

By Sam Debruyn
At Dataroots we've been intrigued by the new path the data community is taking with DuckDB. You can listen to our podcast or read our previous blog post about this topic.
To refresh your memory a bit: DuckDB is an in-process OLAP. It's similar to what SQLite is doing for OLTP workloads. DuckDB is an open-source project steered by the DuckDB Foundation, a Dutch non-profit organization. You can transform data with the tools you already love, in the languages you already know. DuckDB's SQL syntax is mostly ANSI-compliant and very flexible. You can read and write data from/to local storage or cloud storage in any common format (CSV, parquet and more). As DuckDB is lazily evaluating your code and is written in C++, its performance is similar to modern data tooling like Polars, Arrow and Pandas 2.0. In our podcast, DuckDB Labs CEO Hannes Mühleisen told us that they achieved the same performance as a Snowflake Large cluster on a single M2 MacBook Pro with DuckDB. Insane, right?
Why would you use DuckDB?
DuckDB somehow resembles the common lakehouse approach you see appearing everywhere and can serve as the compute engine in your data platforms where cloud storage is used for storage as usual. It can interface with popular tools like dbt and Pandas.
You could wrap the execution of your DuckDB transformations with orchestration tools like Airflow, Prefect or Dagster or you could just spin up a few AWS Lambdas / Azure Functions to run your transformations on the cheap without compromises.
Do we really know how to work with the cloud?
Throughout the years of cloud adoption, we learned that you should always scale out and avoid scaling up. Tens of smaller-sized computers are better than a single large computer. But how true is that? Let's take a look at pricing for Azure Dv5 (Paris) and AWS m5 (Paris) instances.
| Instance type | vCPU (cores) | Memory (GB) | Price per hour ($) |
|---|---|---|---|
| m5.large | 2 | 8 | 0.112 |
| D2v5 | 2 | 8 | 0.112 |
| m5.xlarge | 4 | 16 | 0.224 |
| D4v5 | 4 | 16 | 0.224 |
| m5.2xlarge | 8 | 32 | 0.448 |
| D8v5 | 8 | 32 | 0.448 |
| m5.4xlarge | 16 | 64 | 0.896 |
| D16v5 | 16 | 64 | 0.896 |
| m5.8xlarge | 32 | 128 | 1.792 |
| D32v5 | 32 | 128 | 1.792 |
As you can see, as long as you end up with the same amount of cores and memory, you will end up paying exactly the same, regardless of the number of different nodes you use. Even contrary to our general rule of scaling out, in terms of performance there is some overhead which is lost by having to transfer data between the nodes inside the cluster. A funny side note is that you can see exactly how Microsoft and Amazon match their prices.
So what is there to gain by splitting your workload over multiple nodes? The answer here is parallelization. If you have a workload that can be parallelized, you can scale out and run it on multiple nodes. This way the work gets done faster, which is probably what you're aiming for.
So purely theoretical - not looking at the duration of your data workloads - scaling up is going to be more cost-efficient than scaling out. Of course, there are other factors to take into account. Scaling and taking nodes in or out of the cluster is much more flexible than scaling up and down a single node.
Jordan Tigani, CEO of MotherDuck, wrote a lengthy blog post about scaling up vs. scaling out.
Why would you use DuckDB (revisited)?
How could a single node with DuckDB be faster than multiple nodes with a proven technology like Apache Spark? The answer: DuckDB runs in-process.
When your computer communicates with a database, it is using sockets. You can think of them as 2 humans using walkie-talkies. You can talk, say what you want to say and the other person is listening. The other person replies and you listen. Imagine how much faster you can communicate if you're just standing next to that person. No "Over" or pressing buttons when you want to speak. You just say what you have to say and by looking at facial expressions you know when the other person is going to respond. Communication just happens much more fluently and faster.
The same goes for using sockets versus in-process communication. DuckDB can use the same computer memory as the process it is interacting with and often doesn't even have to move data around. The bandwidth is only limited by the speed of the lanes on the motherboard between the CPU and the RAM, which has increased immensely in the last years, especially in Apple's M-chips.
