

By Ben Mellaerts
for companies with different operating models
If you prefer the video version (with slides); it is available here.
Organizations have a business strategy in place to define how they can achieve and maintain a sustainable competitive advantage. However, most organizations don’t yet have a strategy in place on how to extract the right value from data.
According to a survey conducted by Harvard Business Review, 71% of organizations say artificial intelligence (AI) models will be extremely important in the medium term. Nonetheless, 61% say they do not yet have a data strategy in place.
This article aims to highlight the importance of having a data strategy and covers the following topics:
- A definition of 'data strategy'
- The importance of thinking business-first when developing a data strategy
- The impact of a company's operating model (centralized vs decentralized) on the way a data strategy is developed
- A five step approach to developing a data strategy
A definition of 'data strategy'
Since the number of articles about data strategy is rising and interpretations of the term vary, it is important to start with a clear definition: a data strategy is an action plan to advance the data & AI maturity of an organization in the direction of a north star ambition.

Like business strategies, data strategies will be developed every few years. The goal of the data strategy is to advance the data & AI maturity of the company by building capabilities, data assets, dashboards and so on. How such an action plan is made, can be found in the five step approach later in this blogpost.
Thinking business-first is essential
Today, many investments made in the data/AI domain are not returning the expected business value. One reason for this is that companies are building new infrastructure, machine learning models and other data/AI capabilities for the sake of it (or because it is a trend), instead of focusing on business goals. This results in a costly data domain which does not contribute efficiently to the competitive advantage of the organization.
The solution lies in creating a business-driven data strategy. By thinking business-first and starting from the business goals, the data strategy will be set up in a way that all data & analytics initiatives are steering business towards reaching its goals and thus focusing on business value.
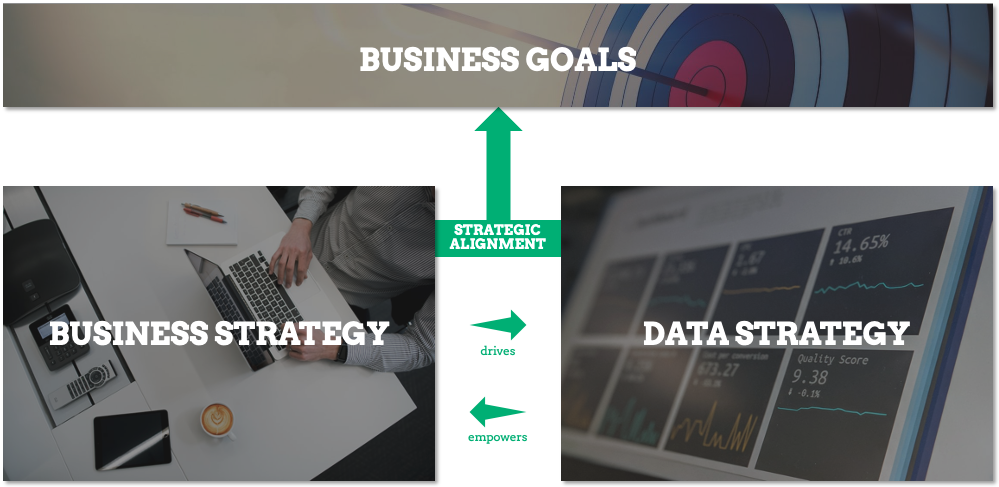
A company's operating model impacts the way a data strategy is developed
The development of a data strategy is impacted by the operating model of the company, which is often described as a set of discrete options between fully centralized and fully decentralized:
- In a centralized model, there is a single enterprise-wide data and AI function that controls everything; resources, funding, asset allocation, talent and strategy. In this model, the lines of business (e.g. finance, marketing, legal, security,…) engage with this central function for their data and AI needs.
- In a decentralized model, the data & AI activities are conducted within the business units, very close to the actual business users. This means that each business unit is responsible for hiring talent and ensuring that governance standards etc. are maintained. The business units are responsible for tool selection, use-case definition, delivery, and so on.
