

By Adrien Debray, Johannes Lootens
You want to get started with Kaggle competitions? You saw an interesting challenge or the big prize money but feel a bit lost about how to tackle the competition ?
This blog provides a broad overview of Kaggle competitions, guides you through the winning methodologies, and offers tips and tricks to help you tackle a Kaggle competition more effectively.
All you need to know about Kaggle competitions
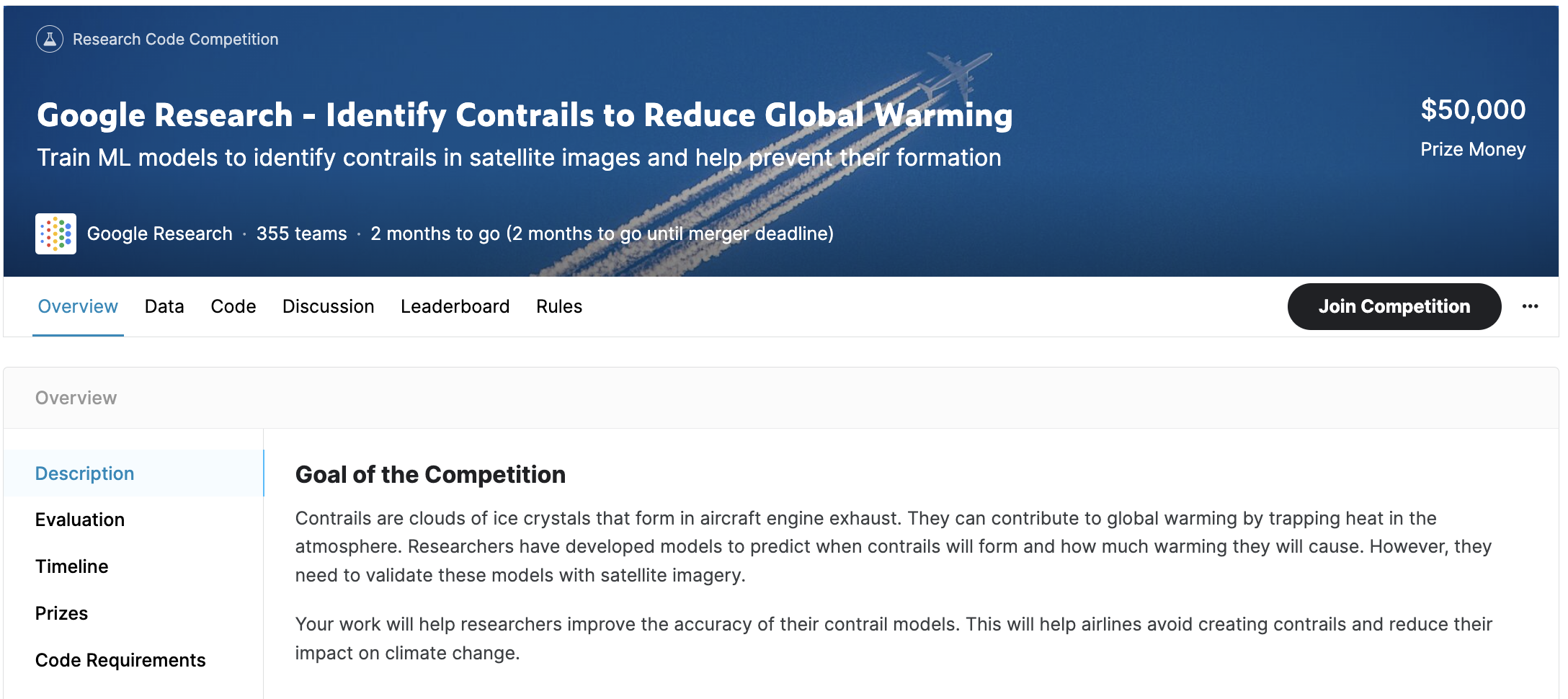
💡 Kaggle is a platform where data enthusiasts come together to explore and analyse datasets and participate in machine learning competitions. The platform is a fun and collaborative space that encourages learning, problem-solving, and innovation.
While Kaggle has grown substantially over the last few years to a more all-round data science hub, the competitions were and remain Kaggle’s raison d’être and come in all shapes and forms but can be divided into three main (albeit slightly arbitrary) categories: getting-started , community competitions, and cash prize competitions.
Firstly there are the getting-started competitions, such as the Titanic or Digit Recognizer ones. These are meant more as a sandbox with a well-defined goal to allow newcomers to become familiar with ML concepts, libraries and the Kaggle ecosystem in a fun way. Together with the community competitions, where someone just had an idea for an interesting competition, these generally list “kudos”, “swag” or “knowledge” as their prizes with the reasoning that the journey and knowledge gained on the way are more important than the destination.
