

By Sam Debruyn
Recap: OneLake & Delta Lake
One of the coolest things about Microsoft Fabric is that it nicely decouples storage and compute and it is very transparent about the storage: everything ends up in the OneLake. This is a huge advantage over other data platforms since you don't have to worry about moving data around, it is always available, wherever you need it.
To store the data in the OneLake, Microsoft Fabric makes use of Delta Lake. Delta is an open-source data format built upon Apache Parquet (this is why Microsoft likes to - incorrectly - call it Delta Parquet). Delta adds a transaction log to your Parquet files which enables you to do things like time travel, rollbacks, fully ACID transactions, and more. This open-source format was developed by Databricks and is now part of the Linux Foundation.
Azure Storage Explorer
Azure Storage Explorer is a free tool from Microsoft that allows you to manage your Azure Storage accounts. It is available to download for Windows, macOS, and Linux. Behind the scenes, it uses a combination of REST APIs and the great AzCopy tool to interact with your storage accounts.
Connecting to OneLake
Did you know you can connect Azure Storage Explorer to OneLake to efficiently upload a ton of data or to quickly browse through what is in there? Let's see how to do that.
Install Azure Storage Explorer
So if you don't have this tool yet, it's time to download and install it. It's a very straightforward process. You can use the link above, or if you like to use a package manager, I've listed your possible options below.
Windows users who like to use Chocolatey can install it via:
choco install microsoftazurestorageexplorer
If you're on macOS, you can install it via Homebrew:
brew install --cask azure-storage-explorer
Debian and Ubuntu users can install it via Snap:
sudo snap install storage-explorer
Get your OneLake connection string
The OneLake connection string is pretty simple: https://onelake.dfs.fabric.microsoft.com/NameOfYourWorkspace/
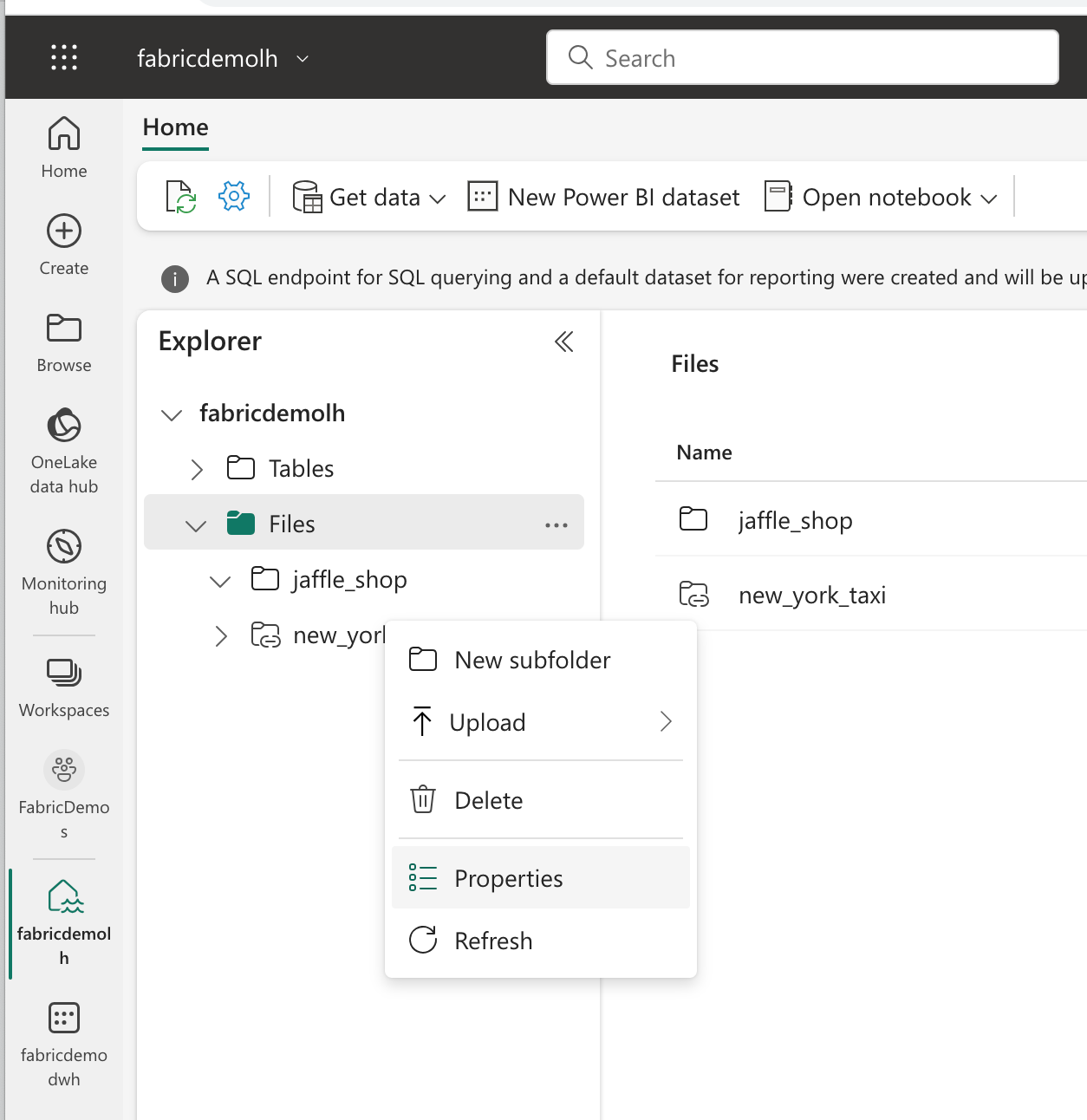
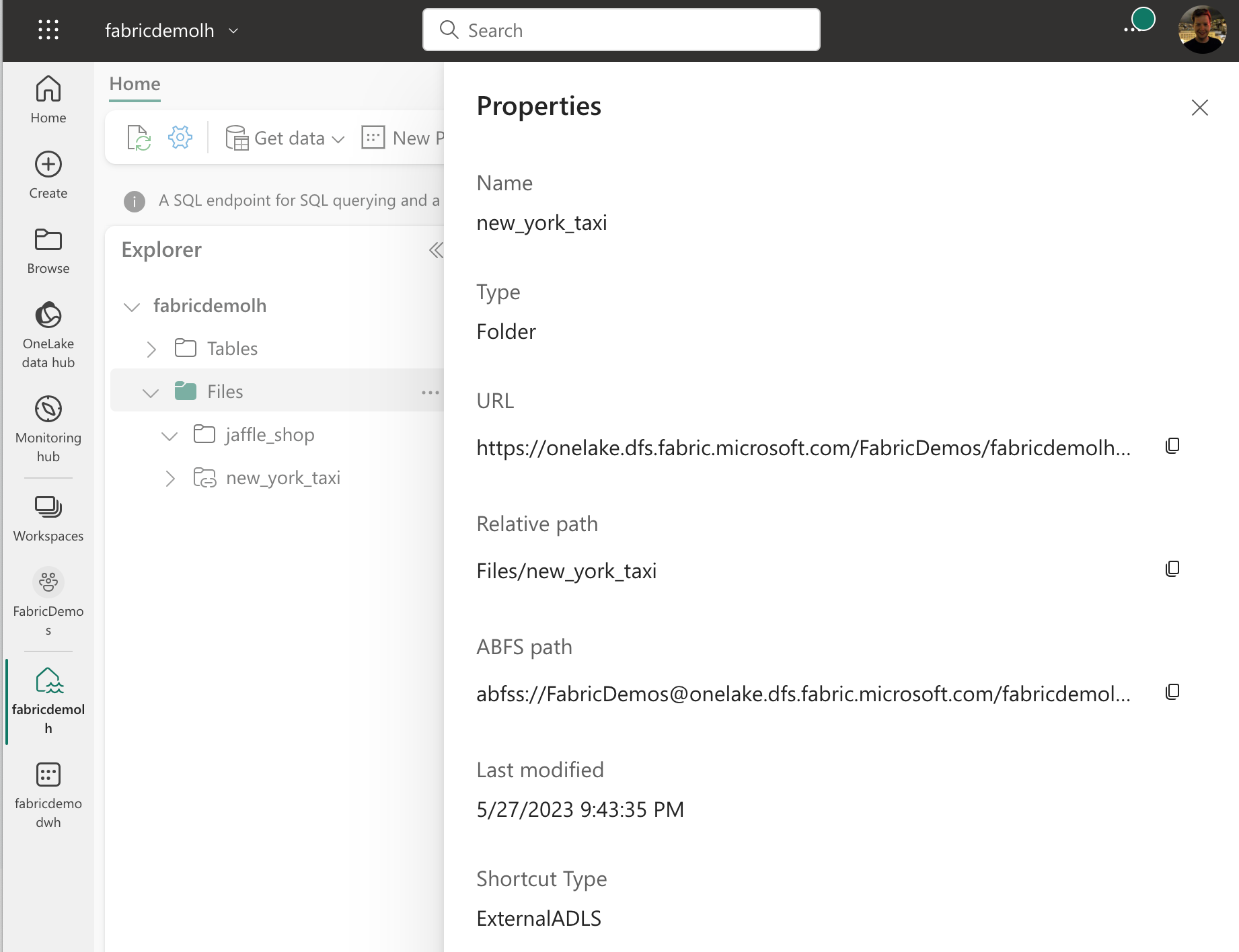
You can also find the URL to your OneLake by going to a lakehouse or a warehouse and right-clicking on the Files item in the list in the Explorer and selecting Properties. You can remove whatever is at the end of the URL and shorten it so that the name of your workspace is the last part of the URL.
