

By Mustafa Kurtoglu

Hi! I’m Mustafa Kurtoglu, currently doing an internship at dataroots. As part of my project, I explored the open-source version of Unity Catalog released by Databricks in June 2024. I was especially interested in how it could be combined with DuckDB and dbt in a containerized setup.
This blog shares my experience, including what Unity Catalog is, why it matters, and how I used it together with dbt and DuckDB to build a governed analytics environment. I also dive into setup on Azure, a few key implementation challenges, and some thoughts on what works well and what could be improved.
Why use DuckDB?
DuckDB is an in-process analytical database, meaning it runs directly within your application (like Python) without needing a separate server. It's renowned for extremely fast query execution on analytical workloads, is open-source, and incredibly quick to set up and use, making it ideal for local development
Why use Unity Catalog?
While powerful for analytics, DuckDB itself doesn't inherently offer features like centralized governance or multi-user access controls. It primarily operates as an embedded, single-process database. Unity Catalog complements this by providing centralized governance, meaning you get essential features like access controls for your data assets. This helps keep your tables secure, findable, and their usage traceable. Additionally, you can host Unity Catalog's own metastore (which holds all the governance metadata) on your infrastructure of choice, whether on-premises or in any cloud environment.
Why use dbt?
dbt (data build tool) is used for data transformation, testing and the materialization of data models, primarily using SQL. Crucially, by defining dependencies between models, dbt also automatically generates data lineage, providing clear visibility into how data assets are created and related, which complements the governance provided by Unity Catalog.
Together, they offer a governed data analytics platform that is fast and relatively easy to set up. But before we dive into the specifics of the project implementation and a detailed evaluation of Unity Catalog's features, let's first cover some key basics.
What is Data Catalog?
Fundamentally, a data catalog acts as a metadata layer and a centralized inventory for an organization's data assets. You can think of it as a layer on top of your actual data stores.
So, why is it useful? Imagine your data assets reside in different environments or various storage locations. A data catalog allows you to browse these assets as if they were consolidated in one place. This capability significantly boosts data discoverability and strengthens data governance. Furthermore, thanks to the features offered by modern data catalogs, they also play a key role in access management, policy management and data governance.
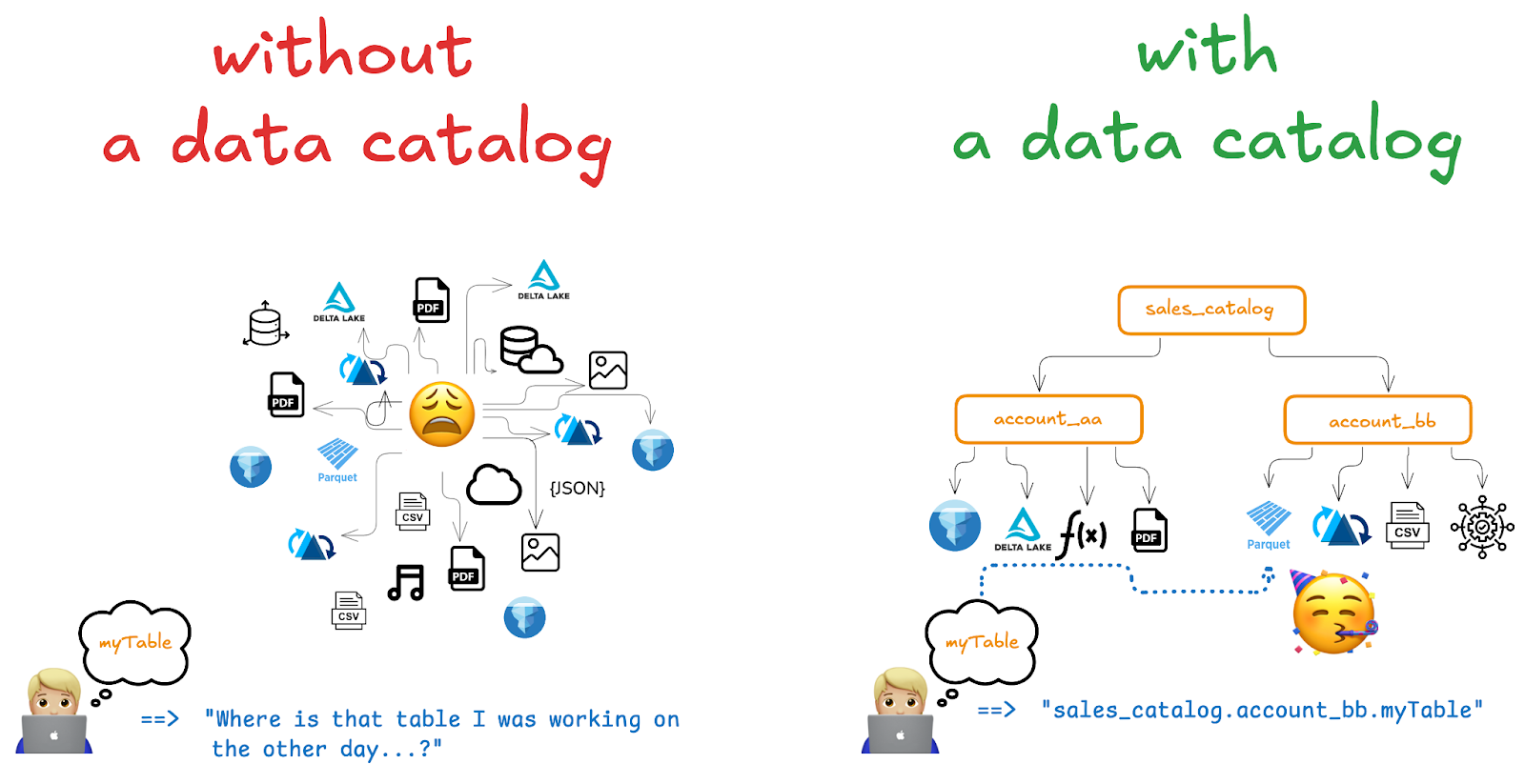
Origin at : https://www.unitycatalog.io/blogs/data-catalog
What is Open Source Unity Catalog?