Introducing: MotherDuck
So when you take the above into account, DuckDB becomes a lot more interesting to work with (in the cloud). In Why would you use DuckDB? I wrote that you could orchestrate DuckDB in the cloud "without compromises". Without compromises? Well, almost. If you embark on an adventure as described above, you might hit some complexity walls. DuckDB performs excellent as a local data warehouse but sharing your data in the cloud or running your transformations in a controlled environment can be a bit of a challenge.
This is exactly what MotherDuck is trying to solve.
MotherDuck is a managed DuckDB-in-the-cloud service. In short, as a DuckDB user, you can easily connect to MotherDuck to supercharge your local DuckDB experience with cloud-based manageability, persistence, scale, sharing, and productivity.
MotherDuck's ducklings are single-node DuckDB instances that process your data. What MotherDuck does very well is the seamless integration between your local environment and the cloud. The sheer power of DuckDB comes a lot from how easy it is to use and to get started. They did a great job of keeping that experience intact.
The following are the installation instructions for installing MotherDuck inside your DuckDB environment.
- Run this SQL query:
.open md:
That's it. When I tried MotherDuck myself, I was impressed by the ease of use. The line above opens an authentication flow in your browser and of course, there is a way to provide a token to even automate this step.
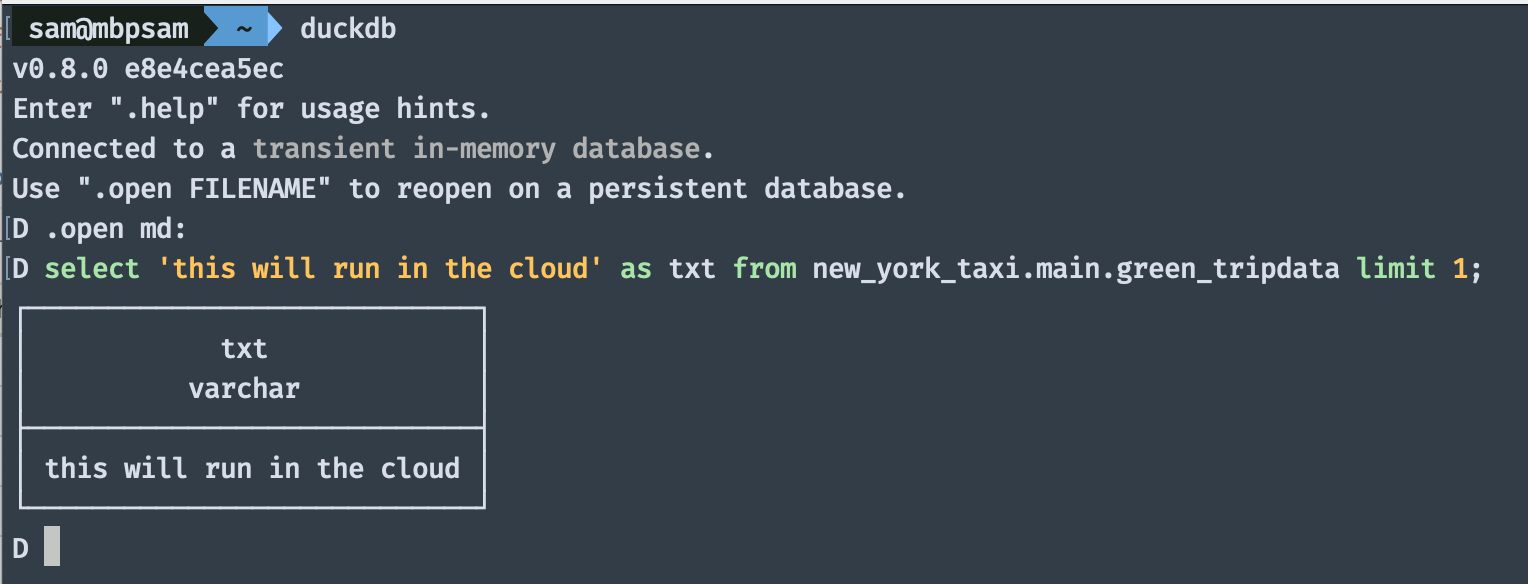
MotherDuck is a data warehouse

The team behind MotherDuck consists of former employees of Databricks, Snowflake, the designers of Google BigQuery, and more. What if you don't need a distributed cluster with multiple nodes to process your data? What if you don't have terabytes of data to process? Maybe all of your data even fits into the memory of a single computer? These days single cloud nodes can scale up to tens of GB of memory. And if you intelligently process your data, you will probably not even have to load all of it at the same time.
