

By David Backx, Martial Van den Broeck
Objective
The landscape of data technology is continuously evolving, with new and promising technologies emerging each month. To evaluate the maturity, interoperability, and overall compatibility of some of these innovations, we developed a project that integrates four main technologies into a streamlined proof of concept (POC).
Specifically, our objective was to utilize Prefect for automating the data quality tests in our project, which were conducted using Soda. We stored our data both locally in DuckDB and in the cloud with MotherDuck. Additionally, we conducted data analysis using YData Profiling and visualized the results with PowerBI dashboards.
We designed the system to perform checks automatically when a polling flow detected changes in the data source. It was also important for us to preserve the results of the checks and the profiling data as markdown artefacts after each flow.
The upcoming blog post will elaborate on our efforts. We will start by briefly introducing the tools used, describing their functions, and outlining the overall architecture of the project. Subsequently, we will delve into a detailed examination of each tool to clarify our choices. To conclude, we will share the key insights gained from this project.
Tools
We will list and describe each tool used in our project here. You will find a brief description of each tool accompanied by an explanation of its role in our architecture.
Prefect is the central component of our PoC. This orchestration tool has been around for six years and has gained significant traction recently, thanks to its ever-growing community. As you might have guessed, we used it for orchestration, but also for its array of impressive features, which we will discuss later. For this project, we utilised the cloud version of Prefect.
Soda, a Belgian data quality tool, has attracted considerable attention since its debut in 2018. It offers a free, open-source solution called Soda Core, and a managed cloud solution. We employed it to conduct data quality checks and to establish data contracts for our data sources.
DuckDB is an OLAP SQL database known for its high performance and ease of use. It can be installed locally for free and has been available for five years. MotherDuck, a managed cloud service for DuckDB, was released last year. It provides a serverless analytics platform where notebooks can be utilized to interact with data. We used these two tools as a data warehousing solution for our project.
YData Profiling is employed at the initial stage of the data science workflow: data exploration. It enables the creation of dashboards to aid in the exploratory analysis of data in a comprehensive yet straightforward manner. With just a few lines of code, you can gain invaluable insights. Released eight years ago, it is our oldest tool; we used it to profile our data, which helped in defining the Soda checks.

Prefect
Flows
Flows are pivotal in Prefect, serving as the main containers for workflow logic. You can configure your workflows within these flows, which are essentially Python functions. Any Python function can be transformed into a flow, which acts like a large building block where all components of your workflow are integrated.
Tasks
Tasks are the building blocks used to construct your flow. They are essential for piecing together your workflow and can be easily monitored within Prefect, providing a clear view of workflow progress.
Artefacts
In Prefect, artefacts refer to any outputs that are persisted once a flow completes. These could be markdown documents, tables, or hyperlinks—each stored as a result of specific flows.
Workpools
Workpools and workers are critical for executing your deployments in Prefect. When a deployment is scheduled, it is assigned to a workpool. This workpool determines the infrastructure that will run the deployment, with workers then executing the task. For instance, in a local workpool, workers continuously poll for new deployments and activate them as scheduled. We initially used a local workpool for our Docker images but later switched to Azure Container Instances for better scalability. Prefect’s push service further optimises this process by eliminating the need for worker polling, instead scheduling Azure containers directly to manage the Docker images.
Beneath you can find a picture that illustrates the way workpools and workers work together.
