

By Eya Akrimi, Dishani Sen
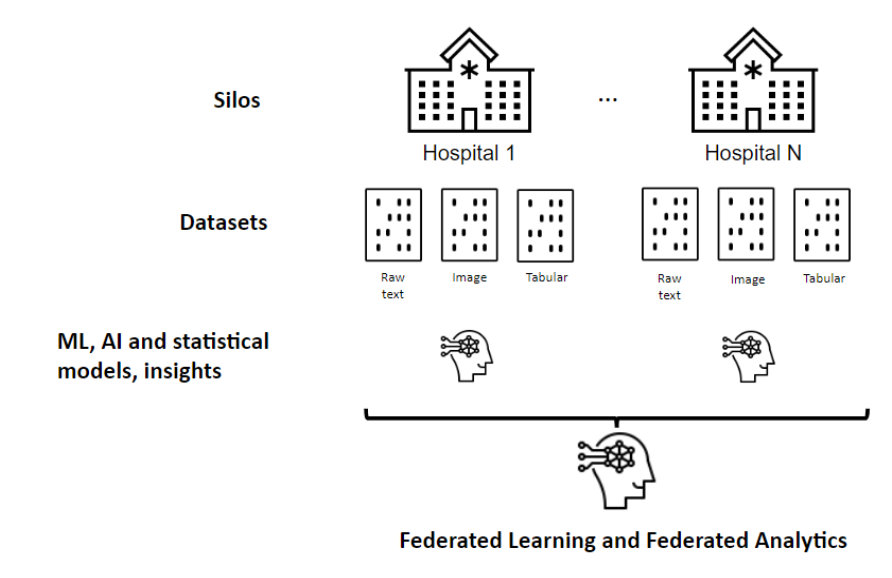
Federated learning is a revolutionary approach to machine learning that allows data scientists to train models on decentralised data sources, without ever having to access the data directly. This approach has several advantages, including improved privacy, reduced communication costs, and increased scalability. At Dataroots, we have implemented federated learning infrastructure for three hospitals and a research center using a combination of Terraform and Docker, as well as a robust CI/CD pipeline that ensures seamless deployment and updates of our federated learning infrastructure.
In this blog, we elaborate on the general challenges of building and deploying an infrastructure, the framework architecture, and then explain the steps of the process using Terraform.
Challenges
Building an infrastructure for federated learning can be challenging due to quite some reasons:
- Complexity of the infrastructure: Federated learning requires a complex infrastructure that includes multiple components, such as local data sources, a central server, and communication protocols between tenants and the central server. Managing all of these components can be difficult, and Terraform's modular architecture can help to simplify the process.
- Platform dependencies: Federated learning infrastructure can run on a variety of platforms, including cloud-based environments and on-premises infrastructure. Terraform can help to manage these platform dependencies, yet it requires expertise to configure the infrastructure appropriately.
- Data privacy considerations: Federated learning is designed to protect data privacy by keeping data local and encrypted. However, managing encryption keys and ensuring that data remains secure can be a challenge. Terraform can help to manage encryption keys and access controls, but it requires knowledge of encryption best practices and configuration options.
- Security considerations: Federated learning involves transmitting data between devices and a central server, which can be a security risk if the data is not adequately protected. Even though the data transferred is already aggregated and usually encrypted, providing an extra security layer at the communication level is still important to ensure privacy at all levels. Terraform can help to manage security concerns, yet it requires knowledge of security best practices and configuration options.
- Continuous integration and deployment: Federated learning infrastructure must be updated and deployed regularly to maintain performance and security. This requires a robust continuous integration and deployment (CI/CD) pipeline, which can be complex to set up and maintain due to the complexity of the architecture at hand.
Architecture
The global architecture is divided into four main parts, consisting of one research centre and three hospitals (tenant). The whole architecture is implemented on Azure Cloud. Each tenant will have the same privacy friendly architecture in its own Azure Cloud subscriptions. The architecture is written in terraform, which allows us to scale the project to more tenants very easily. To ensure the privacy and security of the data, a fourth subscription will act as the central node (research center), responsible for aggregating the insights (models and data analysis) and exposing the final model. This federated learning approach allows us to train the model on data from multiple nodes without ever data leaving the tenant's premises and thus exposing sensitive information.