You may remember the name Unity Catalog from Databricks. This is indeed the open-source version of it. However, while there are many similarities, don't think of it as a direct equivalent to Unity Catalog in Databricks, as the open-source version has quite a few differences. It has two main components for interaction:
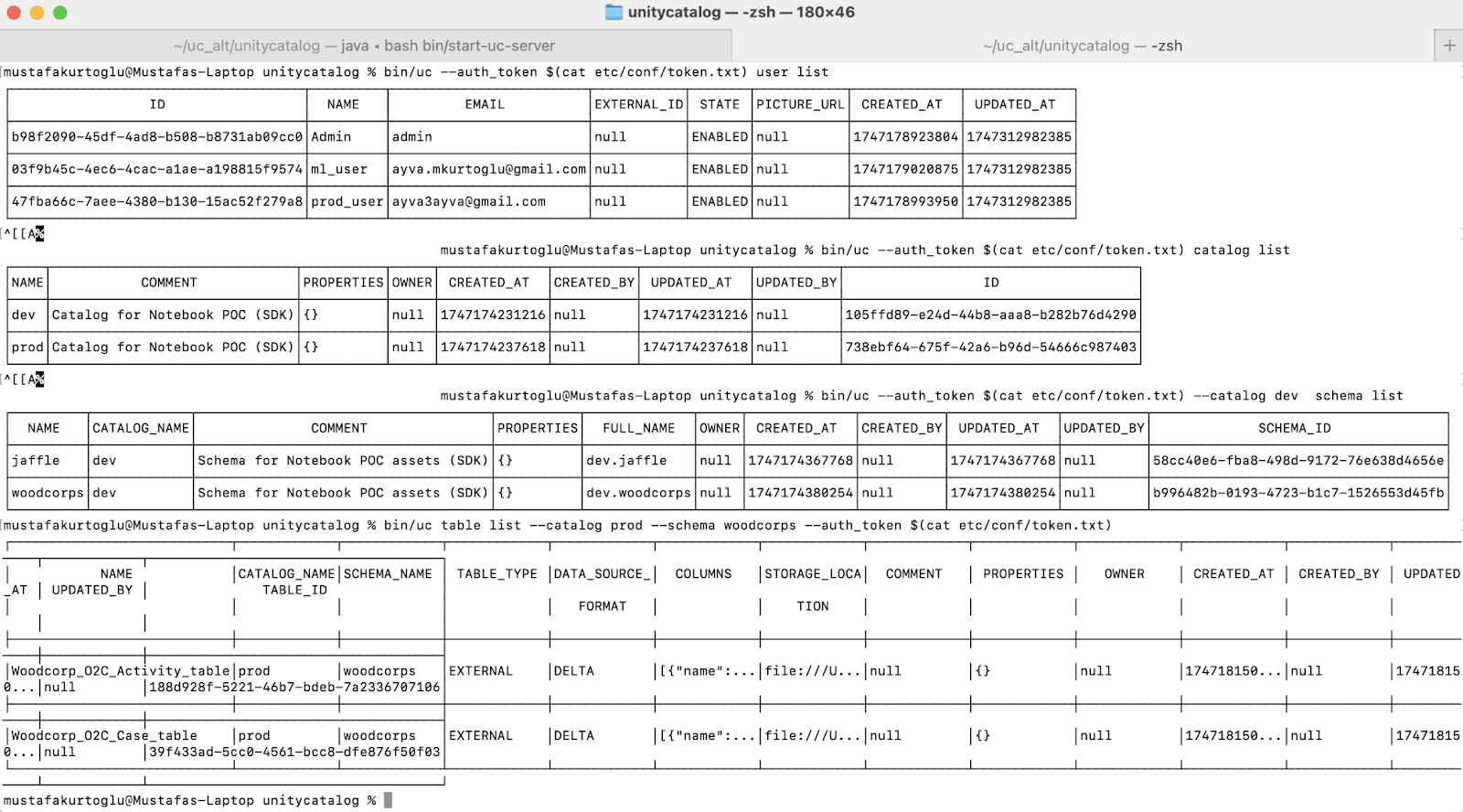
CLI
A Command Line Interface is used to interact with Unity Catalog. Alternatively, a Python SDK can be used but the CLI currently offers more features for certain administrative tasks like creating or listing users.
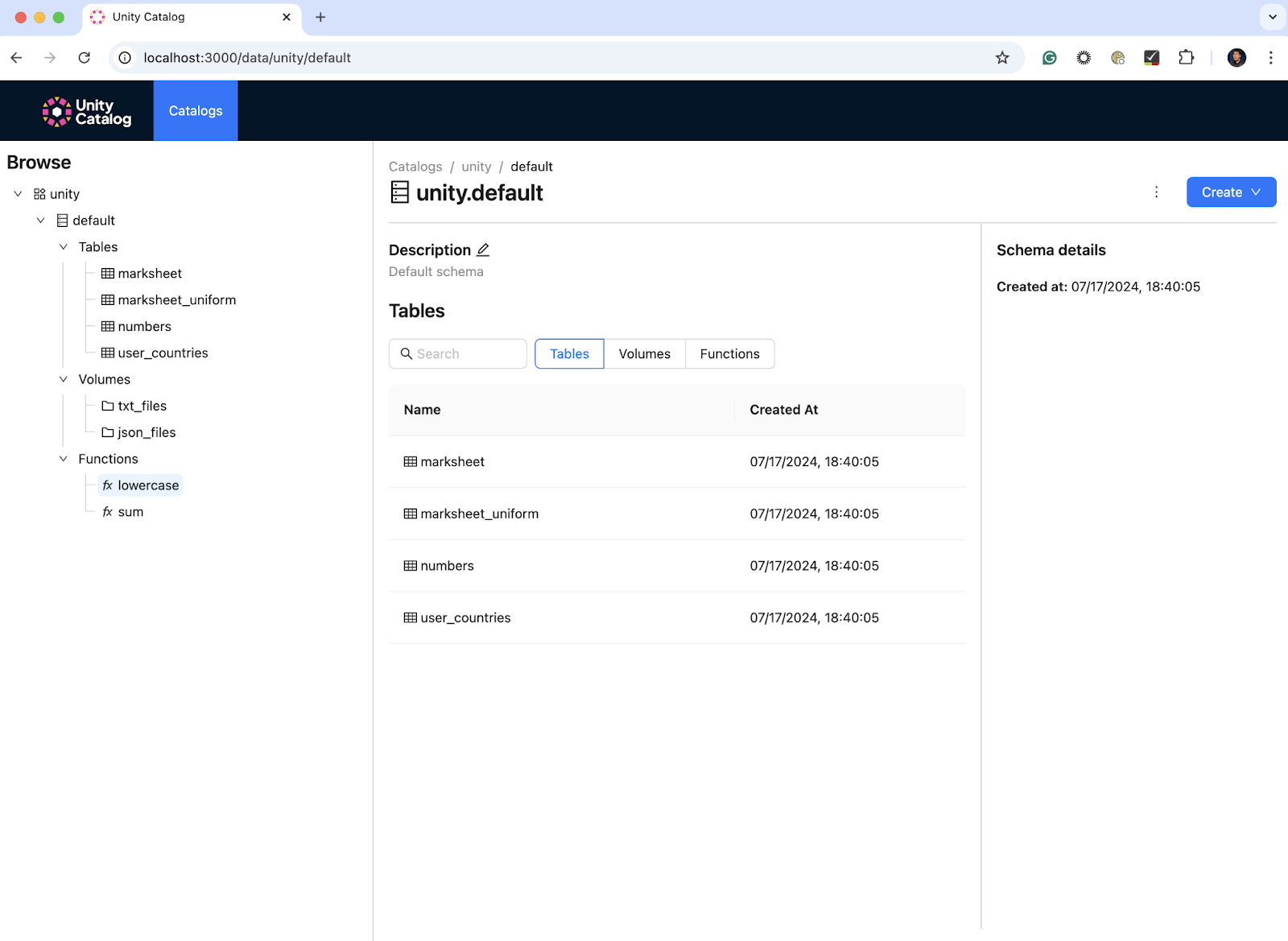
UI:
OSS Unity Catalog has a clean looking user interface where you can browse through all your assets. The main things you might notice (as of version 0.2.0) are the current lack of global filtering capabilities across assets. It also presently lacks the administrative functionalities found in the Databricks UI version, such as direct permission management or lineage visualization. For now, think of the OSS UI primarily as a way to view your assets in a nice and organized way.