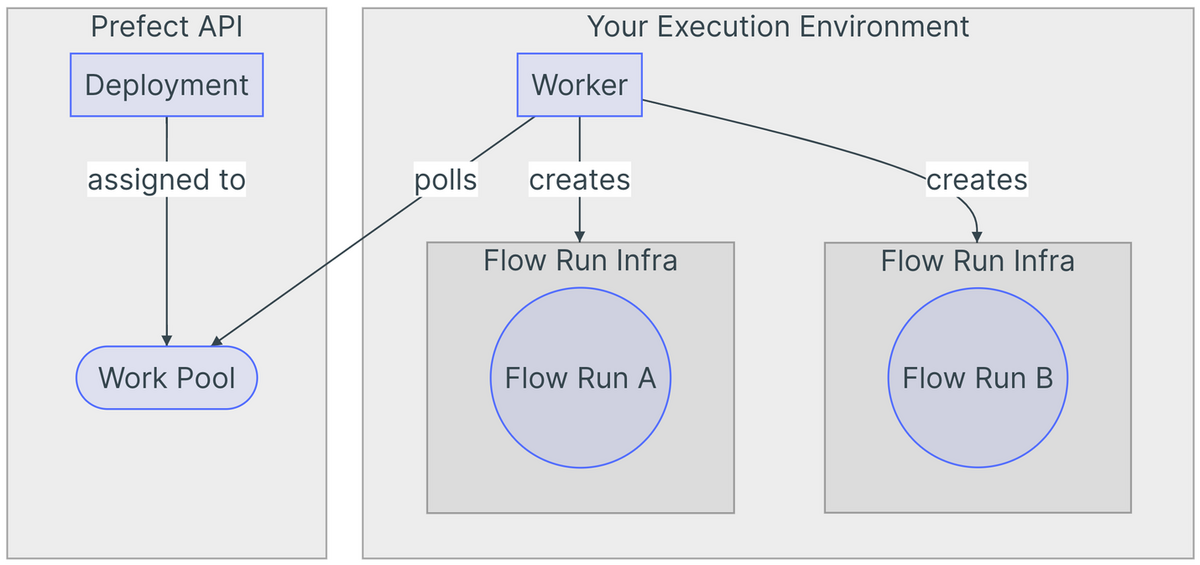
Usages
In our project, we leveraged the aforementioned elements as follows:
- We created four distinct workflows using flows and tasks:
- Polling MotherDuck tables for data changes.
- Running checks when changes are detected to ensure data integrity.
- Executing a data contract to verify schema consistency.
- Tasks were used to perform Soda scans and to convert the results into Markdown for our artefacts.
Deployment
We began our deployment with local Docker images but transitioned to Azure Container Instances to enhance efficiency and scalability.
Takeaways
Prefect proved to be an extremely useful tool for managing and scheduling pipelines, easy to integrate into our existing Python knowledge base without the need for extensive new technical skills.

Soda
What is Soda?
Soda is a data quality assessment tool that analyses your data sources to identify discrepancies or irregularities. It acts as a diagnostic tool, providing insights into potential issues and enforcing data quality standards.
Features
Soda offers extensive features for data quality analysis:
- Checks: These are conditions set to ensure data meets specific standards. For example, you can define data contracts to maintain schema quality.
- Integration: Soda seamlessly integrates with various data sources, including AWS Athena, Snowflake, Databricks, and BigQuery, among others.
- Cloud Option: Allows additional monitoring through logs from your data scans.
Soda Checks
Soda Checks simplify the process of setting constraints on your data. Users specify restrictions in a YAML file, such as minimum and maximum values for a data column (e.g., age between 1 and 100). Soda then converts these specifications into SQL queries, thus requiring no SQL knowledge from the user. This feature is particularly beneficial for those unfamiliar with SQL.
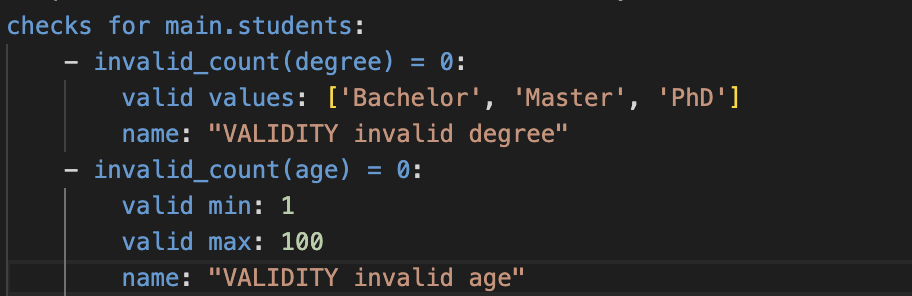
The file is a description of the checks you want to execute so again you don’t need to write your own SQL checks (but you can if you want).
Configuration
Soda requires a YAML configuration file for each data source. For simple setups like DuckDB, specifying the file path suffices. However, more complex data warehouses like Snowflake demand detailed information, such as username, password, and warehouse specifics. This configuration is crucial as it enables Soda to convert checks into SQL queries and access the data source.