Authenticating with Azure Storage Explorer
When you open Azure Storage Explorer for the first time, you will be asked to sign in. You can use your Azure AD account to sign in. Make sure to use the one you also use to log in to your Fabric workspace.
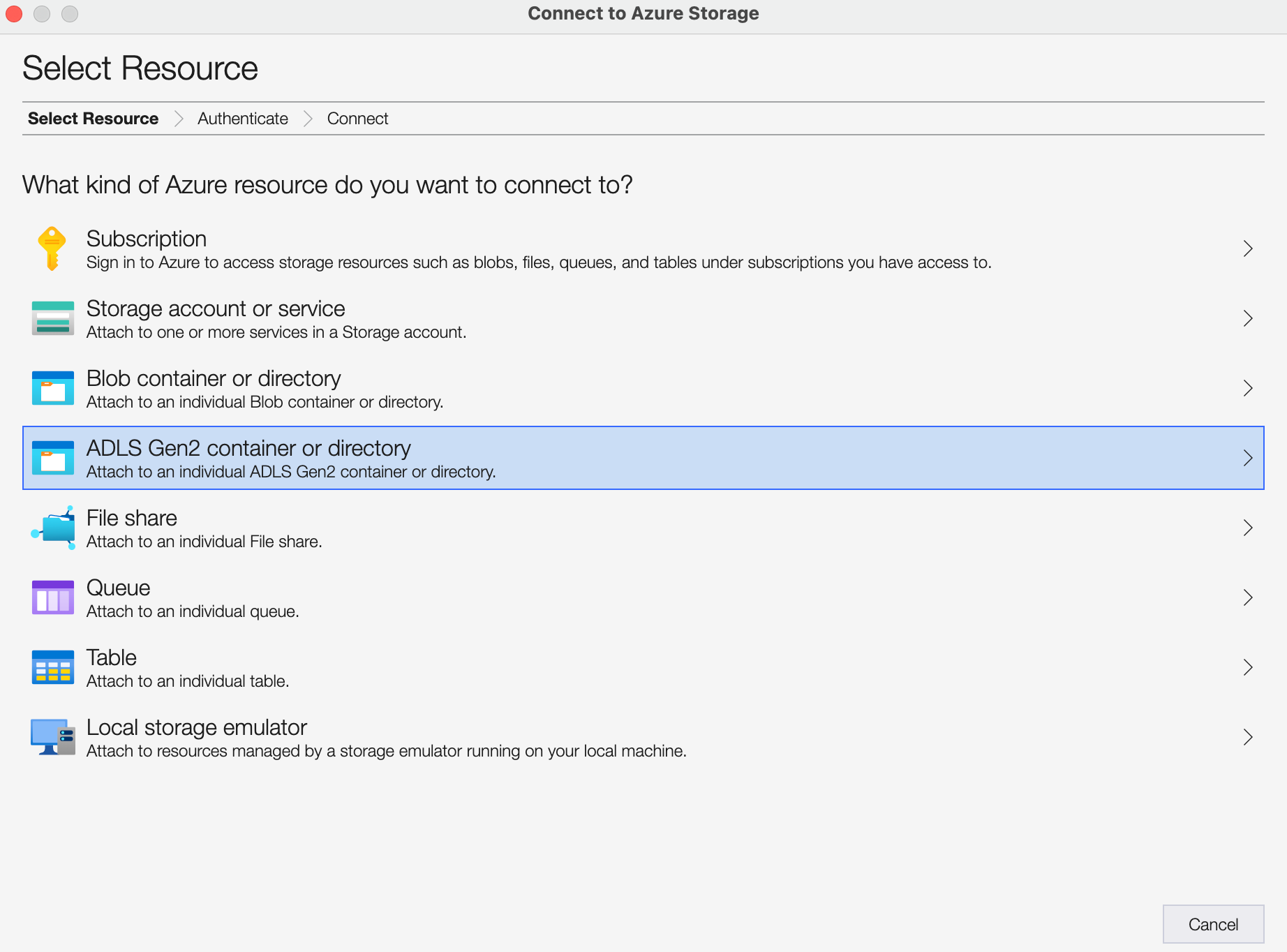
You can start the process to add your OneLake by clicking on the 🔌 icon (3rd one in the left sidebar) and then clicking on ADLS Gen2 container or directory.
