

By Raul Jimenez Maldonado, Omar Safwat
The majority of machine learning algorithms are data hungry, the more the data we feed our models, the better they learn about the world’s dynamics. Luckily for us, data is everywhere in today’s world, dispersed over the different locations where they were collected.

Examples of this is the user data that is collected on a daily basis by our cell phones, medical equipment and practitioners in medical facilities, etc. Conventionally, if we wanted to train a learning model, we would collect the data from these multiple sources, store them in one centralised repository, and then start the training process. This process is called Centralised Learning.
Despite having proved its effectiveness, centralised learning still has some limitations. Perhaps one of the most pressing ones is the lack of data privacy. Some businesses simply can’t afford exposing their data to some remote location for model training purposes, especially with the new laws and regulations in effect that aim to protect our personal and private data. Not to mention the storage and networking limitations of having to transfer a huge amount of data over the internet from every data source to one central location.
Because of these factors, federated learning (FL) has become a hot research topic in machine learning. FL solves the problems mentioned above by doing machine learning on-site. This means that each individual device or local server trains the model on its own data and in its own environment, without communicating with the central location at all. After that, the local servers send their learned model weights to a centralised server which aggregates them and builds a global model, as depicted in Figure 1.
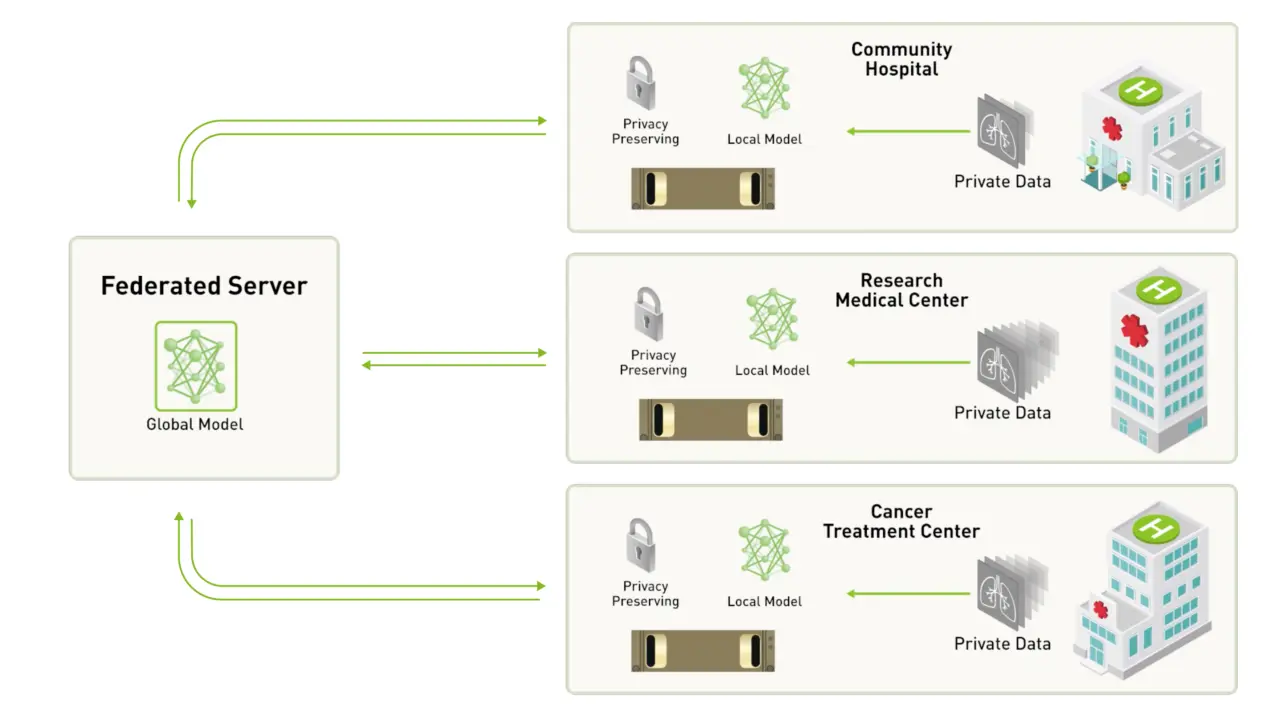
In other words, instead of communicating data, we communicate models.