Data Contracts
Soda's experimental "data contracts" feature allows users to enforce schema standards in their data source. You can also include checks within the data contracts to prevent null values or restrict data to specified allowable values.
Usages
Soda was used to verify that data on MotherDuck was consistent with the local DuckDB database. We also added additional data quality checks over the data we had.
Takeaways
The most significant advantage of using Soda is its ease of use. Implementing Soda in your data pipeline does not require advanced technical skills, making it accessible for integrating valuable data quality checks efficiently.

DuckDB & MotherDuck
What the duck?
DuckDB is an in-process OLAP engine that, until recently, lacked a cloud solution for sharing data with other analysts and stakeholders. MotherDuck has been introduced to simplify the operation of your lakehouse. The typical workflow involves the following steps:
- Data Extraction: Pull data from MotherDuck.
- Transformation Development: Develop and build your transformations locally using DuckDB.
- Local Testing: Test these transformations in your local DuckDB environment.
- Pushing Changes: Upload these transformations to MotherDuck.
- Table Creation: MotherDuck then processes these transformations to create new, transformed tables.
This process allows you to collaborate effectively with others by primarily using your own computer to develop data transformations. It also helps maintain a clear separation between development and production environments, enhancing workflow efficiency. For more information, you can see previous Dataroots posts like What the duck!? And Herding the Flock with MotherDuck: your next data warehouse?
Usages
In the context of our project, we utilized MotherDuck as our data warehouse and DuckDB as our primary tool for data ingestion, transformation, and querying. We relied on the cloud data stored in MotherDuck as our source of truth, while using DuckDB to query and modify this data. Additionally, Soda was integrated with DuckDB, and by extension, MotherDuck, enabling us to conduct data quality checks on both local and cloud-stored data.
Unfortunately, DuckDB does not have a feature to notify users of changes in the tables, nor does Prefect have a mechanism to detect changes in external services automatically. As a workaround, we implemented a short, regularly scheduled job that polls MotherDuck for any changes. This setup allows us to determine the appropriate times to run checks. Fortunately, due to the high efficiency of these tools, the entire process—from checking for changes to running the necessary checks—takes less than two minutes, with most of this time accounted for by the container start-up.
Takeaways
DuckDB and MotherDuck work seamlessly together. Their simplicity and the speed of query execution allow us to experiment with new and complex data pipelines without the need for numerous intermediary microservices. A single token facilitates the connection to MotherDuck, and installing just one library is sufficient to begin querying and operating our local database.
However, MotherDuck is relatively new and its documentation can be challenging to navigate or incomplete. For instance, we would benefit from a feature that triggers webhooks following specific table actions, which would enhance integration with external tools like Prefect.
YData-Profiling
Concepts
YData offers a one-line code solution designed to facilitate a consistent and rapid Exploratory Data Analysis (EDA) experience. It provides comprehensive analytics, including variable statistics, correlation matrices, scatter plots, and more. Below is a brief overview of the HTML report generated by YData.