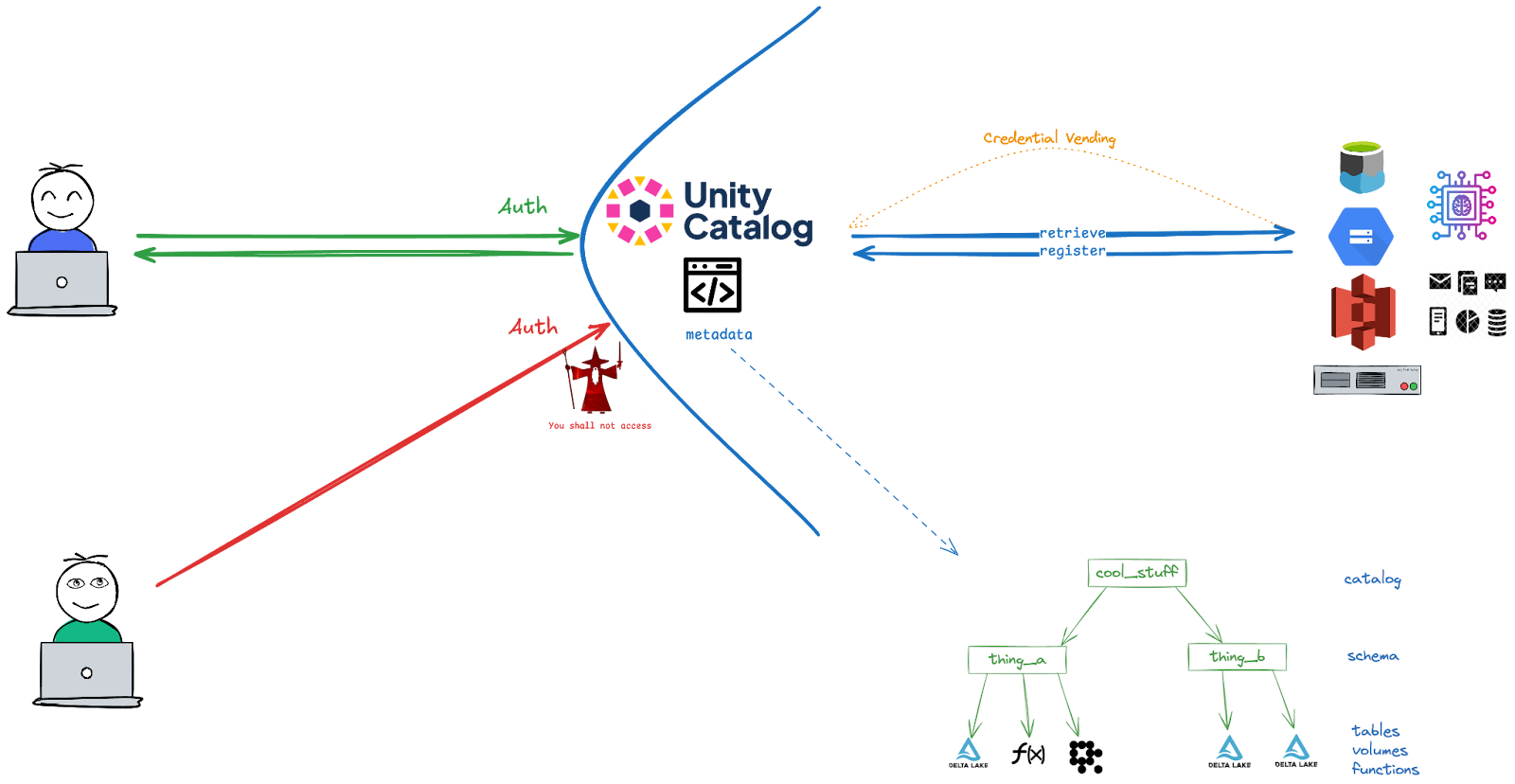
Unity Catalog - Structure
Unity Catalog stores all assets within a 3-level namespace (catalog.schema.asset), a structure you might recognize from Databricks. This design offers complete flexibility, allowing you to organize your setup as it best fits your needs. For example, you could have a single schema for a "dev" or "prod" environment containing all its tables and models, or you might opt for a setup with separate schemas, such as one for tables and another for ml models.
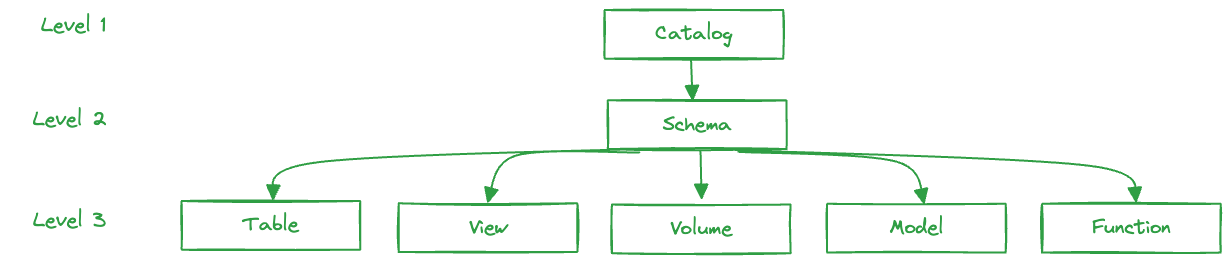
Origin at : https://www.unitycatalog.io/blogs/data-catalog
Unity Catalog - Auth
Authentication and authorization are core components of Unity Catalog. It allows you to manage access to any asset, schema, or catalog registered within it.
For the open-source version, Unity Catalog typically manages its own users and service principals. A user (or application) authenticates to Unity Catalog, often by presenting a token that Unity Catalog itself has issued. This token verifies the identity of the requester.
Once a user is authenticated, authorization comes into play. Unity Catalog is responsible for enforcing permissions. Using the Command Line Interface (CLI) or Python SDKs, administrators can grant specific privileges (like SELECT on a table or EXECUTE on a function) to these users or principals. When an authenticated user then attempts to access an asset, Unity Catalog checks if they possess the necessary permissions for that operation.
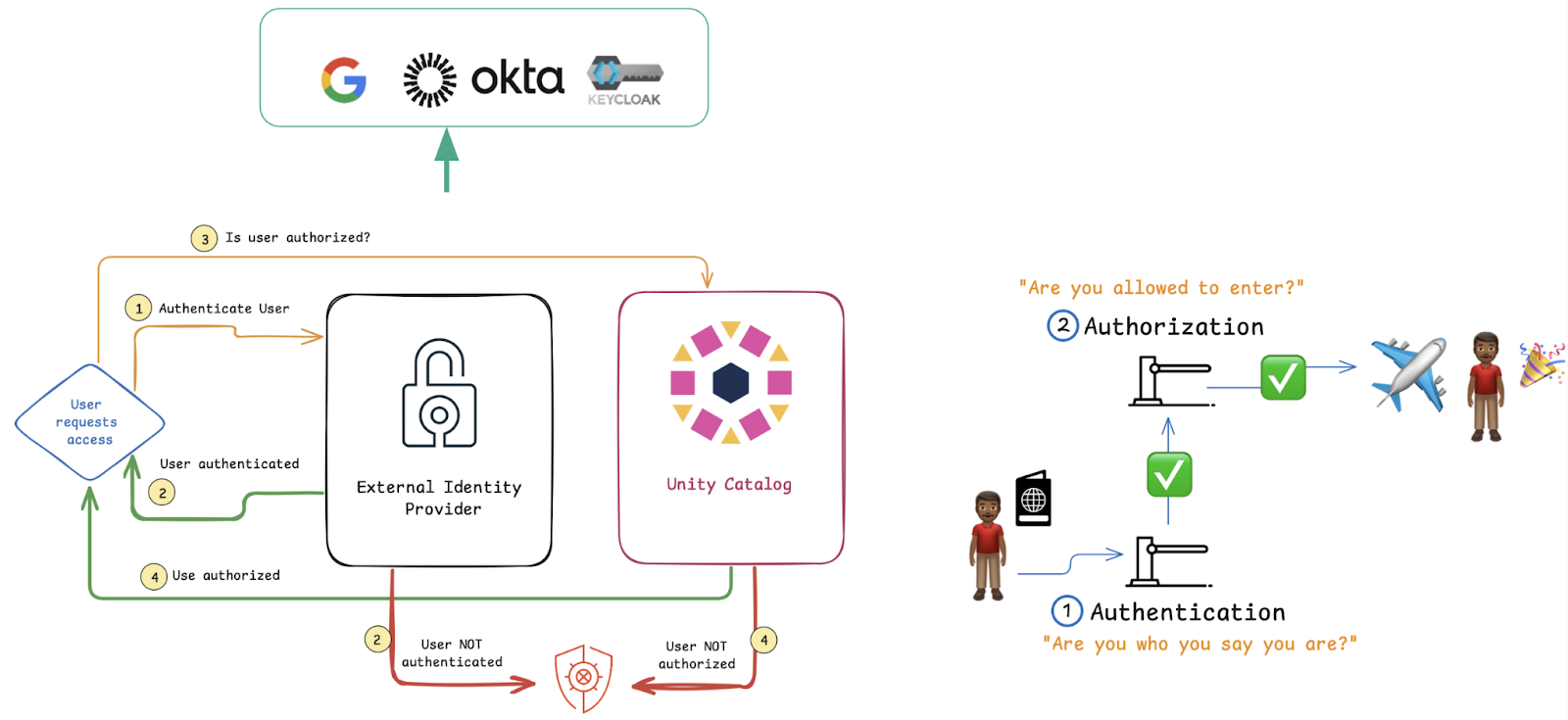
Origin at : https://docs.unitycatalog.io/server/auth/
When managing permissions in Unity Catalog, it's crucial to understand their hierarchical nature. For a user to access a specific asset (like a table or model), they must have the necessary USAGE privileges on all its parent containers in the namespace, from the catalog down to the schema. Below you can see the possible permissions for each level.