Applications and previous work
Although still an active area of research, FL has already been tested in different applications and environments. Take healthcare for example, it is perhaps the number-one domain in need of a novel solution like FL to accommodate machine learning, because of the strict regulations in place that protect patients’ data. With FL in place, masses of diverse data from different healthcare databases and devices can contribute to the development of AI models, while staying compliant with regulations such as HIPAA, and GDPR.
There are several classification tasks in healthcare that have been studied using a federated learning setting, such as; cancer diagnosis, COVID-19 detection, human activity and emotion recognition, patient hospitalisation prediction, patient mortality prediction, and sepsis disease diagnosis. These recent studies were able to produce remarkable results, that are comparable to those of a centralised model. One example is the use of federated learning for predicting clinical outcomes in patients with COVID-19. The scientists applied data from 20 sources across the globe to train an FL model while maintaining anonymity. The model, called EXAM (electronic medical record chest X-ray AI model), aimed at predicting the future oxygen requirements of patients with symptoms of COVID-19. The model was trained on inputs of vital signs, laboratory data, and chest X-rays.
Advertising is also a domain that leverages user-private data to provide the best personalised experience for the users, which makes it an attractive area to test FL frameworks, especially since users are now much more aware of how much of their personal data is being collected and harvested on a daily basis. Facebook for example announced their plans on rebuilding its ads to prioritize user data privacy. The company is