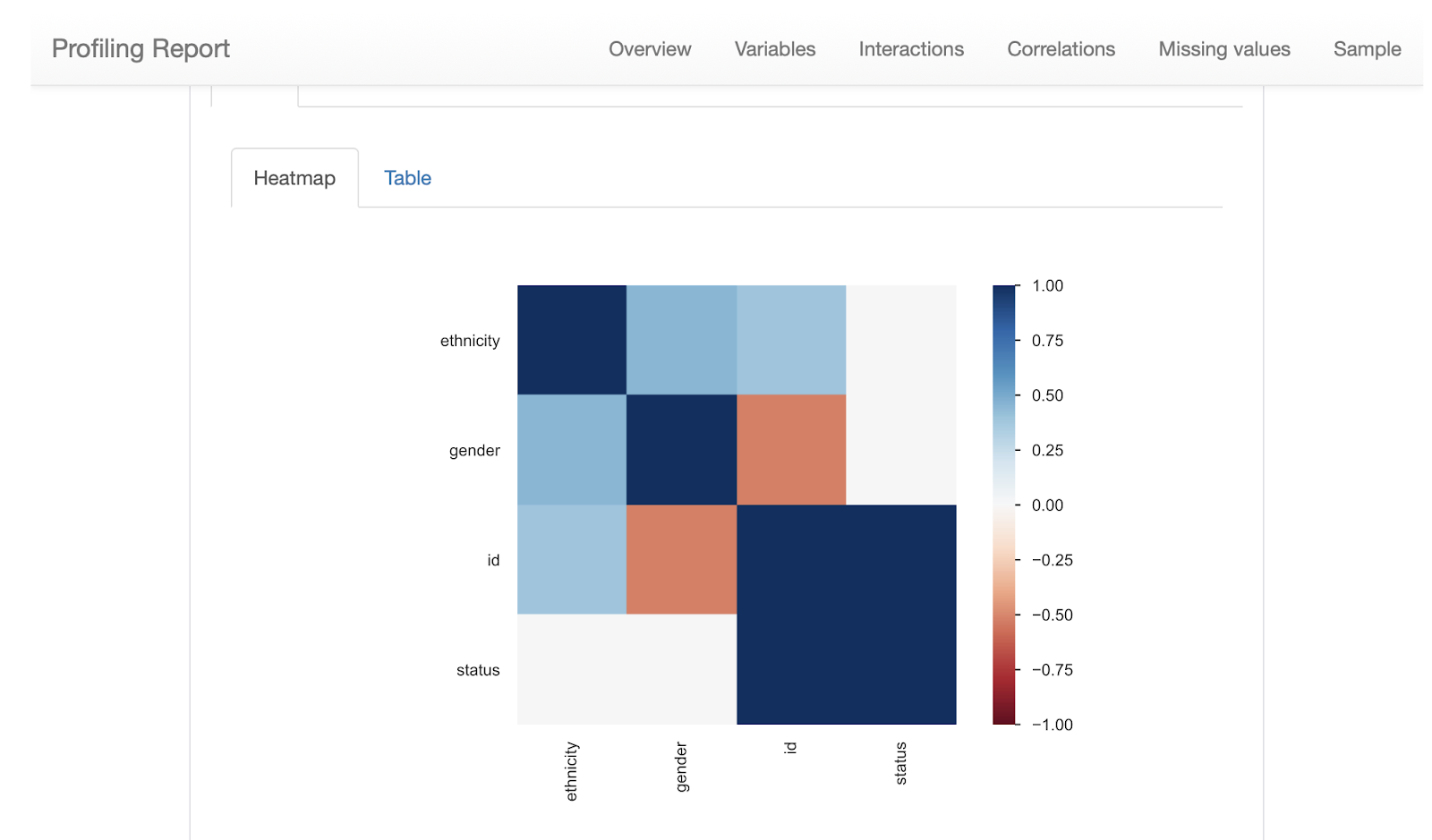
Usages
We introduced a new flow in Prefect designed to generate data profiles periodically. This feature complements our use of Soda by allowing us to monitor data quality more comprehensively. It is particularly valuable for augmenting Soda scans with additional data statistics that are not readily available in Soda itself. For instance, it enables us to determine the skewness of a distribution and incorporate this metric directly into the Soda scan.
Takeaways
Simple and efficient—those are the key advantages of this tool. However, there is a minor drawback: the reports are only generated in HTML or JSON formats, whereas Prefect requires artefacts in Markdown. While converting JSON to Markdown is possible, the resulting reports can be challenging to read.
Conclusion
In conclusion, our project effectively automated data quality checks using an integrated approach with Prefect, Soda, DuckDB, MotherDuck, and YData Profiling. By orchestrating workflows through Prefect, we monitored changes in data sources, conducted quality checks, and generated detailed data analysis reports.
Soda played a crucial role in enforcing data quality standards and pinpointing discrepancies or irregularities, thereby ensuring the integrity and reliability of our data. DuckDB and MotherDuck were instrumental as our data warehousing solution, enabling efficient querying and data transformation both locally and in the cloud.
Furthermore, YData Profiling enhanced our data oversight by providing comprehensive exploratory data analysis, which supplemented the checks from Soda and contributed additional insights into our data quality.
Thanks for reading!