

By Lode Nachtergaele
The PaliGemma paper is out and creating quite a buzz in the machine-learning community. Unlike the usual fare of “here’s our model, it achieves SOTA results, kthxbye,” the authors have put in a significant effort to make it engaging and informative. Let’s dive into what makes PaliGemma stand out and why it’s an exciting development for machine learning engineers.
What is PaliGemma?
PaliGemma is a Vision Language Model (VLM) designed to handle image and text inputs, generating text outputs. It’s built with a 3 billion parameter architecture, making it a robust and powerful tool for various applications. Moreover, it’s an open base VLM, which means the model and its architecture are accessible for further research and development by the community.
Key Features:
- 3 Billion Parameters: Provides a strong foundation for handling complex vision and language tasks.
- Open Base VLM: Encourages community involvement and collaborative improvements.
- Multimodal Inputs: Accepts image and text as inputs to produce textual outputs.
PaliGemma-3B encodes the image by splitting it into a series of patches fed to a vision transformer (SigLIP-So400m). SigLIP is a state-of-the-art model that can understand both pictures and text. Like Contrastive Language–Image Pre-training (CLIP), it consists of an image and text encoder trained jointly. These patch embeddings are linearly projected and inputted as “soft” tokens to a language model (Gemma 2B), to obtain high-quality contextualized patch embeddings in the language model space, which are then projected to a lower dimension (D=128) for more efficient storage.
Two recent works show that VLMs are significantly worse classifiers, especially long-tail, than CLIP:
- Why are Visually-Grounded Language Models Bad at Image Classification?
- African or European Swallow? Benchmarking Large Vision-Language Models for Fine-Grained Object Classification
They also say why, tl;dr: need to see a lot more such data (@LucasBeyer)
What are Vision Language Models (VLMs)?
Vision Language Models, like PaliGemma, are designed to understand and generate language in the context of visual inputs. They can process images and accompanying textual descriptions to produce meaningful text. This capability opens up numerous possibilities, from image captioning and visual question answering to more sophisticated tasks like generating descriptive narratives based on visual content.
For a more detailed explanation of VLMs, you can check out these resources:
- Short Intro to VLMs
- In-Depth Explanation of Vision Language Models
- An Introduction to Vision-Language Modeling
Exploring PaliGemma
If you're eager to see PaliGemma in action, you can explore it through this Hugging Face demo: Big Vision's PaliGemma Demo. It provides an interactive way to experience the capabilities of PaliGemma and understand how it handles multimodal inputs to generate coherent and contextually relevant text outputs.
For example, uploading the profile image of @jonastundo together with the prompt "segment person" gives:
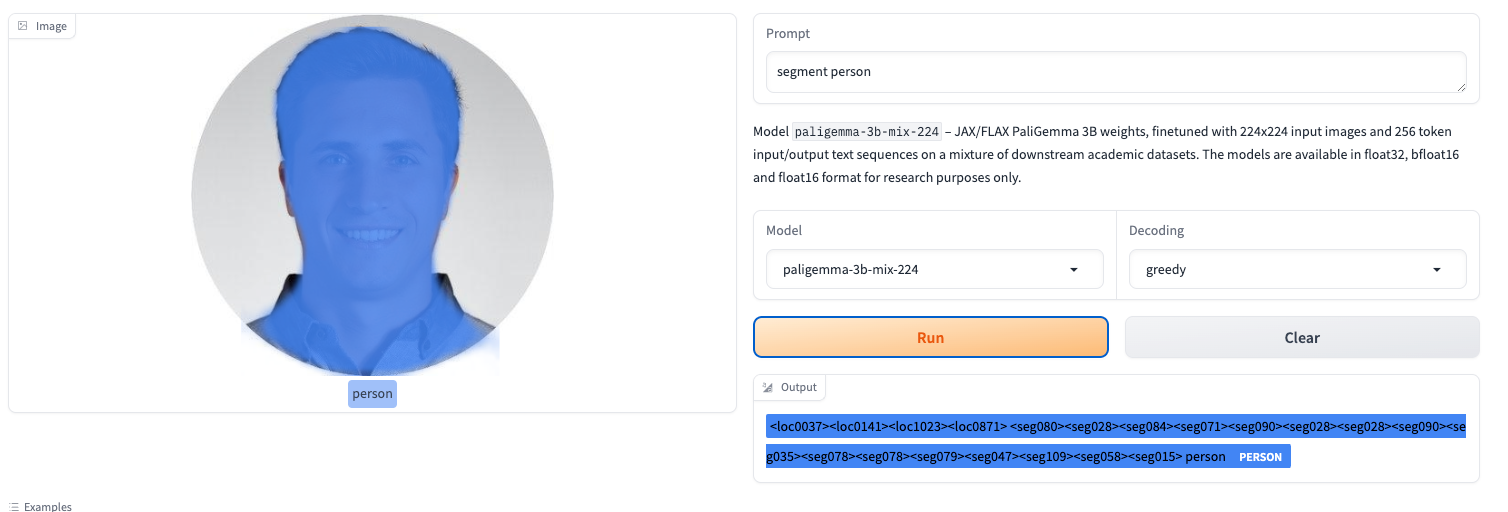
Fine-Tuning PaliGemma