MotherDuck runs fully serverless. While testing the alpha version, I never configured anything related to performance. The queries ran instantly and no provisioning was required. Pricing is yet to be announced, but I expect it to be priced based on the execution time of your queries and the amount of data you store in MotherDuck.
Hybrid querying
One of the use cases for DuckDB is that you can build your data (dbt?) models locally, run them against DuckDB and when you're happy, push them to a staging or production environment where they run against your actual data warehouse (e.g. Snowflake). The local usage of DuckDB also shines in scenarios like the Modern-Data-Stack-in-a-box where you can run your entire data platform locally.
MotherDuck ties into this approach. Queries in DuckDB can use a combination of data in the cloud and local data. Even a single query can join a locally stored parquet file with a cloud-persisted table in MotherDuck. This could enable new developer workflows and I see opportunities for using this in extract & load processes.
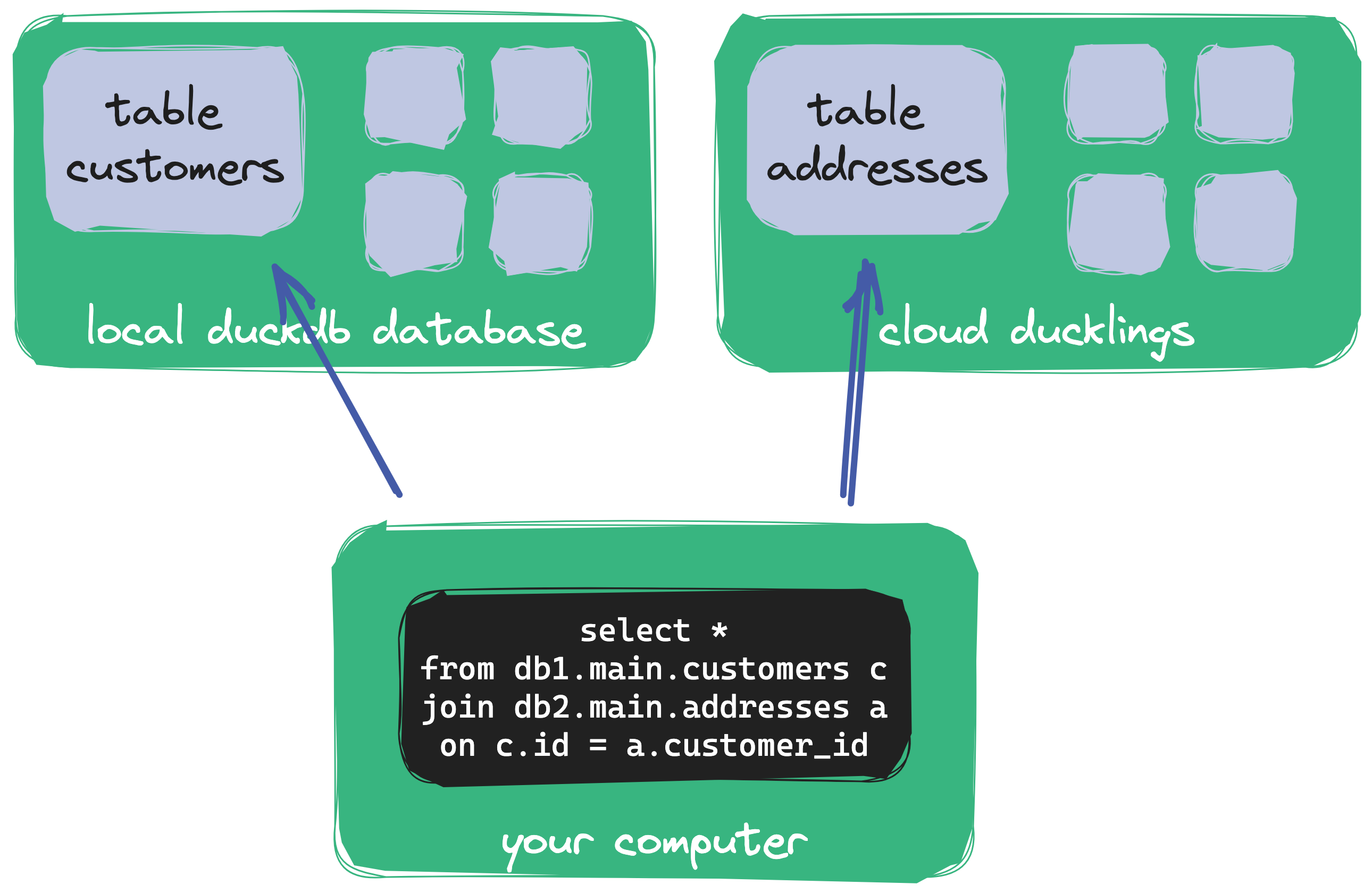
All of this makes MotherDuck a great choice as your next data warehouse.
MotherDuck could become the ideal data warehouse for users who don't need the scale of Snowflake or the extensive features of Databricks.
MotherDuck transforms your data