The main components of the architecture are presented below:
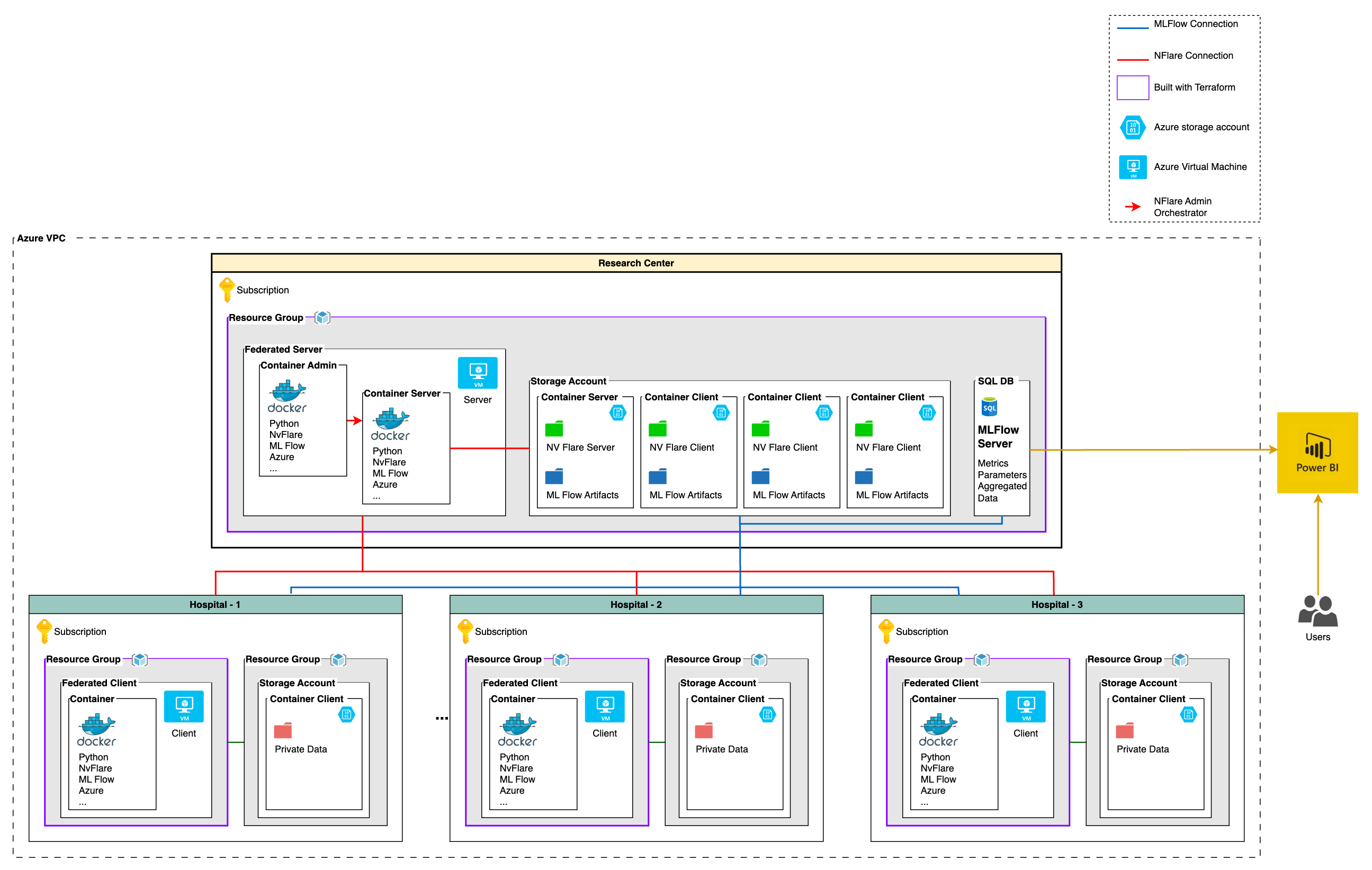
Central Node: Research Centre
The research centre consists of a single subscription on Azure. Within the subscription, there is a single resource group. The resource group consists of a virtual machine and a storage account. In the storage account, there are multiple containers, one is the container server, and the others are the containers client (one for each client). Each container client will store parameters of the models and configuration files to enable model training and tracking of the results on the tenant nodes.