exploring “on-device learning”. The way this works is by running the algorithms locally on the users’ phone to figure out which ads they’d find interesting. The results are then sent back to a cloud server in an aggregated and encrypted format. That's how you end up with only cute cat pictures on your wall.
FL promises to revolutionize autonomous vehicles and the Internet of Things. First, because it safeguards user’s private data. Second, because conventional cloud-learning entails huge transfers of data and a slower learning rate. On top of that, federated learning has the potential to permit autonomous vehicles to respond more quickly and correctly, minimising accidents and increasing safety. Moreover, much research demonstrates that FL has great potential in applications such as FinTech (Finance-Technology), and the insurance sector, all of which are applications that emphasise the privacy of the users’ data.
Types of federated learning
FL learning, as many other ML frameworks, comes in different colours and flavours. These distinctions can be observed in multiple parts of the learning process, but generally speaking we can divide FL in two types based on the aggregation schema. We refer to the aggregation schema as the method by which information learned from different sources is combined into one single global model.
Centralised vs Decentralised Federated learning
First, we introduce Centralised FL (CFL). Beware not to get confused by the word centralised, the technique we are mentioning here is different from the conventional centralised learning. Similar to any other FL framework, the data never leaves its source. The reason why it’s called “centralised” is because the global model lives in a centralised location that all parties have access to. This is depicted in Figure 2
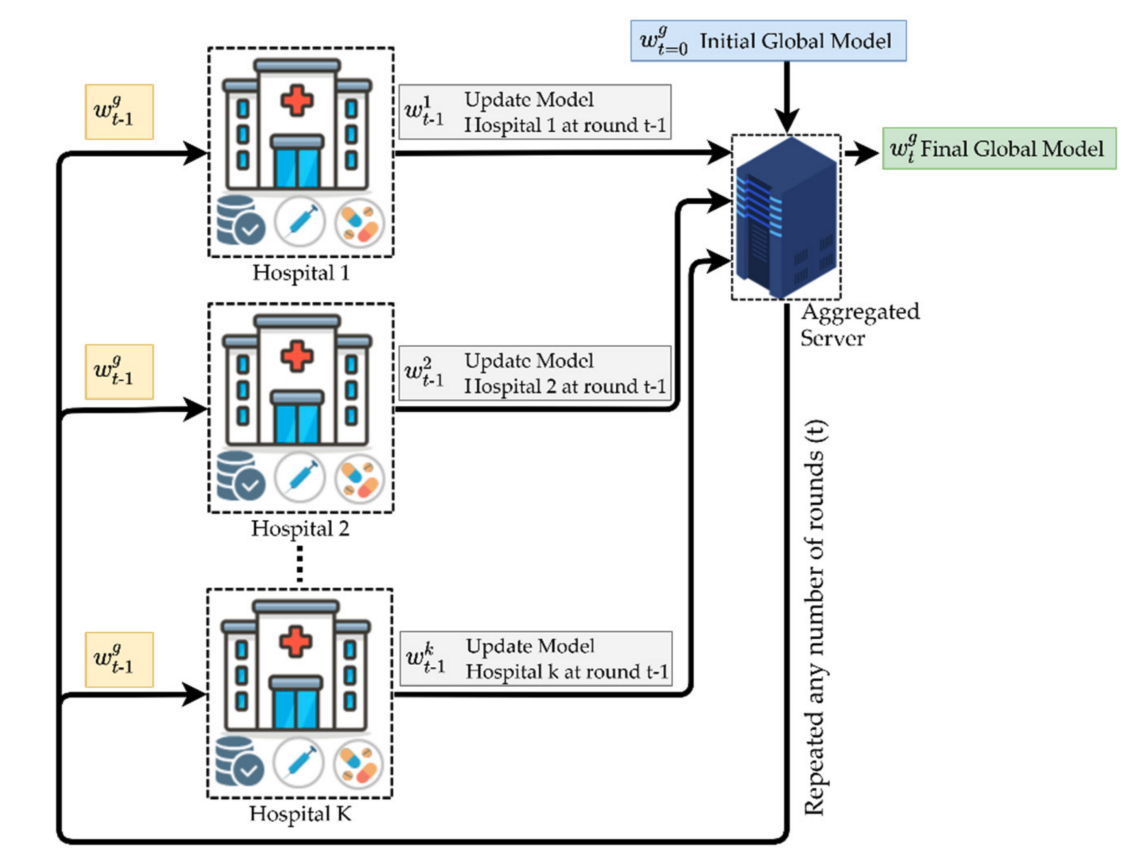