The majority of organizations are neither fully centralized nor fully decentralized, but are rather situated in a grey zone in between, owning elements of both. However, to clearly show differences, these 'extreme' operating models are considered in the following five steps of developing a data strategy.
A five step approach to developing a data strategy
This part consists of five building blocks of developing a data strategy. Additionally, there are two other highly important elements: data governance and data architecture. These should be managed in parallel throughout the whole process of developing a data strategy but are out of scope for this article.
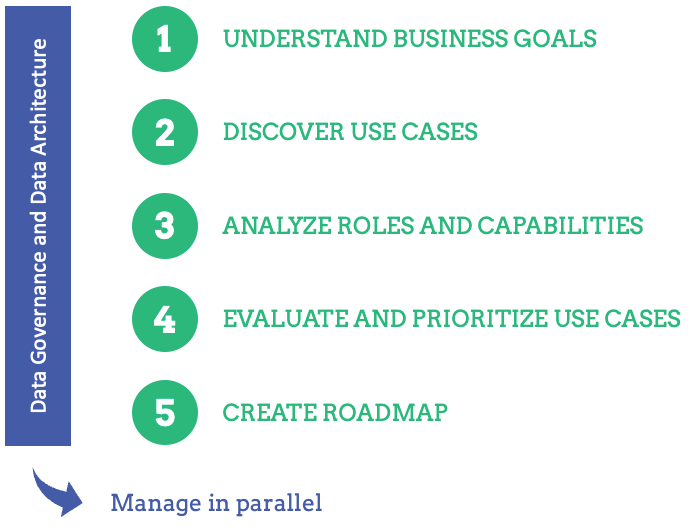
Step 1. Understand the business goals
The first step is to understand the business goals. What are the company's objectives and key results? What does the business strategy look like? What are the key performance indicators? What are the company's mission and vision?
One objective could be for example to get higher customer satisfaction. The related key result could be to increase the Net Promotor Score with 20 points by the end of the year. The question we then need to ask is how data & analytics can contribute to this goal.
Already at the starting point, we can see a clear difference between centralized and decentralized operating models.
- Centralized: objectives are defined in a central decision-making unit and are then translated into domain goals (top-down). There is clear alignment but less affinity with the domains.
- Decentralized: objectives are defined by domain leaders who have high business affinity. Afterwards, alignment between the domains is necessary to get to the corporate objectives (bottom-up).
Step 2. Discover data & analytics use cases
Bearing in mind the business goals, all stakeholders need to be mapped. Together with them, various workshops and brainstorm sessions need to be organized to think about how data & analytics initiatives can contribute to the success of the business goals. The outcome is a backlog of potential use cases.
Examples of use cases are automated trade operations, pricing optimizations, fraud detection,... or for the customer satisfaction example mentioned before: call center automation.
The way data & analytics use cases are discovered, is again dependent on the operating model.
- Centralized: stakeholders of different domains participate in workshops with the central data team to discuss potential use cases. There is one company-wide backlog of initiatives.
- Decentralized: each domain will have separate workshops with its own dedicated data team and business leadership. Every domain will make a backlog of use cases.
Step 3. Analyze roles and capabilities
Once there is a backlog of potential use cases, it is necessary to perform a gap analysis between the available and required roles & capabilities for the use cases. This way, the feasibility of all use cases can be estimated and there is an overview of existing and non-existing roles & capabilities.
- People (roles): do the use cases require new skills, which are not yet available in the team? Are the business teams willing and able to adopt the solution?
- Technology (capabilities): can our current data landscape support the use cases? Do we have the required tools? Can we integrate the outcome into the consumption layer?
The deliverable of this step is a detailed gap analysis for all listed use cases.
Again, the execution of this step varies depending on the company's operating model.
- Centralized: data is governed company-wide, the technology stack is used by all domains and the capabilities are managed by a central data team.