Client Nodes: Hospitals
There are three hospitals, where each hospital has its own Azure subscription. An Azure subscription is a way for organisations to manage and pay for Azure services. Under each Azure subscription, there are two separate resource groups. A resource group is a container that holds related Azure resources. The first resource group for each hospital contains a virtual machine that has two containers. The first container is the docker client container, which is a lightweight, portable software platform for building, packaging, and running applications. The second container is the container server, which is a program that manages the containers and enables communication between them. This resource group is open to communicate and transmit data towards the central node.
The second resource group for each hospital consists of a storage account where private data is stored in its container. The private data stored in the storage account container may include patient information, medical records, and other sensitive data that should be protected. This resource group contains the sensitive data, only accessible via the first resource group, for security reasons.
Overall, this infrastructure setup allows hospitals to securely store and manage sensitive data, while also providing a scalable and flexible platform for their applications and services.
VNet Peering
There is a two-way VNet peering between the center and the other three tenants. A Virtual Network (VNet) is a fundamental building block of an Azure infrastructure. They are logically isolated networks that enable you to securely connect Azure resources to each other, the Internet, and on-premises networks. With Azure VNets, we created a private and secure network within the cloud environment, just like you can have on-premises.
In this case, there is a two-way VNet peering between the central hospital and the other three hospitals. This means that the central hospital can communicate with the other three hospitals over the VNet peering connection, and vice versa. However, the other three hospitals' VNets are not directly peered with each other. This means that they cannot communicate with each other over the VNet peering connection.
This architecture allows for data sharing between the central hospital and the other three hospitals, while also ensuring that the other hospitals' data remains private and secure. If the other hospitals need to communicate with each other, they would have to do so using other means, which in this case in completely restricted.
Dashboard for the End User
There are two Power BI dashboards available for different targeted users:
- One dashboard is for the data science team of the hospitals so that they can compare their data with the global data and the statistics from other hospitals.
- A dashboard for the research centre to keep track of the different model performance; to consult the results and statistics and compare each result from the three different hospitals without getting access to the real data.
Our Solution
To address the challenges mentioned above and implement the architecture, we have used three main components: Terraform, Docker, and a CI/CD pipeline (Github), enabling multiple parties to collaborate on creating complex machine learning models without sharing their data.
Terraform

Terraform is a tool that allows you to create and manage your infrastructure as code, making it easier to spin up and tear down environments as needed, and keeping all of your infrastructure configurations in a centralised location. In this section, we'll briefly mention the steps taken to use Terraform, an open-source infrastructure as code tool, to spin up virtual machines within resource groups in Azure for implementing a federated learning infrastructure :
- The first step was to set up the Azure environment. We created a resource group to hold all the necessary resources, including virtual machines, networking, and storage (for both central node and client node). This resource group served as our central location for all infrastructure configurations.
- Next, we defined our virtual machine configurations in Terraform. We specified the virtual machine size, the operating system image, and the networking configuration. We also defined the storage configuration for the virtual machine, including the disk size and type.
- Once we had our virtual machine configurations defined, we used Terraform to spin up the virtual machines in our resource group.
For the above steps, the "azurerm" provider from terraform was utilised.
Docker
Docker has also been a key part of our federated learning implementation. With Docker, we packaged up the machine learning models and all of their dependencies into a portable container, which can then be deployed to any environment that supports Docker. This has made it easier to share and deploy our models, and to ensure that they run consistently across different environments. Additionally, Docker has helped to improve the scalability of our federated learning infrastructure, as we can easily spin up new containers to handle increased load.

At our federated learning infrastructure, we have found that Docker has helped us to streamline our workflows, improve consistency, and scale more efficiently.