What actually tends to attract people to Kaggle are the competitions with cash prizes. These attach prize money to top leaderboard spots and are usually set up by companies or research institutes that actually want a problem solved and would like the broader audience to take a shot at this. With prizes ranging from a few 100’s to multiple 100 000’s of dollars, these attract some of the best in their respective fields, which makes competing challenging but very rewarding.
Every single one of those competitions is defined by a dataset and an evaluation score. Here the labels from the dataset define the problem to be solved and the evaluation score is the single objective measure that indicates how well a solution solves this problem (and that will be used to rank the solutions for the leaderboard).
While the train set is publicly available, the data used to evaluate solutions is not and is usually divided into two parts. First there is the public leaderboard test set which is used to calculate leaderboard scores while the competition is still going on. This can be used by teams to check how well their solution performs on unseen data and verify their validation strategy. Secondly there is the private leaderboard test set. This is used to calculate the private leaderboard scores, which decides ones actual final place, and these are only disclosed after the competition ended.
This not only prevents fine-tuning on the test data but also keeps things exiting since leaderboards can completely change last minute if people did (either intentionally or not) do this anyway. The resulting shuffle usually makes for some interesting drama where long-reigning champions fall from grace and unnoticed underdogs, who kept best practices in mind, suddenly rise to the top.
Notebooks
To compete one can either work on private resources (such as a local machine or cloud-hosted vm or compute instance) or use a Kaggle notebook.
Private resources do have some advantages since one has full freedom about the environment, packages, etc. Especially if you want to use packages such as MLFlow or Tensorboard, which do not work in the Kaggle notebooks. Next to this, not having a limit to running times, memory and disk space can be quite convenient.
The Kaggle notebooks are Jupyter notebooks running on a maintained and standardised environment, hosted by Kaggle and they come with unlimited, free CPU time (with session limits of 12h) and 30h of GPU time (per user) each week for most of your parallel computing needs. This ensures that everybody who wants to compete can compete and is not limited by their hardware, which makes the competitions as democratic as possible. Additionally, you can easily import Kaggle datasets in a few seconds, which is especially convenient for the larger ones which can easily exceed 100s of GBs. Finally they are also the way to submit a solution to the competition. The submission notebook will have to read in a (private )test set and generate predictions on this set that will be used to calculate the leaderboard score. So even if you work on your own resources for training and fine-tuning, you will have to convert your code to a Kaggle notebook eventually.
How to take the W in a Kaggle competition ?
It is a matter of approach taken and how many of your ideas you could try out to finish high on the leaderboard !
We participated in the Vesuvius Challenge - Ink Detection competition. While we did not win any prizes, some of the top Kaggle competitors shared their solutions after the competition ended. The methodology used by the winners seems to be more or less the same across the board. Interested to know them ? Let’s break them down in few simple steps !
1. Have a good understanding of the competition and how to tackle the problem
As the people who are organising these competitions often already spend a lot of time finding a good solution themselves, a ton of material might be already available. We would recommend you to:
- Read the competition overview and linked resources thoroughly
- Get familiar with the data. Look at samples, plot statistics, all the usual EDA
- Check existing literature on approaches that were tried/succeeded in solving this or similar problems
2. Get inspired by other participants’ work to get started
To earn Kaggle medals or because they are genuinely nice, some competitors share their knowledge through making notebooks and datasets public or sharing findings and insights in discussions to get “upvotes”. We recommend reading the ones that got a lot of upvotes. This step is really a must as there are so much things to try out to improve your result it is impossible to cover everything with your team.