- Decentralized: data is governed within domains, technology stacks can be scattered (e.g. Marketing uses a commercial tool but Finance relies on an open source solution) and capabilities are owned by the domains.
Step 4. Evaluate and prioritize use cases
The business goals and gap analysis of available and required capabilities will serve as inputs for the use case evaluation and prioritization exercise. Next to that, a business case with financials has to be made for the listed use cases. This includes identifying value buckets and estimating costs.
Given these three inputs (business goals, gap analyses and business cases), the use cases can be mapped on a graph with two axes: business value (€) and technical feasibility. Both range from low to high.
- (€) Business value axis: this score is based on a combination of the strategic importance of the use case and the outcome of the business case. It is important to focus on both, since sometimes something costly can still contribute to a business goal (e.g. improve brand image).
- Feasibility axis: this score is based on the gap analysis about roles and capabilities. A use case which requires two data scientists and builds upon existing data capabilities will be more feasible than a use case which requires five data scientists and a new capability to be built.
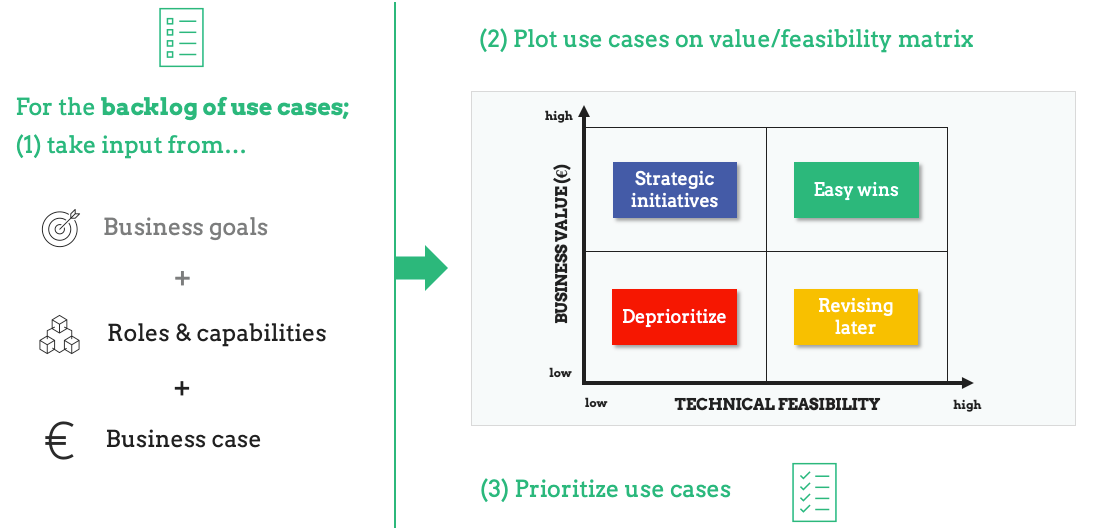
Here is an overview of the four quadrants:
- Easy wins: use cases with a high business value potential and feasibility of execution. These initiatives should be prioritized.
- Strategic initiatives: use cases with a high business value potential, but low feasibility. When multiple strategic initiatives share the same capability that needs to be built, it can still be smart to build that capability, since it is then possible to add more use cases with a high business value potential. In that case, some initiatives can still be prioritized. Otherwise, they have to be deprioritized.
- Revising later: use cases with high feasibility, but low business value potential. These can become easy wins when the strategic importance rises, for example when the market context changes or competitors are investing heavily in new technology. Otherwise, they should be (temporarily) deprioritized.
- Deprioritize: use cases with a low business value potential and feasibility of execution. These initiatives should be deprioritized.
The operational model of the company again impacts this exercise.
- Centralized: structured approach, with clear and formal guidelines. Some domains will be more satisfied with the outcome than others. Budgets for data are easily managed since they are allocated to the central data team.
- Decentralized: budgets are less transparent because they have to be allocated to the related domains. Satisfaction of different domains can be higher since they manage their own priorities.