We have used the following steps for using Docker in our federated learning platform: containerising the machine learning models and code (NVFlare & MLFlow), building the docker images, uploading docker images to the registry, deploying docker containers both in the central node as well as the client nodes and finally, monitoring and debugging the containers.
CI/CD Pipeline
Our CI/CD pipeline has also been essential to the success of our federated learning implementation. With continuous integration and continuous deployment, we can ensure that any changes to our code and infrastructure are thoroughly tested before they are deployed to production. This has helped to reduce the risk of errors and downtime, and to improve the overall reliability of our federated learning infrastructure.

We have utilised GitHub Actions which is a powerful and flexible tool for automating software workflows, for our CI/CD pipelines. It provides a way to automate the building, testing, and deployment of your code in a consistent and repeatable way. GitHub Actions also provides integrations with popular tools and services, such as Azure and Docker, and many others, making it a perfect choice for our use case.
Reflection of the Challenges
As we were developing the infrastructure, we faced a few challenges. Some of the reflections from them are summarised below:
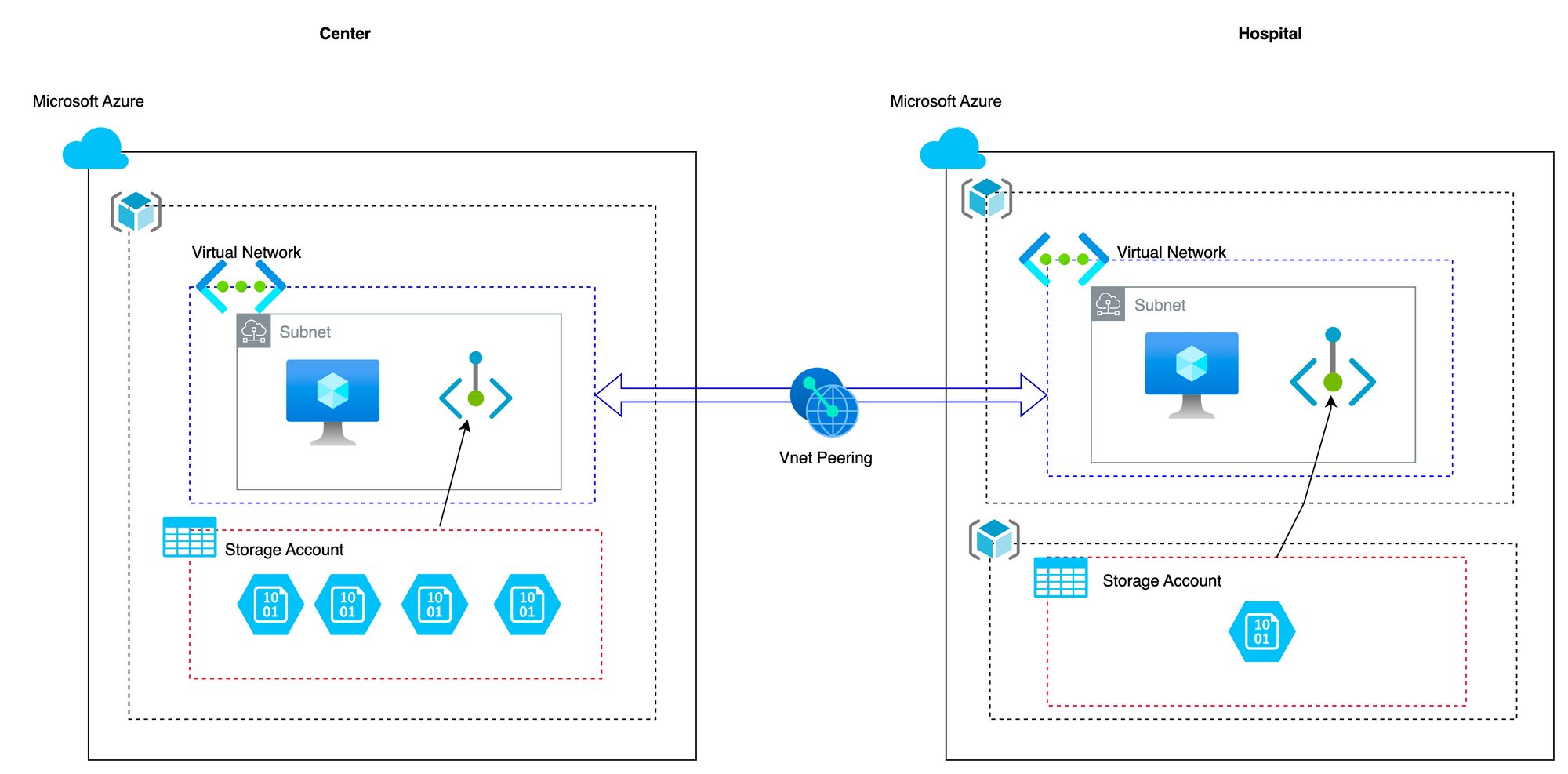
Infrastructure on Terraform: One of the challenges we faced was defining the networking configuration for our virtual machines in the three different hospitals. We had to ensure that each virtual machine had a unique IP address and that they could not be communicated with by other means. We solved this by defining one virtual network and subnet for our resource group (for the hospital) and configuring our virtual machines to use only these network settings. The main challenge was making sure that the storage account can only be accessed by the virtual machine, the solution for which was to create a private endpoint to the storage account in the same subnet as the virtual machine and making sure that no other computers (virtual machines) has access to that subnet.
Docker: Getting the NV Flare setup files to the hospital before launching the container was a hurdle, which we solved by building a script that verifies if the files are there.
CI/CD: We faced two issues with the pipeline: getting the password-less login to function and creating the VNet peering between the subscriptions because Terraform only runs one subscription at a time. To provide password-less login, we used OpenID connect. For the VNet peering, we created an additional Terraform script that runs after the resource group and virtual machines are established and successfully completes the VNet peering.
Get Started
In this section, we will guide you through the process of setting up a federated learning deployment using Trunk Based Development.
