved by rebuilding a block if it is lost. However, that's where the similarities with Spark stop. Ray does not focus on being a tool for building complex ETL pipelines. Instead the focus is on building scalable machine learning applications. As such, the features provided by Ray Data are fairly limited. For example, it is not possible to join 2 Datasets. However, Ray provides integrations with other tools such as Spark and Dask to efficiently transfer data to those tools and let them deal with complex operations.
Ray is a great choice if you want scale out the training and serving of machine learning models across multiple nodes. If the various libraries of AIR are appealing to you, Ray can be a great choice. However, if you are only looking to build data pipelines with no interest for machine learning, Ray will most likely not match with your goals.
Spark vs Dask vs Ray
The offerings proposed by the different technologies are quite different, which makes choosing one of them simpler.
Spark is the most mature ETL tool and shines by its robustness and performance. Dask trades these aspects for a better integration with the Python ecosystem and a pandas-like API. Ray on the other hand focusses more on the scaling of machine learning workloads with data processing being a side feature.
Do you need distributed data processing ?
Distributed data processing frameworks come with a lot of overhead. You need a compute cluster with worker nodes and all of that is infrastructure that you need to manage, unless you rely on a cloud offering. Computationally, overhead is also introduced by the need to manage the distribution of the workloads and deal with fault tolerance. To quote the Dask Documentation:
If you are looking to manage 100GB or less of tabular CSV or JSON data, then you should forget both Spark and Dask and use Postgres or MongoDB.
Many alternatives exist for single node data processing. The most popular is probably pandas, but other solutions are available. If your data is too big to be loaded into in memory with pandas, Vaex can be an alternative thanks to its lazy out-of-core DataFrames while keeping a pandas-like API. If sticking to the pandas-like API is not something you're looking for, polars is a new DataFrame library written in Rust with a Python API. If you like to think from a database perspective first, DuckDB is a single file database system optimized for OLAP workloads. Finally, if you have GPU's available, cuDF will allow you to leverage them.
You might also like

 dataroots
dataroots