Step 5. Create a roadmap
The result of step 4 is a prioritized, final list of the data & analytics use cases which will be part of the data strategy. To ensure proper project management and implementation, these initiatives need to be plotted on a timeline (Gantt chart). This timeline includes the start and end dates, ownership and dependencies of all initiatives.
An additional exercise during this step is to identify 'enablers'. When multiple initiatives share the same required new capability, it can be beneficial to put this task at the start of the execution of the data strategy. This way, duplicate work is avoided and future initiatives can be executed more efficiently.
The following visual is a simplified example of a data strategy roadmap.
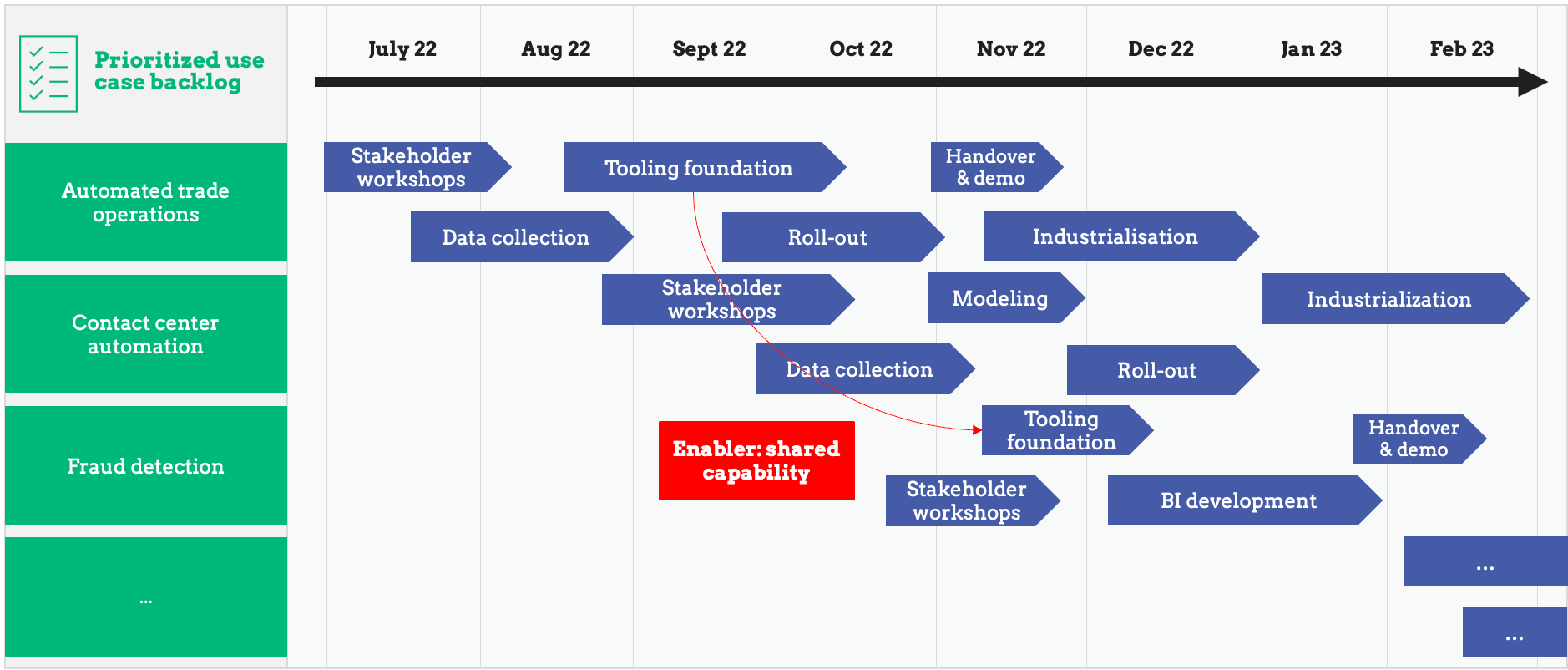
How the data strategy timeline is built, depends on the operating model of the organization.