Figure 2 depicts an example of CFL where the client nodes are different hospitals. In this case, each of these hospitals will separately train a model only on their data and send periodic updates to a central server. Then, the central server will aggregate these updates to create a global model that will be sent to all clients at a later stage. However, an obvious downfall to CFL is that the central server is a single point of failure. Which means that if the central server fails the whole operation fails as well.
On the other hand, we have Decentralised FL that was created with the intention of avoiding having a central point of failure. In this setting all client nodes coordinate together to develop a global model in a decentralised fashion:
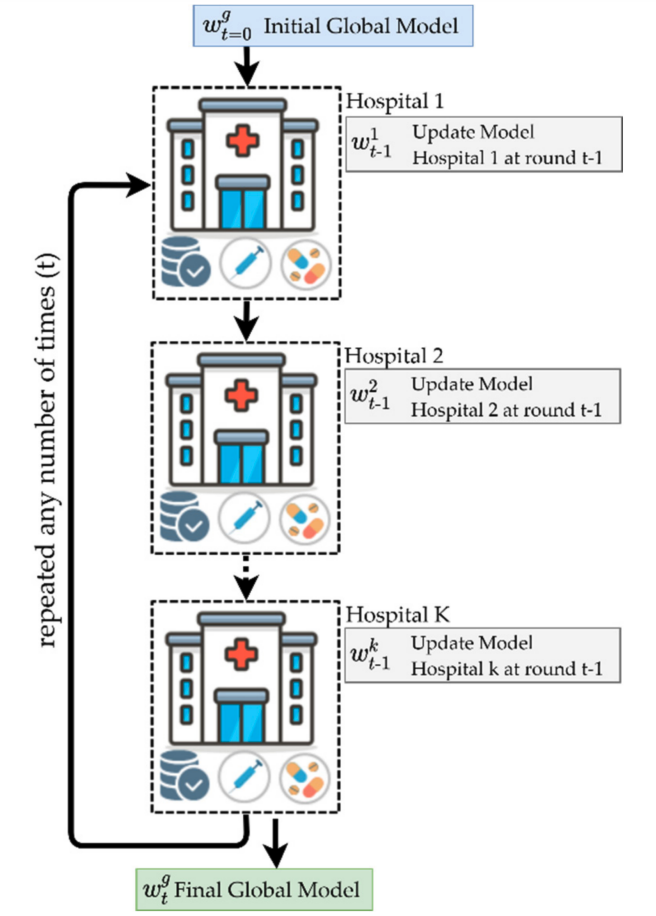
In DFL, an initial model is given to one of the client nodes, this can be a pre-trained model or a newly initialised one. This global model is updated, typically in a sequential fashion, client node by client node until a satisfactory metric is obtained. And, because there is no central server in this setting, if one of the client nodes fails, it will simply be excluded from the chain and the training process will continue without the miss-functioning node.
Horizontal vs Vertical Federated learning
At the same time, FL models can be divided according to their data partitioning mechanism namely, Horizontal FL (HFL) and Vertical FL (VFL). HFL is mostly used when there is limited sample variability between the data of the client nodes. Particularly, we want to use HFL when different samples of the same important features are present in the data of most clients:
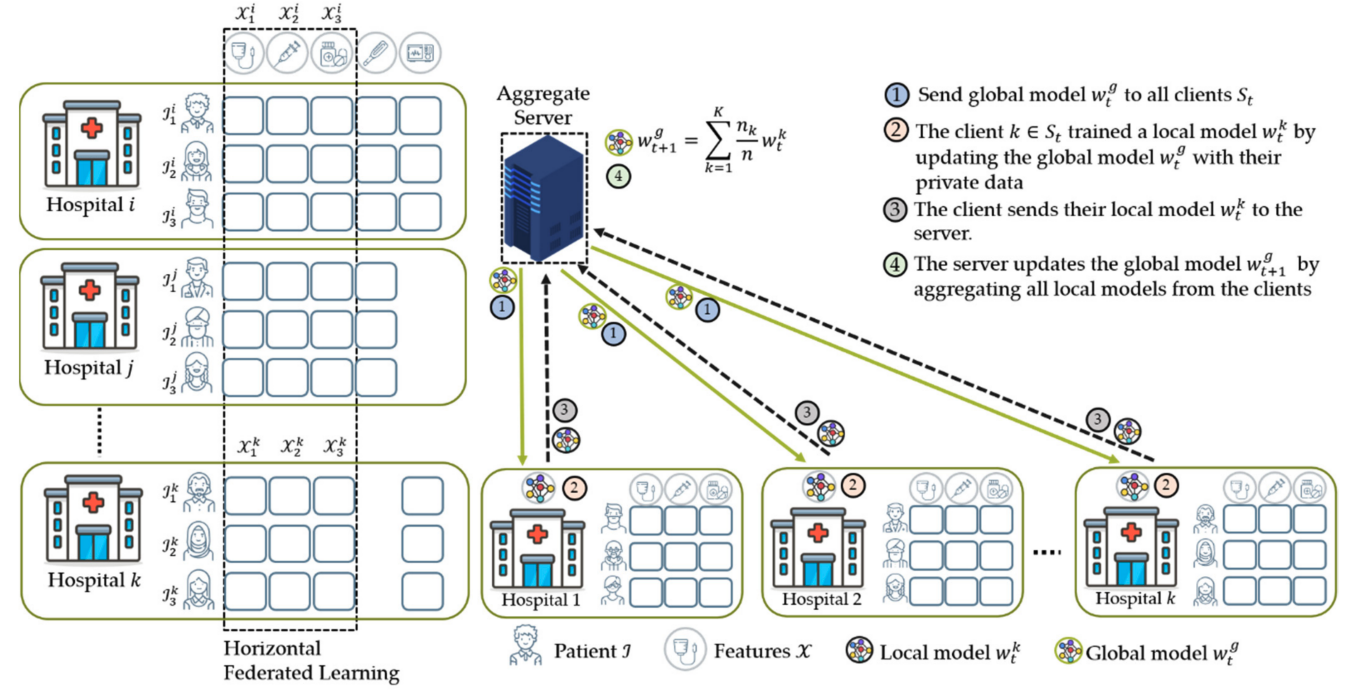
In the example above we have a scenario where different medical institutions have collected the same set of features for different patients.