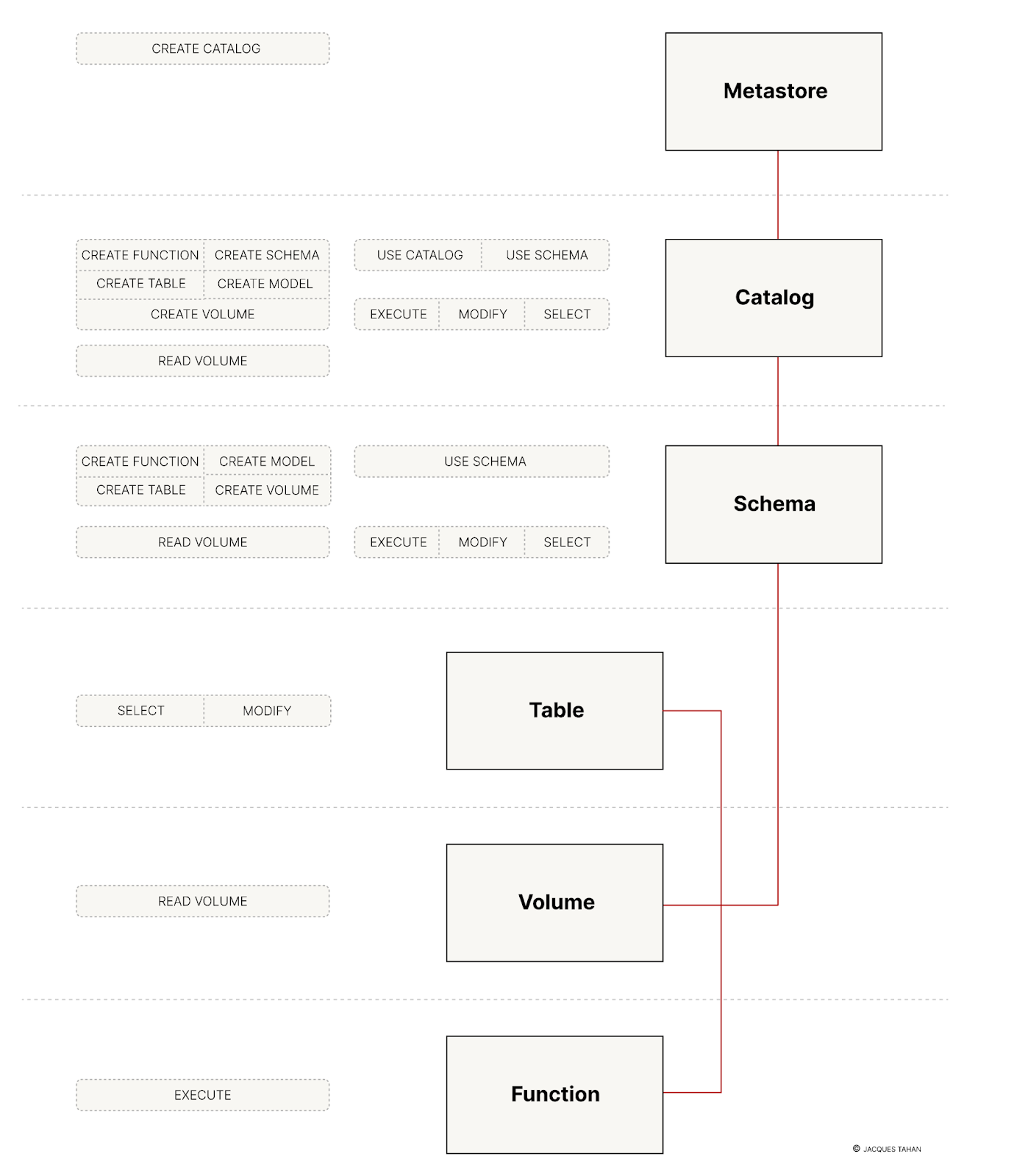
Origin at :https://github.com/unitycatalog/unitycatalog/issues/965
Unity Catalog - AI
Unity Catalog also extends its governance to AI assets. Although this project does not cover all aspects of its AI capabilities, I would like to describe a use case of it with MLflow. In this scenario, MLflow handles experiment tracking: you train your model using MLflow, and after developing a working model, you can register it to Unity Catalog, which then serves as the model registry. A user can then call this model through Unity Catalog if they have the appropriate permissions.
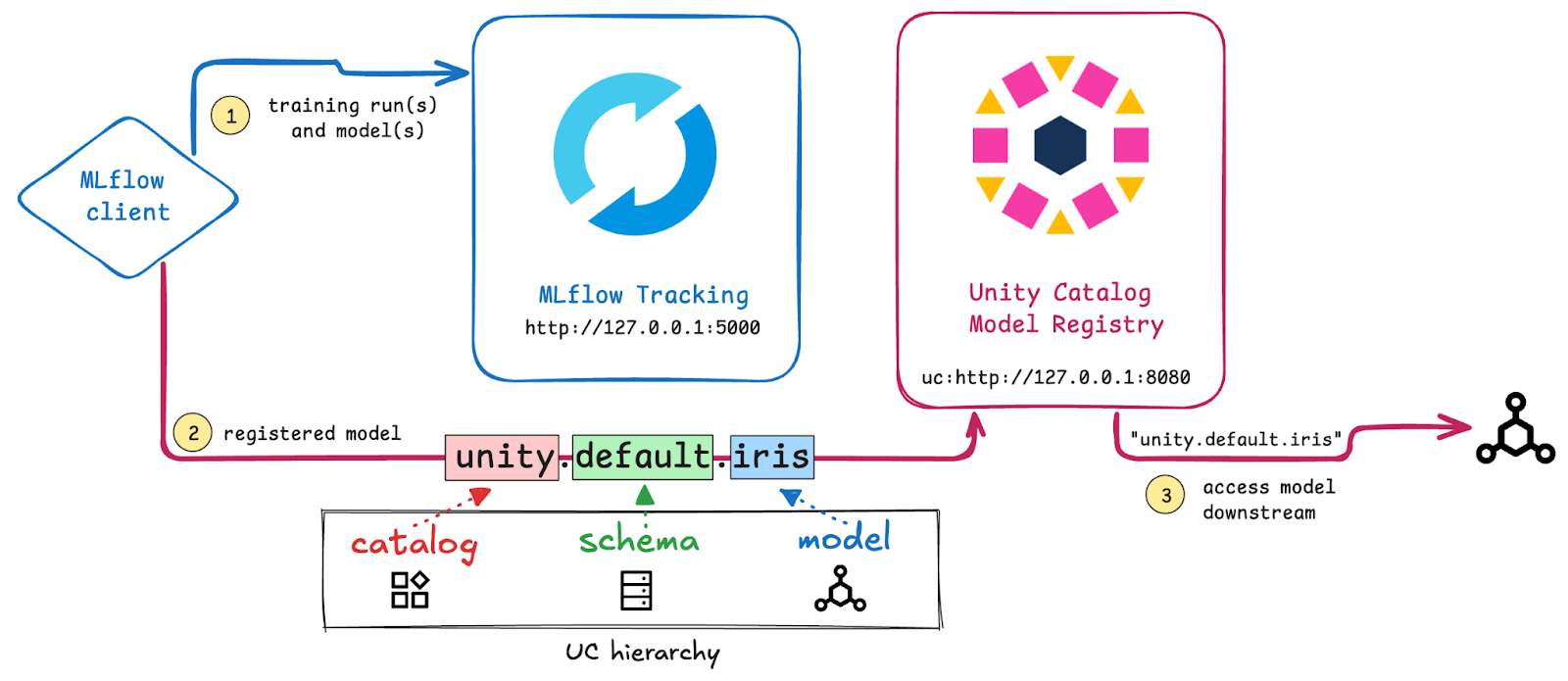
Origin at https://docs.unitycatalog.io/usage/models/
Unity Catalog also supports model versioning. So every time you register a model with a name that already exists, it is registered as a new version. This allows you to call any specific version of your model. With the recent AI 0.3 release there are also additional features and QOL improvements added.