- Centralized: joint exercise with all domain leaders, who have less control over their own roadmaps. There is one clear company-wide roadmap.
- Decentralized: each domain is accountable for its own roadmap, which results in domain ownership with more business affinity but also company-wide interdependencies.
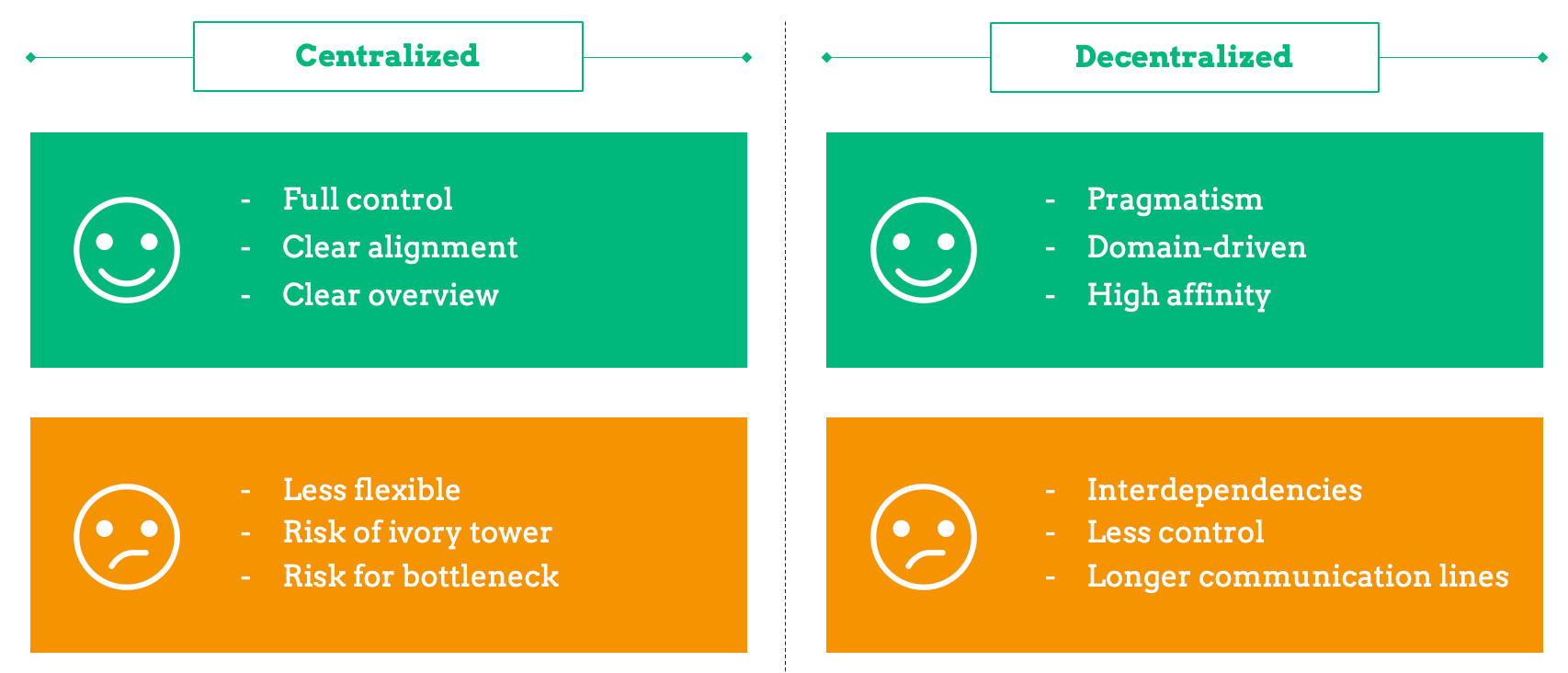
Finally, here is an overview of some advantages (green) and challenges (orange) of fully centralized and fully decentralized operational models:
Hopefully this article serves as a view on data strategy development.
Ben