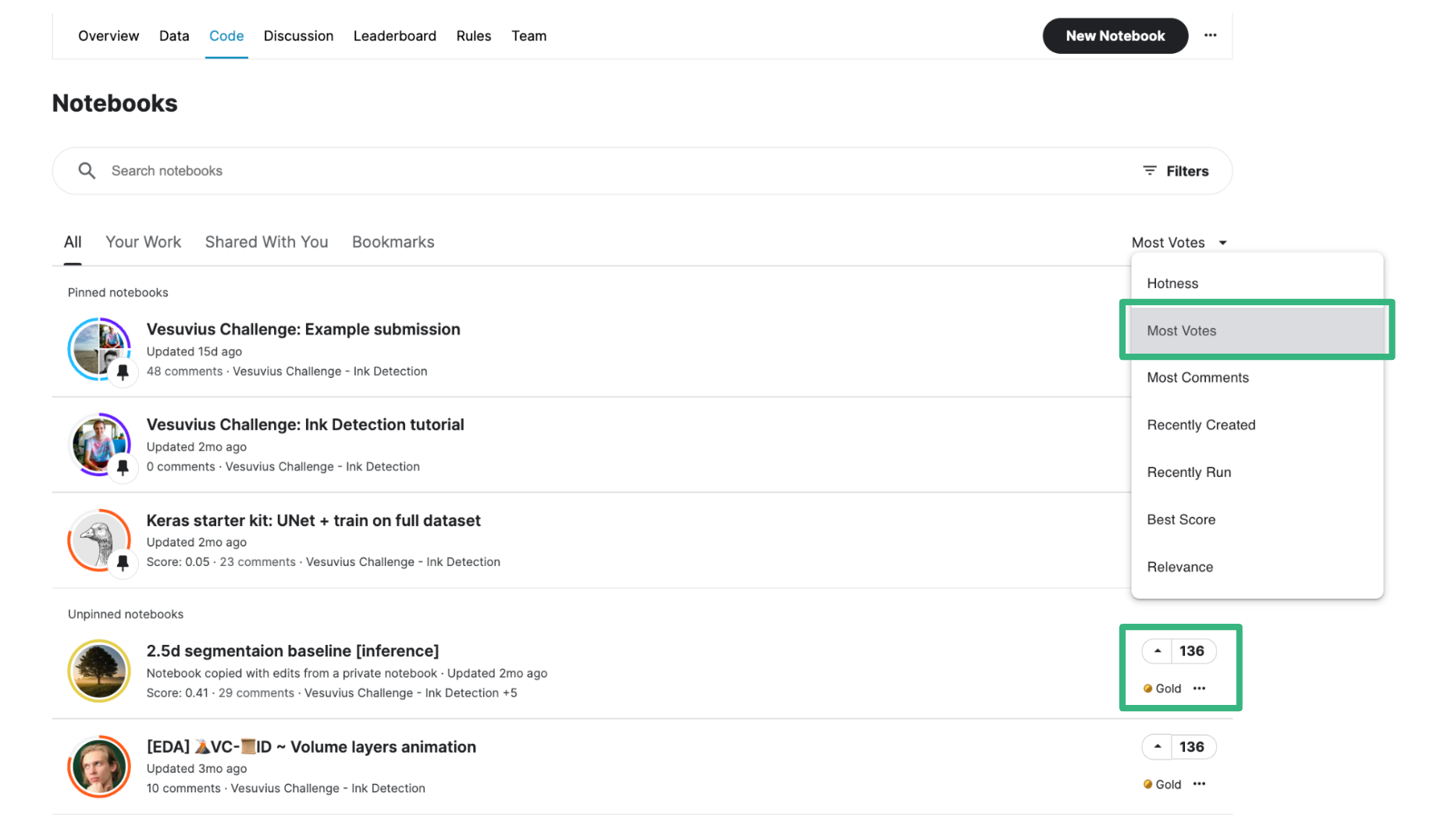
Based on your readings, choose a clear and simple notebook with a decent LB score as baseline. Try to come up with a strategy on how to improve this baseline based on your thoughts and what you read from the shared work.
3. Improve your model in an efficient way
In this phase, you will experiment a lot in the hopes of improving your LB. The goal here is to maximise the number of experiments you will try in a limited amount of time !
Create datasets for intermediate results / preprocessed data
Saved preprocessed datasets and trained models will make your results comparison more “fair” and will save you precious GPU time by avoiding repetitive tasks.
Accordingly, your work structure should avoid having big complicated notebooks but rather simple training and inference notebooks taking the processed data as input.

Efficient GPU Usage
Kaggle provides 30 hours / week of free access to several accelerators. These are useful for training neural networks but don’t benefit most other workflows. If you don’t have access to other private computing units:
- Use a CPU unit when possible, for example for data loading and preparation.