There is nothing that MotherDuck does more in terms of transforming data than what DuckDB already was capable of. You could use SQL, Python, Go or Java to transform data with MotherDuck. Some extra useful features are persisting credentials to cloud storage like S3 so that you don't have to put them in your code.
MotherDuck also built a UI for their platform in which you can run queries and instantly get the results. The experience will feel very familiar to users who have worked with Jupyter notebooks before. They are working on expanding this with features like built-in graphs like histograms. Interacting with MotherDuck can be done through any way you use DuckDB today or through their browser experience.
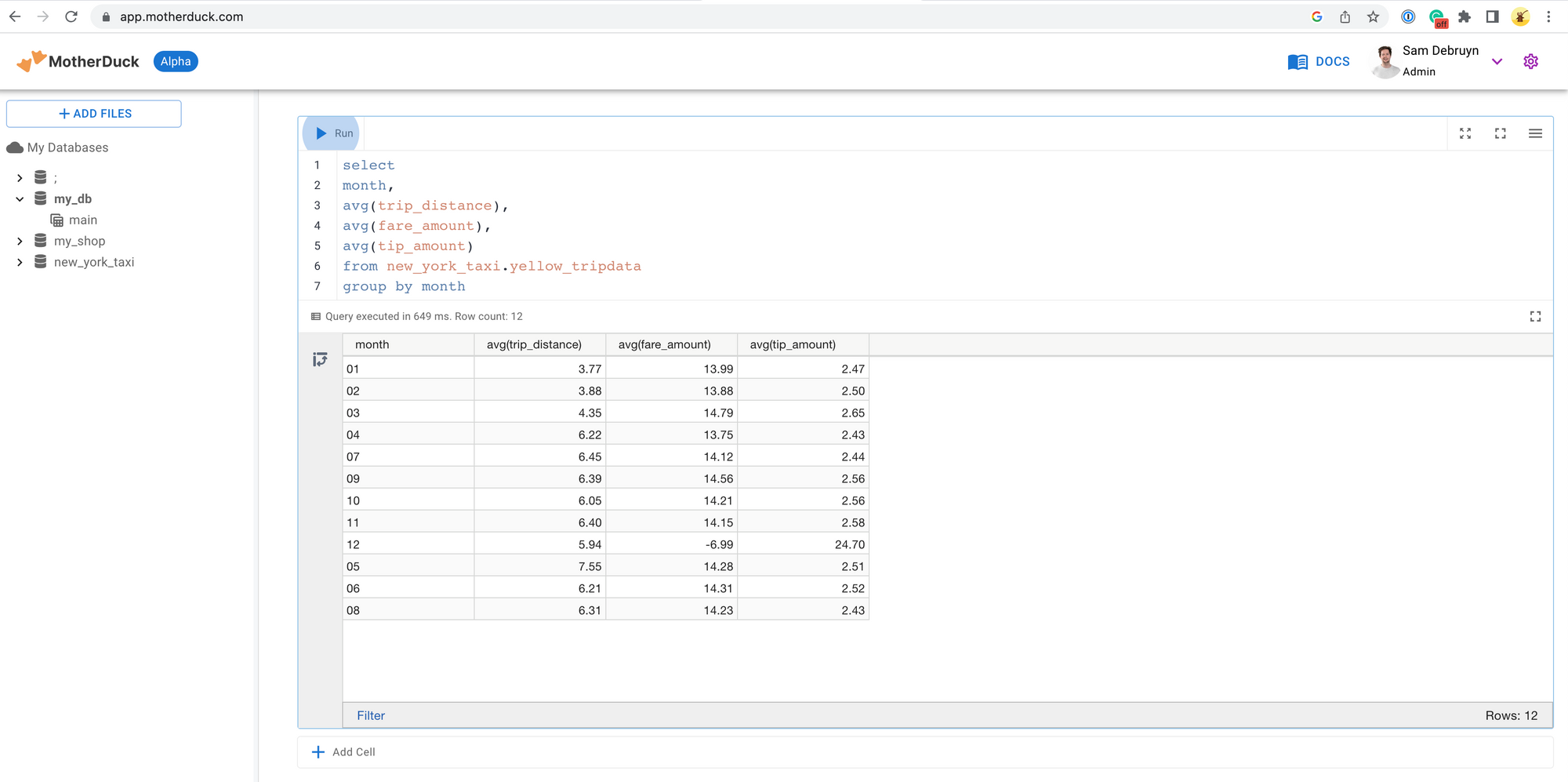
MotherDuck as an extract & load tool
MotherDuck supports the popular CTAS (Create Table As Select) statements commonly used in OLAPs to load and transform data. In this case, the data could come from any S3 location. The goal here is to add support for other cloud providers as well. I loaded 1.5 GB of New York Taxi data within 29 seconds with a single line of SQL.
CREATE DATABASE new_york_taxi;
USE new_york_taxi;
CREATE TABLE yellow_tripdata AS
SELECT *
FROM 's3://datarootsio/new_york_taxi/yellow_tripdata/**/*.parquet';
The duckling even figured out the partitioning schema all by itself. This ease of use is remarkable and quite rare.
Pushing data from a local machine into the cloud could also be as easy as running a CTAS selecting data from a local data source.
CREATE DATABASE my_shop;
USE my_shop;
CREATE TABLE customers AS
SELECT *
FROM read_csv_auto('a/local/folder/on/my/machine/raw_customers.csv', header=true);
Combine this with DuckDB's Postgres scanner or with its ability to load any Pandas DataFrame, Polars DataFrame or PyArrow object and you have a powerful tool to ingest data into the cloud.
MotherDuck for data sharing
The final SQL syntax is yet to be designed, but by running the stored procedure md_create_database_share you can already create shared databases which you could send to colleagues, clients, or other stakeholders. This is an easy way to share data without having to worry about the infrastructure.
Caveats
There is much more to it than what I described above, so I'd recommend you give it a spin. MotherDuck is still in beta and some features are missing. Make sure to read the documentation or reach out if you have any questions.
Your partner
As your partner in data, Dataroots will already consider technologies like MotherDuck or DuckDB in our proposals and technical designs.
We partnered with MotherDuck on their beta launch and are ready to help you to design and build the data platform exactly matching your needs.
You might also like