On the contrary, VFL is used when the features on different client nodes are not necessarily the same but the samples come from the same subject. For example, we could have a patient going to a medical center, specialised in cardiology to get some information about his cardiovascular health and at the same time going to a separate institution to get help with his eating habits. Fl would help these two institutions combine their data “vertically” to get a better understanding of that patient:
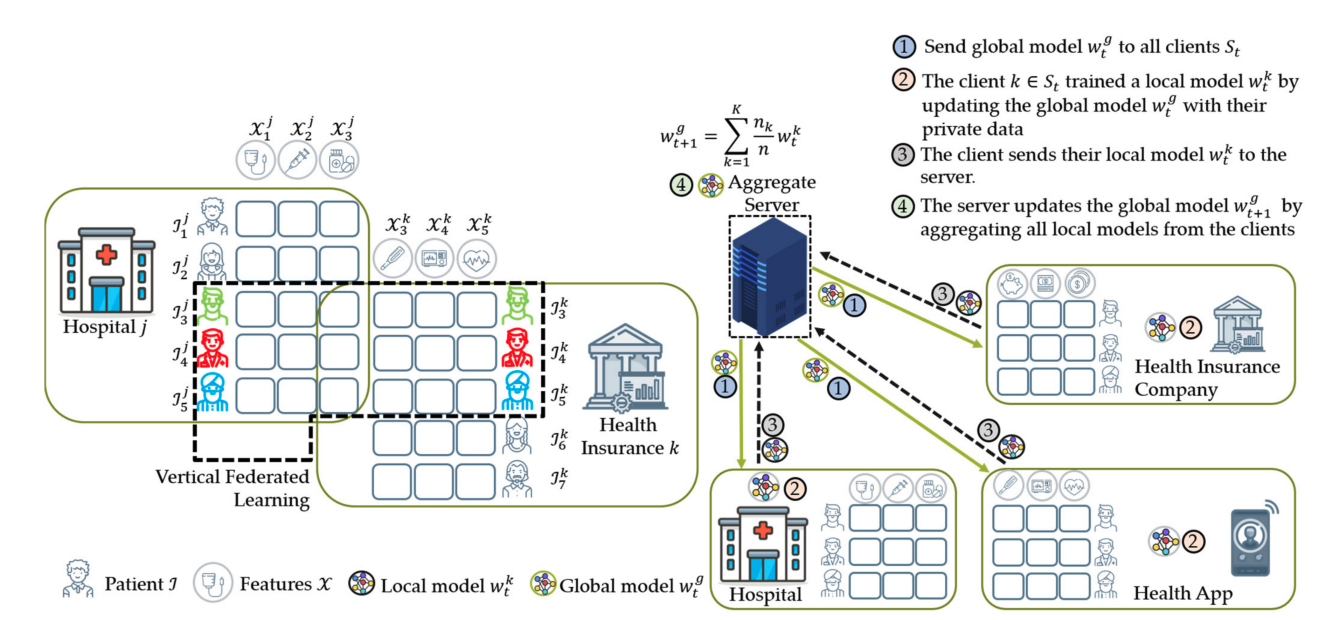
Core Challenges
Expensive communication

FL requires devices to exchange their ML parameters iteratively, and thus the time it requires to jointly learn a reliable model depends not only on the number of training steps but also on the ML parameter transmission time per step. Federated networks are potentially composed of a massive number of devices, e.g., millions of smartphones, and communication in the network can be slower than local computation by many orders of magnitude as they are sending their model updates through the network to a central device which aggregates them and then sends them back.