Unity Catalog Project(dbt+azure containers +duckdb)
In the previous sections, I've discussed the general features of Unity Catalog. Now, I want to shift focus to a practical implementation. I have purposefully not talked about following topics :
- The specifics of registering write operations with Unity Catalog
- Querying tables managed by Unity Catalog
- Managing user permissions
These areas can be tricky with the current OSS Unity Catalog. This project demonstrates practical approaches and effective integrations for addressing these specific points.
Docker Setup
This is the initial setup of the project with docker containers. The core data flow is as follows: dbt uses a specialized plugin within its dbt-duckdb adapter to process raw data. It transforms this data and prepares to write the output (as Delta tables) to a designated storage location (cloud-based or on-premise). Simultaneously, this plugin interacts directly with the Unity Catalog server. It registers the table's metadata into Unity Catalog. This integration is vital because the metadata in Unity Catalog must exactly match the physical data.
Once the data is written to the storage location and the metadata is registered in Unity Catalog by dbt, DuckDB (via its UC extension) can connect to Unity Catalog. This allows end users to query the tables through the governed namespace, simplifying data access, especially with tools like the DuckDB UI.
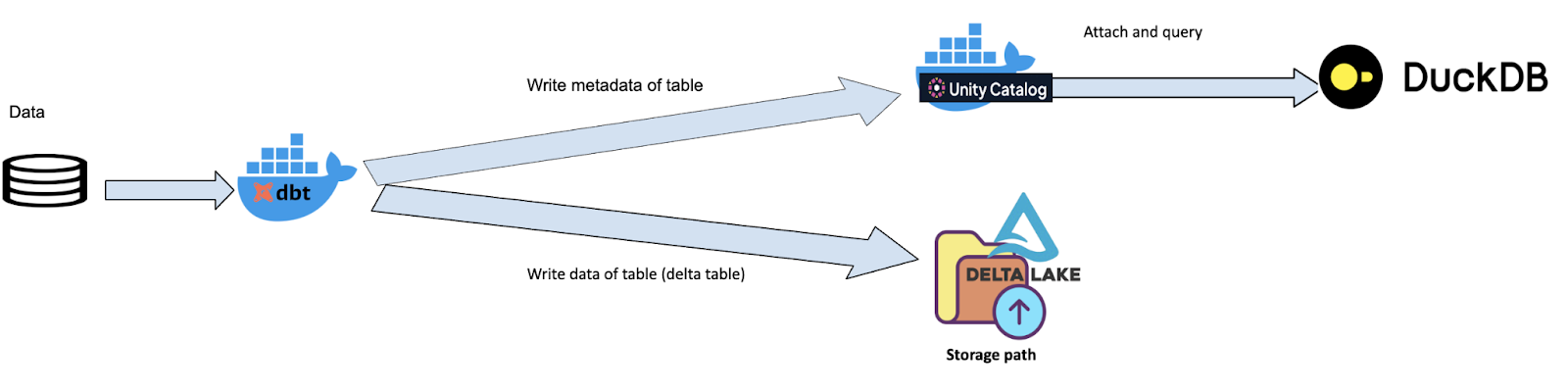
This containerized setup, thanks to the capabilities of the dbt plugin, provides a simple yet effective demonstration of how Unity Catalog's strengths can be leveraged, with dbt automating both the data transformation and the metadata registration into the catalog.
Azure Setup
To deploy and enhance the previously mentioned Docker container setup, I used Azure. Leveraging resources like :