Trunk Based Development (TBD) is a software development methodology that focuses on maintaining a single branch in version control (usually named "main") and encourages frequent merges of feature branches into the main branch. We believe that this approach is well suited to federated learning deployment because it simplifies collaboration and reduces merge conflicts, which can be time-consuming and frustrating.
To get started with federated learning deployment, you can fork your own copy of the dataroots/federated-learning-project repository. This repository contains all the necessary code to set up the infrastructure on Azure for a federated learning workflow. Once you have a copy of the repository, you can create a new feature branch.Make sure to name your branch starting with "feature-". Once you have created a new feature branch, you can start making changes to the code. To maintain code quality and consistency, we provided a set of pre-commit hooks that run automatically when you commit changes locally. These hooks can be enabled by installing pre-commit and running the following command:
pip install pre-commit
pre-commit install
After the hooks have been installed, they will run against any new files you commit, ensuring that the code you push to remote meets a baseline of quality. If you want to run the hooks against your entire codebase, use the following command:
pre-commit run --all-files
When you are ready to merge your changes back into the main branch, you need to create a pull request on the Pull requests tab on Github. It is important to ensure that your code is working correctly and formatted properly before merging. We provided a CI/CD pipeline that runs automatically when you create a pull request. Your changes will only be merged into the main branch if the pipeline passes, ensuring that the codebase remains stable and reliable.
Finally, the federated learning deployment repository includes a Terraform deployment script that allows you to set up the necessary infrastructure on Azure. The repository includes three environments (dev, mvp, and prod) that are designed to facilitate the development and deployment of federated learning workflows. The dev environment is for testing and can be destroyed multiple times a day, while the mvp environment focuses on creating a minimum viable product that demonstrates basic functionality. The prod environment is for the final product.
Conclusion
In conclusion, federated learning is an exciting development in the field of machine learning, and Dataroots has implemented the cloud based infrastructure for it successfully using a combination of Terraform and Docker, as well as a robust CI/CD pipeline. With this infrastructure in place, we can continue to explore new applications for federated learning, and to push the boundaries of what is possible in the field of data science.
To get a quick introduction to our use case, the cloud-native framework for federated learning, please refer to the below blogs. We also have here an elaborate guide on the MLOps framework for the federated learning framework for you to follow.
You might also like
 dataroots
dataroots