One way to approach this would be by reducing the number of communication rounds between the edge-devices and the central server. However, this comes at the expense of losing resolution in the information transmitted. Another solution to handling this communication bottleneck would be a technique like asynchronous SGD, which accelerates the training process by updating the parameters immediately after a computing node has sent its gradients, i.e., it doesn't wait for all computing nodes to send their gradients in order to update the global model.
Finally, we can also apply compression schemes to reduce the sizes of model updates. Some researchers have proposed gradient quantisation methods, where gradients are quantised to lower precision values to force the updating model to be sparse and low rank. There are also the methods of gradient sparsification or gradient dropping, where gradients are either sent to the server if they are larger than a predefined specific threshold or just dropped. Some studies have also investigated more complex compression schemes, such as Deep Gradient Compression. This technique employs various methods like momentum correction, local gradient clipping, momentum factor masking, and warm-up training to reduce the communication bandwidth. Yujun Lin et. al were able to achieve a two-fold compression without compromising accuracy.
System heterogeneity
Devices in a FL framework are not guaranteed to be identical. Variability can be seen in hardware specifications, communication capabilities, or even power. These issues, if left unaddressed, allow some devices to be stragglers, that is, not all devices are guaranteed to stay active at every training iteration, or it won’t be uncommon for devices to simply drop out due to connectivity or energy constraints.
During our literature review, we came across two interesting approaches to solve this. The first method is active sampling. In this approach devices participating at each iteration are selected with the aim of aggregating as many device updates as possible within a predefined time window, unlike Passive Sampling which doesn’t aim to influence which devices participate during the iterations.
The second approach is fault tolerance, which has been studied extensively in the community. Fault tolerance is critical for the participating devices, in case any of them drops out before the completion of a given training iteration. This is of course a much better strategy than just ignoring dropped devices, because that may introduce a learning bias towards those devices in the network with better connections.
Statistical heterogeneity
Data distributions at the nodes during FL are likely to be different and even biased, this could be due to a small quantity of collected data or that the data acquisition techniques are different. This data generation paradigm violates frequently-used independent and identically distributed (I.I.D.) assumptions in distributed optimisation.
FAug (Federated Augmentation), using generative adversarial networks, is one of the common approaches to solving this issue. Some researchers have shown that the natural way to address the statistical challenge (Non-IID) of data is Multitask Learning (MTL) where the goal is to learn from each node, having separate but related models. In essence, if each node has a different distribution, then we can think of each node as a new task and the goal is to learn from these related but different tasks.
Privacy concerns

Privacy and security are the primary motivation for federated learning, and it naturally ensures the privacy of input data as it only shares model learned parameters rather than the data itself. Recent studies, however, have been able to prove how training data could be inferred from its trained model update (learned parameters) with accuracy up to 90%.
To prevent malicious actors from reconstructing the data, an effective technique like Differential Privacy (DP) with relatively low communication overhead can add some noise to the trained parameters of the model before uploading them to the aggregation server. There exists, nonetheless, a tradeoff between model accuracy and differential privacy; when we include more noise to ensure privacy, accuracy drops.