- Azure Container Instances (ACI): Hosts UC server, Permissions Manager, & on-demand dbt jobs.
- Azure Files: Persistent storage for UC metadata & dbt project files.
- Azure Data Lake Storage (ADLS Gen2): Stores dbt-transformed Delta tables.
- Azure Container Registry (ACR): Manages custom Docker images (UC, dbt, Permissions UI).
- Azure Key Vault: Securely stores application secrets (storage keys, UC tokens).
- Azure Functions: Automates scheduled dbt job execution via ACI.
- User-Assigned Managed Identity (UAMI): Provides secure, credential-less Azure AD auth for services.
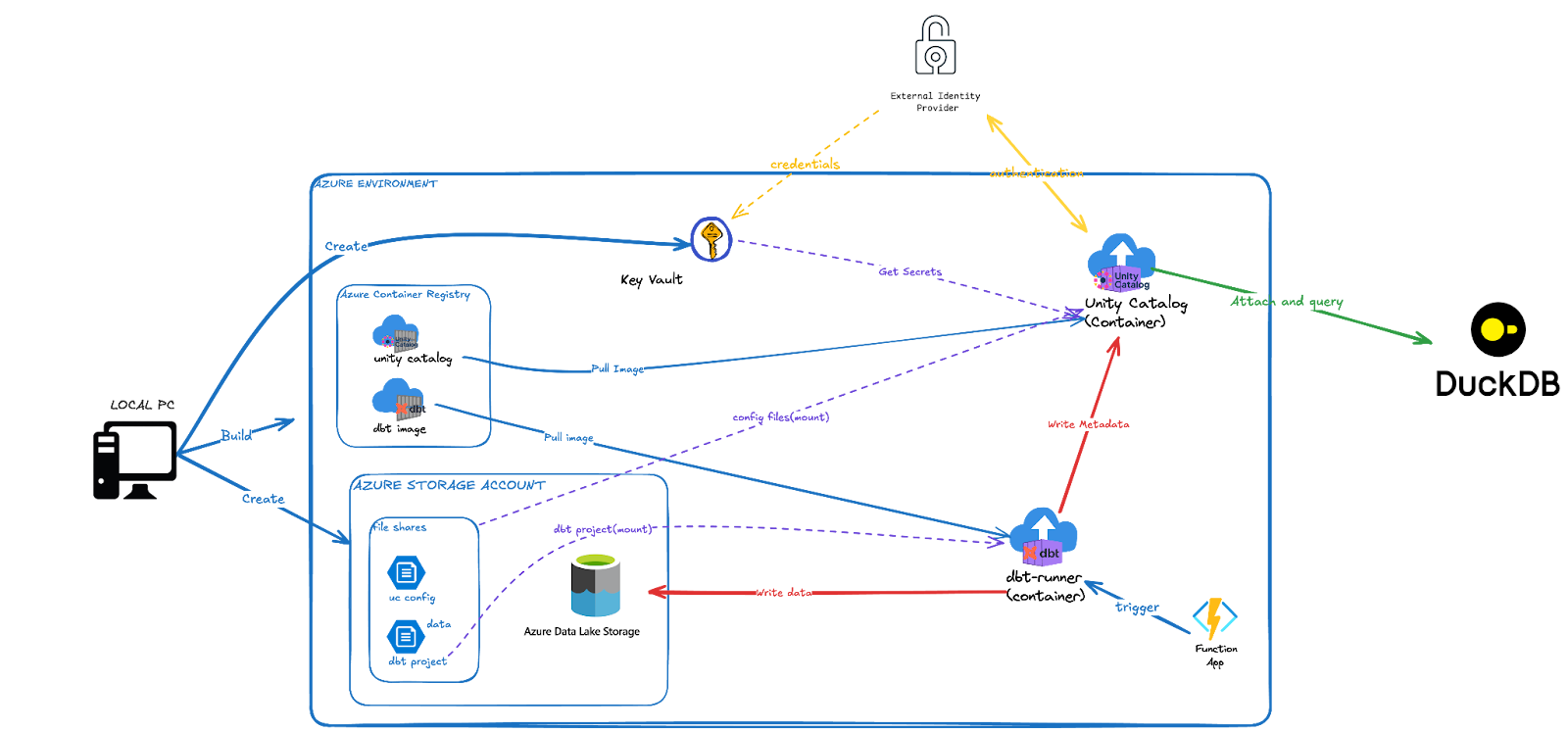
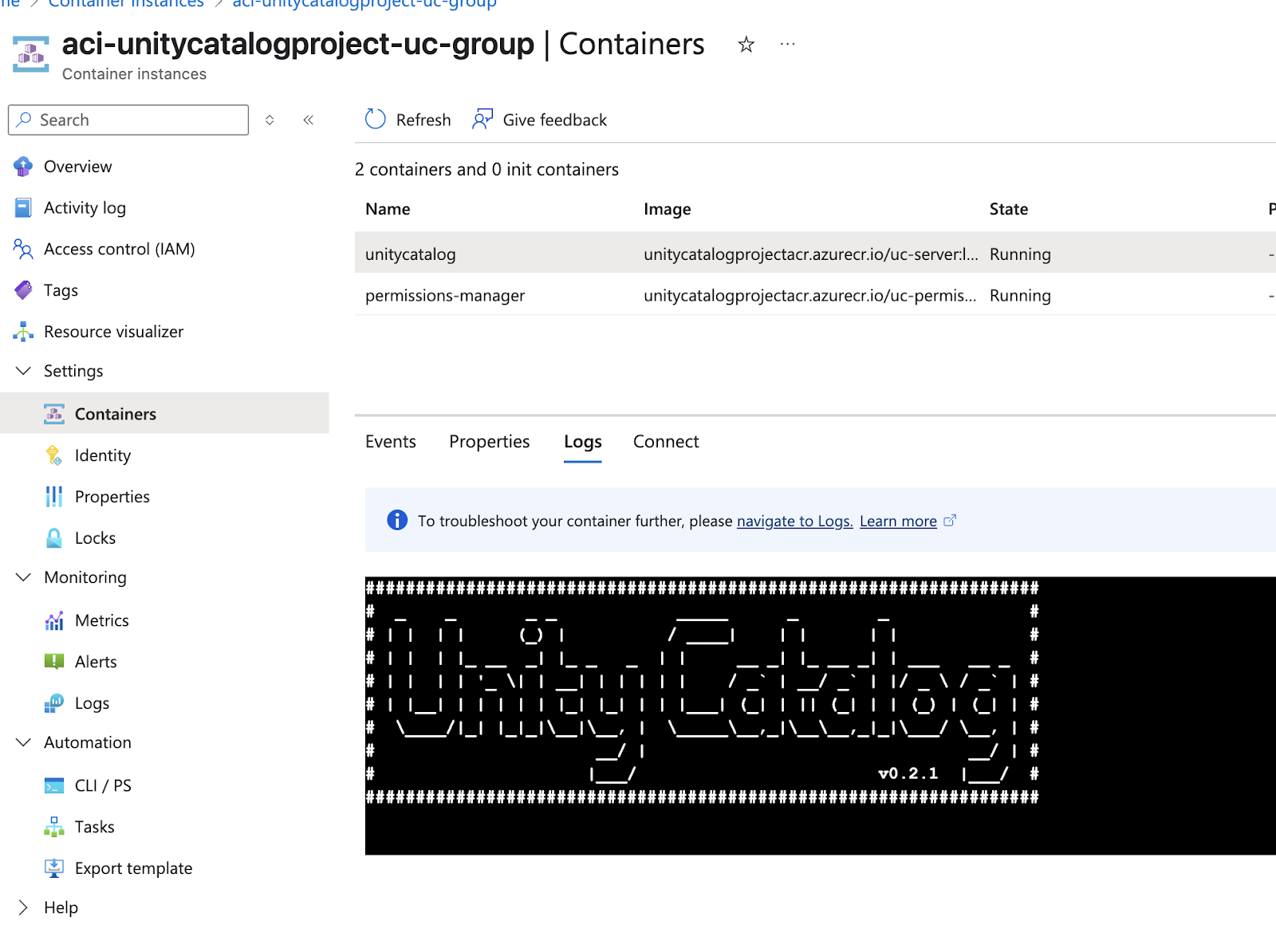
The Unity Catalog server runs continuously in an ACI, its state persisted on Azure Files. This UC server ACI also hosts a simple Streamlit application I developed, which uses the Unity Catalog Python SDK to provide a UI for managing user permissions within UC.
Data transformation is handled by dbt running in a separate, temporary ACI. This dbt job container is orchestrated by an Azure Function, typically triggered on a schedule. The Function retrieves necessary configurations and secrets from Key Vault, then deploys the dbt ACI. During its run, the dbt container (using its specialized dbt-duckdb plugin) processes data, writes the resulting tables to ADLS, and crucially, registers or updates the metadata for these tables in the persistent Unity Catalog server ACI. Once the dbt job completes, its ACI is terminated to optimize costs.
The deployment process is automated with shell scripts and Bicep for Infrastructure as Code.
Unity Catalog on Azure Container Instance :
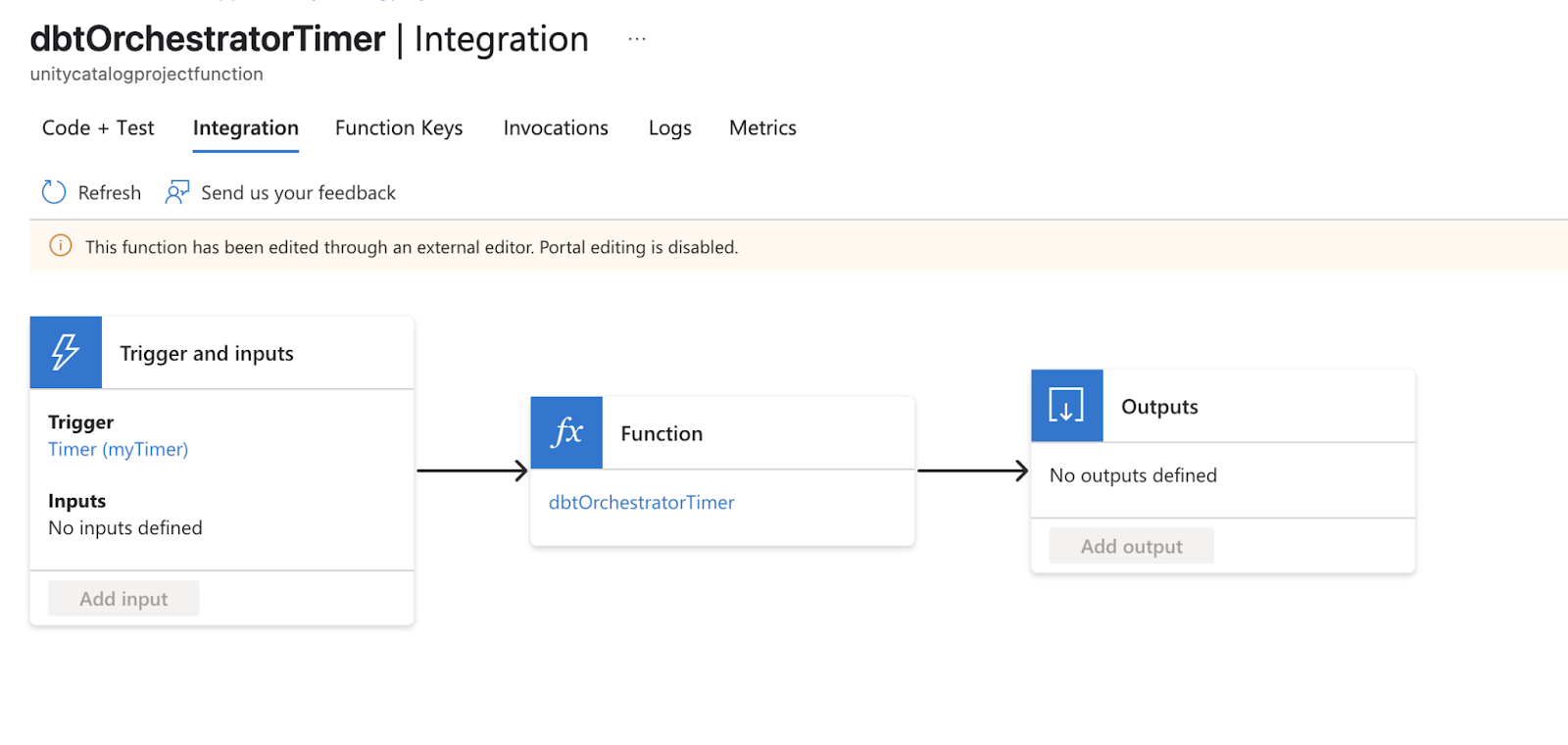
Function app that triggers dbt container to start based on a timer trigger:
Dbt container, that is created by Functions App that runs the dbt job and then terminates itself.