As opposed to most other VLMs, PaliGemma must be finetuned a bit for your use case to make sure the model understands what you want – but that's so cheap it becomes a vertical bar in Figure 3 of the paper (source: Andreas Steiner):
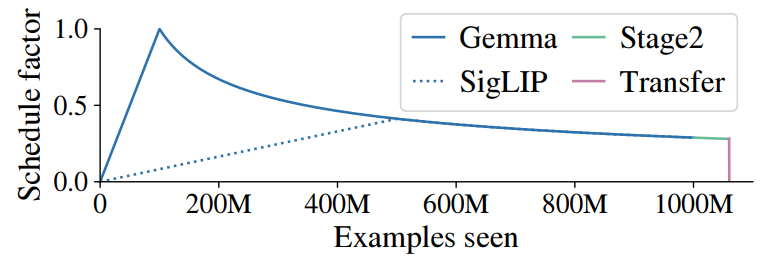
The Transfer stage in Figure 3 shows a minimal schedule factor throughout the process, effectively a vertical bar at the end. This suggests that the Transfer stage during the training of Paligemma requires almost no fine-tuning. Hence, your fine-tuning task is expected to be rather inexpensive in resources.
For those interested in customizing PaliGemma for object detection or other vision-related tasks:
- a detailed notebook for object detection finetuning made by @SkalskiP is available here: How to Fine-Tune PaliGemma on a Detection Dataset
- a notebook within Google's Bigvision project that runs on a free T4 GPU: finetune_paligemma.ipynb
- Finetuning Paligemma with Hugging Face transformers
Staying Ahead with Vision Models
Keeping up with the latest advancements in vision models is crucial for any machine learning engineer. Here are some hot models currently making waves in the field:

To be added to the above table is the Massively Multilingual Masked Modeling (4m) model released by Apple and EPFL. The code is Apache-2.0, but the model weights are under a separate, non-commercial license. Hence, I am most excited by Microsoft's Florence-2 because the model is small (230M - 770M) and has an MIT license!
Learning Prompt Engineering for Vision Models
For those looking to deepen their understanding of vision models and learn how to prompt and fine-tune them effectively, there’s an interesting course titled "Prompt Engineering for Vision Models." This course from @DeepLearningAI covers image generation, image editing, object detection, and segmentation. The best part? It’s free to join. More details can be found here:
Potential impact on the PDF extraction industry
PaliGemma can be finetuned to understand documents with figures and tables potentially disrupting the retrieval of documents for Retrieval Augmented Generation (RAG) applications. Instead of extracting text from PDF and performing Optical Character Recognition (OCR) on the tables and figures, Pali-Gemma can be finetuned to calculate semantically meaningful embedding vectors for documents. Those embeddings are then calculated for every page in a document that is sliced into images matching the input resolution of the Paligemma model and fuel the retrieval. The Colipali model takes this approach. Read more about it in ColPali: Efficient Document Retrieval with Vision Language Models
As PaliGemma has a lot of potential for the retrieval part of RAG applications, the text from the PDF documents is still needed to formulate relevant answers for the users. For that, OCR might still be required.
Conclusion
PaliGemma represents a significant step forward in integrating vision and language models. Its open-base architecture and robust capabilities make it a valuable tool for machine learning engineers looking to explore the intersection of visual and textual data. Whether you're interested in fine-tuning it for specific tasks or simply exploring its capabilities, PaliGemma is a model worth your attention. Happy experimenting!
Got any questions? Contact lode@dataroots.io