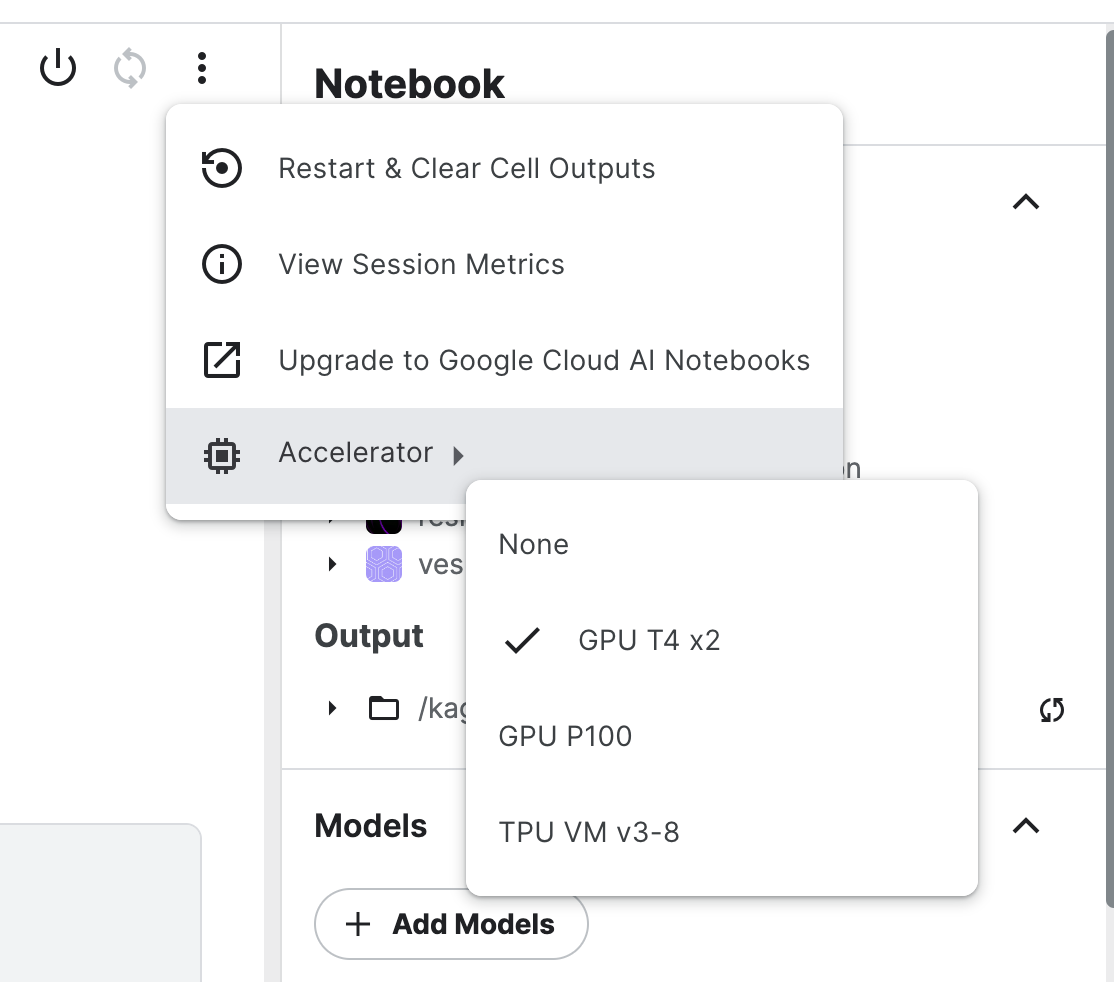
- Don’t use “Save & Run All” to checkpoint your progress, this will waste GPU quota by running all your cells again. If you use “Quick Save”, this will create a new version of your notebook that you can revisit anytime in the same state.
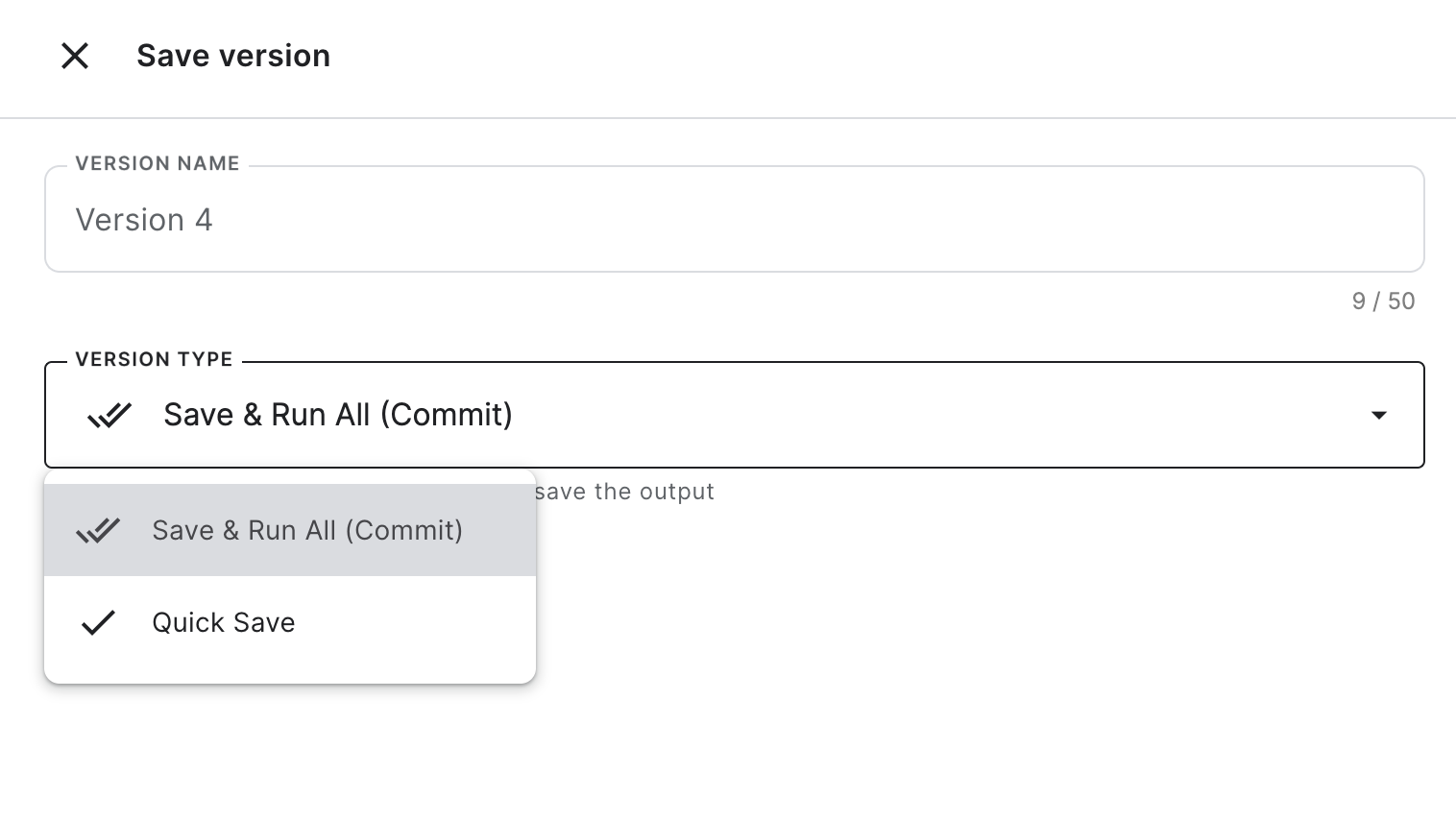
Notebook persistence to handle disconnections
Notebooks can crash/get disconnected for a variety of reasons, which can lead to losing progress/data/trained model weights/… and, depending on how important and reproducible these were, some hair as well.
The persistence option for notebooks allows you to persist files and/or variables between sessions but will lead to a longer startup time. Enabling this can save you a lot of frustration, especially if you like to make the most out of the memory provided to you by Kaggle. Additionally this can allow you to more easily compare multiple training runs without having to download the results every time you start a new session.
4. Pay attention to little tricks to raise your LB score
Competition hosts propose cash prizes because they are looking to get help for an unique challenge with unique data. While out-of-the-box solutions often perform decently on these use-cases, they will not earn you a top spot (the big cash prizes are there for a reason) and being able to adapt them as needed to solve the particular problems associated with the challenge is where stuff gets actually interesting.
As an example, here are some tricks applied by the top scorer of the Vesuvius Ink detection challenge (an instance segmentation problem where every pixel of a papyrus scroll had to be classified as ink or plain papyrus) we participated in.
- The winner and runner-up of the competition both predicted instance segmentation at a lower resolution and upscaled it later to every pixel. Being able to include more context usually outweighs the decrease in resolution.
- Denoising predictions, taking connectivity principle into account. Small group of pixels labelled as ink are more probable to be noise than representing inked written letters.
These tricks raise the LB score considerably compared to spending more time improving the model itself. For example, we observed that the top competitors of the Ink Detection Challenge we participated in used very different ensembles of CNN, segformer and transformer models to make predictions, all leading to similar LB scores.
Conclusion
We hope the overview we gave about Kaggle competitions, some general guidelines to quickly get started and flatten the learning curve whetted your appetite to join a competition. Even if you don’t make it to the top of leaderboard, you gain a lot of valuable experience (and it’s often just plain fun as well if).
Finally, we will conclude that in the ML field, the default strategy to solve most problems is with bigger models, larger datasets, more GPU’s and longer training times (couch LLMs cough). However, most of the time this is not an option and then the value of being familiar with your data and knowing what one is doing becomes clear. Especially in Kaggle competitions where training data is frequently limited and test sets usually secret, the value of properly cleaning and preprocessing the data, thoughtful training and generally knowing what one is doing is quite valuable and often reflected in the leaderboard rankings.