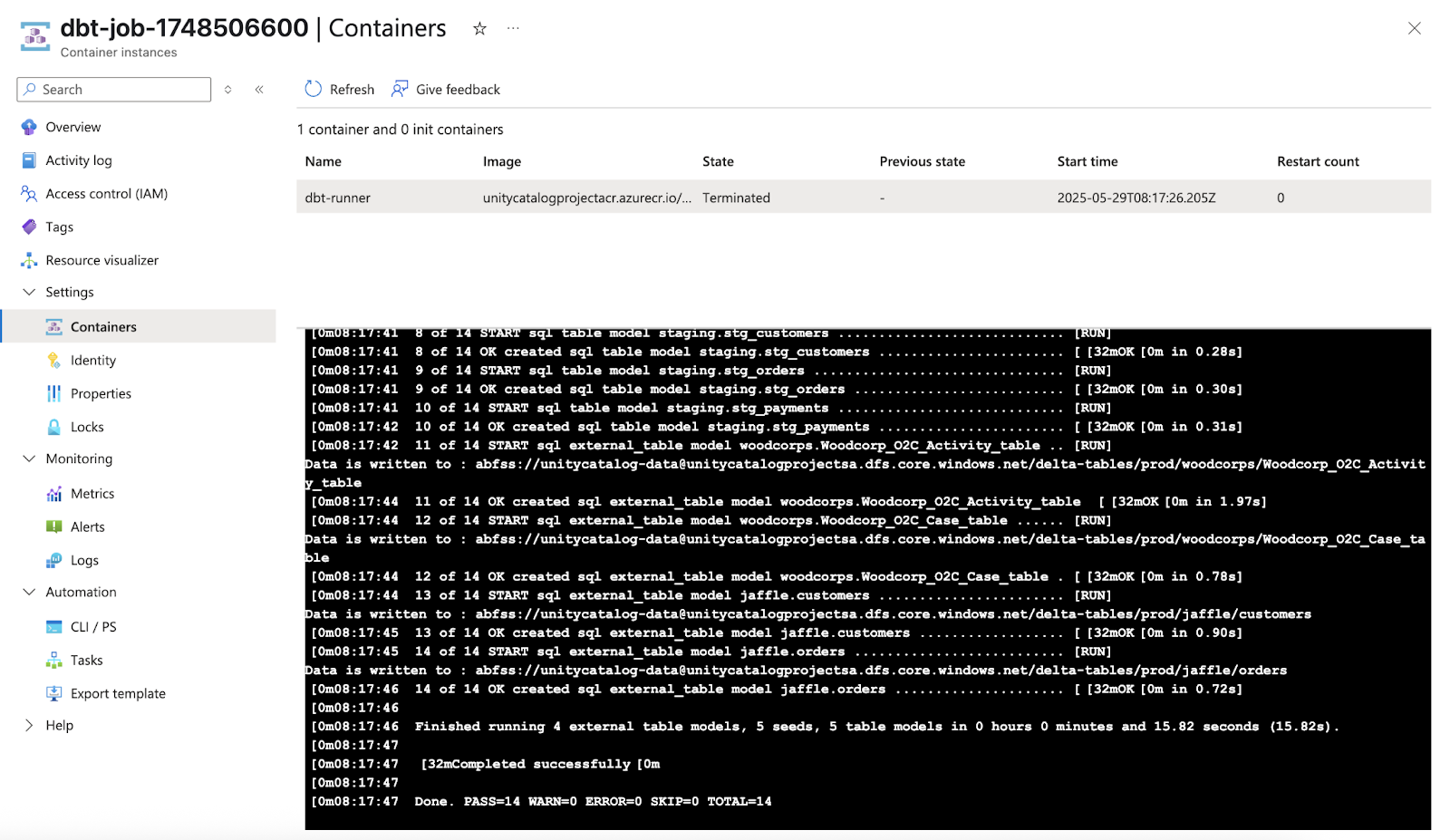
And here is the Streamlit application I have created just to make permission management easier. In the background it runs the Python SDK for Unity Catalog.

Final Thoughts and limitations
What It Offers and Where It Stands
In this section, I will be discussing features of Unity Catalog in terms of 5 main use cases :
- Initial Setup
- Data discovery
- Data governance
- Data lineage
- Data quality
Initial Setup
I wanted to include 'Initial Setup' as a category on its own because it's crucial to understand how easy it is to get Unity Catalog up and running and what official deployment options are available. Currently, OSS Unity Catalog offers a GitHub repository that you can clone and run in various environments. Additionally, an official Docker image is available for containerized deployments. As for Helm charts, while an official one is not yet provided, a community-contributed chart exists and the Unity Catalog team is working on releasing an official version.
In terms of registering assets everything has to be registered manually, one by one.This can be done individually using either the CLI or the Python SDK. This manual, one-by-one registration can make the initial cataloging process long and tedious. Metadata of the asset must match exactly to actual data. In my experience, if one were to use Unity Catalog solely for cataloging pre-existing assets without automation, this manual registration would be the most challenging part.
However, the setup described in this project, which leverages dbt, helps to solve this particular issue for tables. When dbt models are run, the resulting tables can be automatically registered into Unity Catalog through specific configurations or custom integrations within the dbt project. This allows all tables built by dbt to be seamlessly cataloged.
Data Discovery
Data discovery is a cornerstone of any data catalog, enabling users to efficiently find and understand available data assets. Unity Catalog (v0.2.0) showcases assets like tables, volumes, functions, and AI models (with versioning) in a clean, structured UI. Everything is seen in the three level namespace you might be familiar with from Databricks. This hierarchical view helps in browsing and understanding individual assets, including table schemas. However, a current limitation is the absence of a global search functionality across all assets. While keyword searching is possible within specific scopes (e.g., within a selected catalog or schema), users cannot search over the entire catalog/metastore directly from the UI.