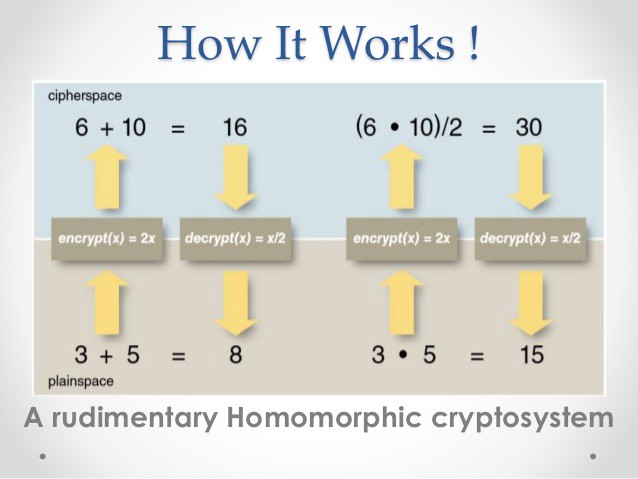
Similarly, using fully homomorphic encryption (HE), the model weights are trained on encrypted data, and only the owners of a private key can decrypt it. Even though the model is trained on encrypted data, it should have the same results on the original data after decryption, as if it were trained on the original data from the beginning. As illustrated in the figure below, operations performed on the functions encrypted with homomorphic encryption give the same results as the original function when decrypted.
Future work and open challenges

Although FL has come a long way into solving challenges that previously held back the use of AI in privacy sensitive fields, there are still some open challenges remaining.
- Handling large amounts of data in real time: Working with large streams of data is still an active area of research, particularly in a world with millions of devices all over the world generating data every second. Integrating this real time data in a meaningful way and in an energy and performance efficient manner is still a great challenge.
- Integrating different sources of data: Nowadays we have access to all sources of data, e.g. images, sounds, video, geolocation data, etc. and integrating those in a FL setup is still yet to be fully mastered.
- Data invariances and security: Although in the present study we presented several ways to deal with data invariances and keep the data secure and safe from attackers. These are not hard rules and the best methods to use will greatly depend on the application, the amount of data, the number of participating clients, etc. Finding the optimal solution with the best tradeoff requires a fair amount of research and understanding of the task at hand.
- Citizen science: Many exciting and novel opportunities are made possible with FL, an example of this is Citizen Science. That is, building a community of people that actively provide good quality data for a common good, i.e, deforestation mapping, plastic pollution on beaches, etc. The challenge remains on developing and incentivising a community to provide valuable and frequent data.
- Tooling: There is not one perfect framework to use for FL. Some people opt to prebuilt frameworks while in some complex applications it may be better to build a custom made one from scratch. Nonetheless, selecting the right set of tooling for a FL application can make the difference between a successful project and a failed one. A summary of some of the most popular frameworks is shown in the following image. Also checkout Flower for an easy to set up FL application :)
| Framework Name | Data Partition | Data Distribution | Data Privacy Attack Simulation | Data Privacy Protection Method |
|---|---|---|---|---|
| PySyft | HFL, VTL | IID, non- IID | ❌ | DP, HE |
| TFF | HFL | ❌ | ❌ | ❌ |
| FATE | HFL, VTL | ❌ | ❌ | HE |
| Sherpa.ai | HFL | IID, non- IID | Data Poison | DP |
| LEAF | HFL | ❌ | ❌ | ❌ |
References
- Li, Tian, et al. "Federated learning: Challenges, methods, and future directions." IEEE Signal Processing Magazine 37.3 (2020): 50-60.
- Li, Qinbin, et al. "A survey on federated learning systems: vision, hype and reality for data privacy and protection." IEEE Transactions on Knowledge and Data Engineering (2021).
- Mammen, Priyanka Mary. "Federated learning: opportunities and challenges." arXiv preprint arXiv:2101.05428 (2021).
- Iqbal, Z., and H. Y. Chan. "Concepts, Key Challenges and Open Problems of Federated Learning." International Journal of Engineering 34.7 (2021): 1667-1683.
- Elbir, Ahmet M., Burak Soner, and Sinem Coleri. "Federated learning in vehicular networks." arXiv preprint arXiv:2006.01412 (2020).
- Nguyen, Anh, et al. "Deep Federated Learning for Autonomous Driving." arXiv preprint arXiv:2110.05754 (2021).
- https://www.altexsoft.com/blog/federated-learning/