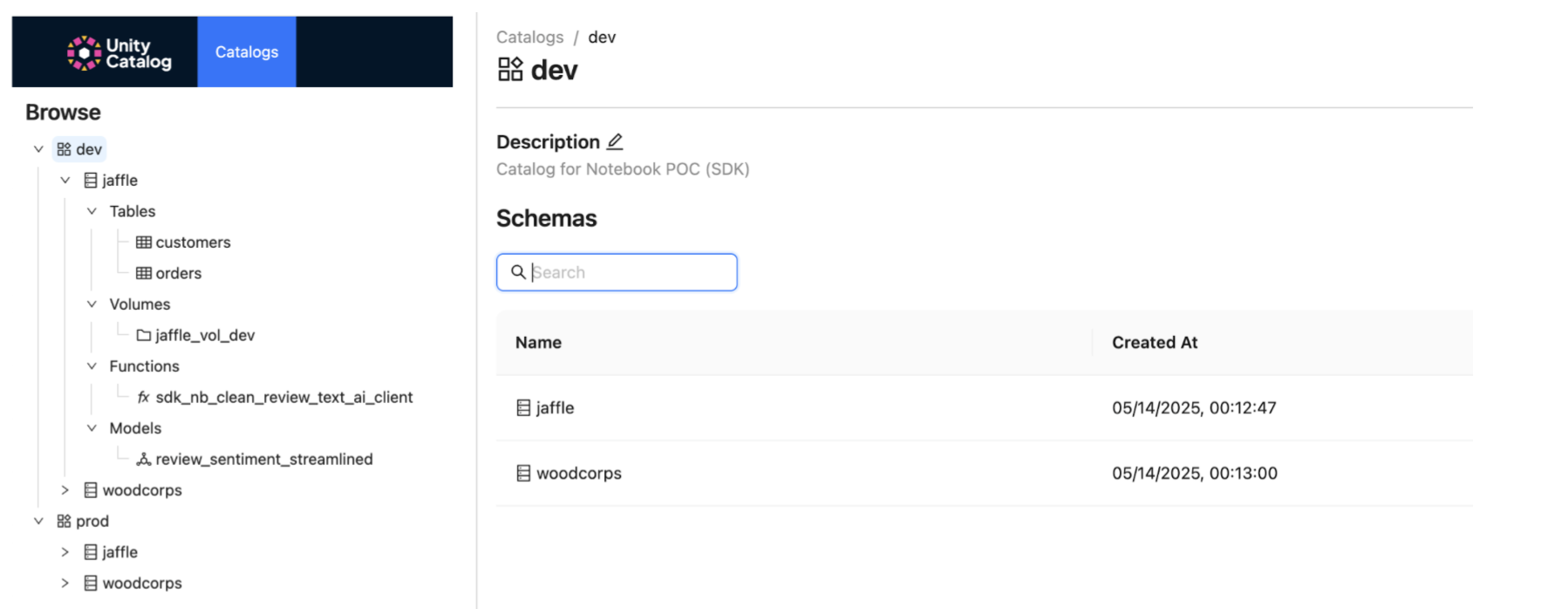
Data governance
Data Governance is another crucial reason to use data catalogs as it gives control over your assets and helps you have policies. I will be talking about 2 main parts of it: Access control and Compliance.
Access control: is one of the strengths of unity catalog. It offers authentication/authorization for all data assets including tables, functions, AI models. As you can structure your 3 level namespace as you want, you can create specific use case users as you want(in ‘Unity Catalog - Auth’ section, all permissions can be seen). This gives a lot of flexibility on how to manage accesses. It might also be possible to add column/row level security by utilizing Delta lakes’s shallow clones. One lacking feature is that currently there is no group level access management, which makes everything hard to set up. Additionally, Unity Catalog also offers credential vending which means you can store credentials of the cloud platform of your choice inside Unity Catalog and users can access the data asset through their Unity Catalog authorization without entering the credential of the cloud platform.
Compliance: Supporting compliance is a key role for a data catalog. Here's how OSS Unity Catalog currently stands:
- Data Classification: You can add comments to all assets (catalogs, schemas, tables, etc.) to describe their purpose or sensitivity. While this helps with manual classification, the OSS version doesn't offer automated sensitive data discovery or the ability to enforce access rules directly from these descriptions or tags.
- Auditing: Auditing actions do exist. It logs each action in a .txt file but logs are not structured and it is hard to interpret your way out of it.
- Data Lifecycle: UC helps you know what data you have. However, UC itself does not natively enforce data retention policies (e.g., "delete data older than 7 years")
Data lineage
Data lineage is the ability to track the origin, journey, and dependencies of your data assets. Unlike Databricks’ Unity Catalog, In its current version open source Unity Catalog does not offer automated, end-to-end lineage tracking or built-in visualization capabilities comparable to its Databricks counterpart. For instance, metadata fields like 'created by' or 'updated by' for assets are not populated by default, making it difficult to trace ownership or the history of changes directly within UC for all asset types (though users can add notes in asset descriptions). OSS Unity Catalog has limitations in data lineage. However, a key aspect of this project is that by using dbt to create all tables, the lineage issue is largely solved by the data lineage features present in dbt.
Data Quality
Data quality ensures data is clean, accurate, reliable and fit for the purpose.
- Enabling Quality Initiatives: By providing a centralized metadata repository, OSS Unity Catalog helps identify and understand data assets, which is the first step in any data quality program. Knowing the schema, data types, and descriptions (via comments) of tables cataloged in UC is crucial for defining relevant quality checks.
- Leveraging Delta Lake Features: If tables cataloged in UC are in Delta Lake format, you benefit from Delta's inherent schema enforcement and evolution capabilities, which contribute to structural data quality.
- Integration with Execution Engines (like dbt): OSS UC itself does not execute data quality rules (e.g., uniqueness, null checks, format validation). Instead, it complements tools designed for this purpose. In a setup utilizing dbt, data quality checks are typically defined and run as dbt tests. Unity Catalog then governs access to the tables that have been processed and validated by dbt.
- Current Limitations in OSS UC: Direct features for defining, managing, or visualizing data quality rules and metrics within the OSS Unity Catalog UI are limited.
So, OSS Unity Catalog provides the governance layer and the metadata. For the actual execution and monitoring of data quality rules, however, you'd rely on other parts of your data setup.
Key Pros and Cons
Pros:
- Unified Governance: Single catalog for data, volumes, functions, and ML models.
- Flexible Namespace: Familiar and adaptable 3-level structure (catalog.schema.asset).
- Granular Permissions: Object-level access control for enhanced security.
- Open & Extensible: Active, open-source nature allows for flexibility and community input.
- Integration Power: Works well with tools like dbt (for table automation/lineage) and MLflow (for model registry).
- Credential Vending: Aims to simplify secure cloud data access (implementation evolving).
Cons:
- Global Discovery: No UI-based global search across all cataloged assets.
- Group Permissions: Lacks native group-based access management.
- Automated Lineage: Limited built-in lineage; relies on tools like dbt for table lineage.
- Bugs: Can have complexities or bugs with some cloud auth methods.
- Manual Registration: Cataloging existing assets without automation can be tedious
Final Thoughts
In this blog, I tried to cover the extent of OSS Unity Catalog and the project I did that showcases strengths of OSS Unity Catalog. Overall, it offers cool features that differs from other catalogs like access management for all assets, its 3 level namespace gives familiarity but also complete flexibility in terms of how you want to build your structure. Unfortunately there are some bugs and lacking key features like group permission support, lineage, and some bugs related to credential vending. My suggestion would be: If you want to utilize these features, Unity Catalog might be something for you, if not keep an eye on its development in upcoming months as it will only get better from here with future updates. Here is the roadmap for it .
Finally, Unity Catalog is not the only data catalog out there. There is an emerging trend with the data catalogs. More and more vendors start to create their own data catalog to become the central inventory for organizations' data assets. Each offers similar features with their unique strengths and weaknesses. There is a really nice blogpost here comparing all the popular data catalogs out there.
Try it yourself!
If you're interested in replicating or extending this setup, the complete source code is available here: https://github.com/datarootsio/unity_catalog_template
The repo contains ready-to-use configurations and instructions for Docker and Azure setup, making it easy to try the open-source Unity Catalog in any environment.
🚀 Interested in implementing a setup like this? Reach out to learn how dataroots can help bring your data infrastructure to the next level.