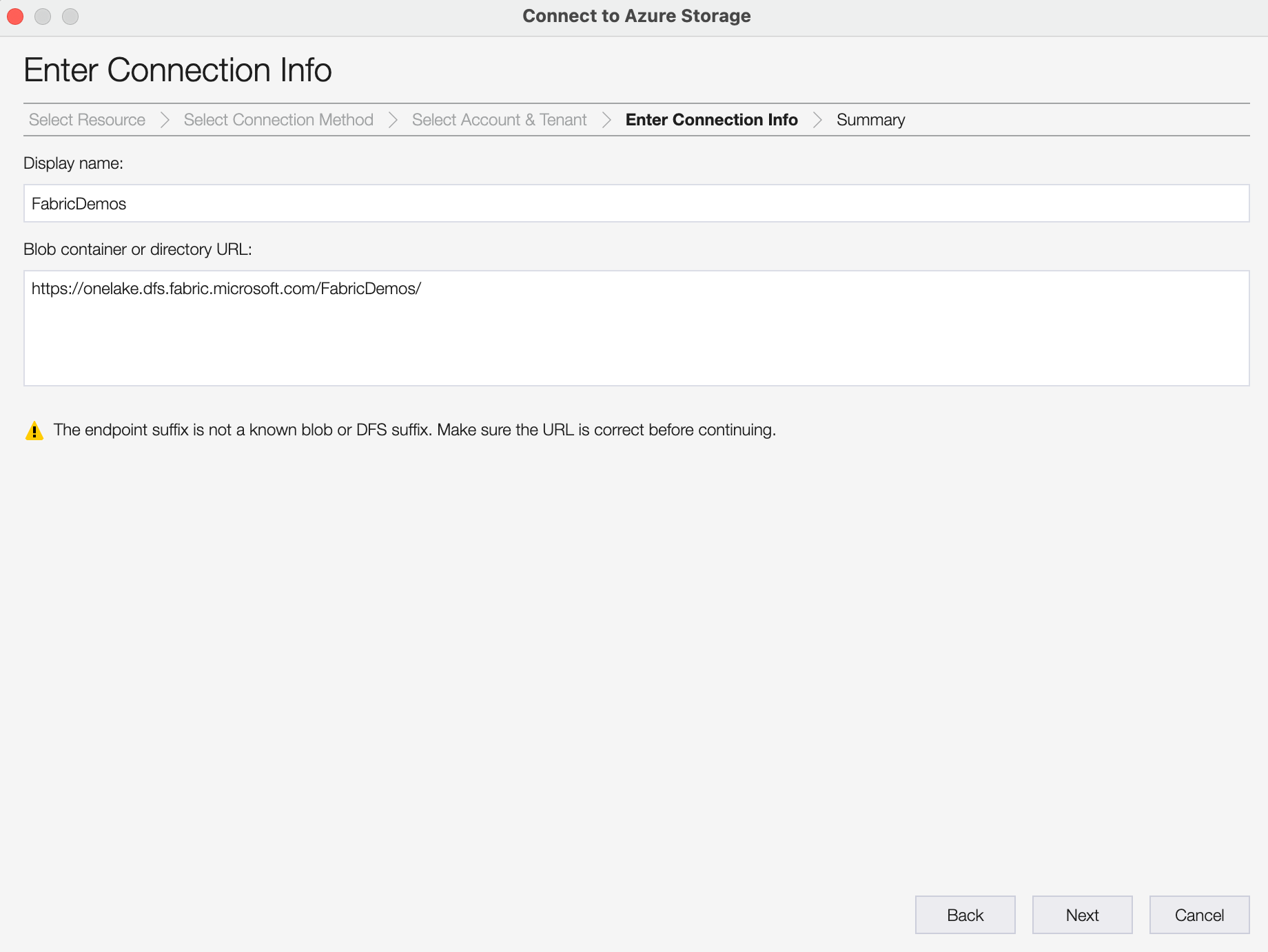
The next few steps ask you to confirm that you're authenticating with your Azure Active Directory account and then you can enter the URL to your OneLake. You can leave the Display name field empty. You'll see a warning appearing that the tool doesn't recognize the URL yet, but you can safely ignore that.
All that's left is clicking on Connect and you're good to go!
Browsing your OneLake
You can now go the first icon in the left sidebar to see your OneLake. You can browse through the files and folders and even upload new files or folders. You can also download files and folders to your local machine. The Fabric OneLake will be located under the Emulator & Attached > Storage Accounts > (Attached Containers) > Blob Containers section.
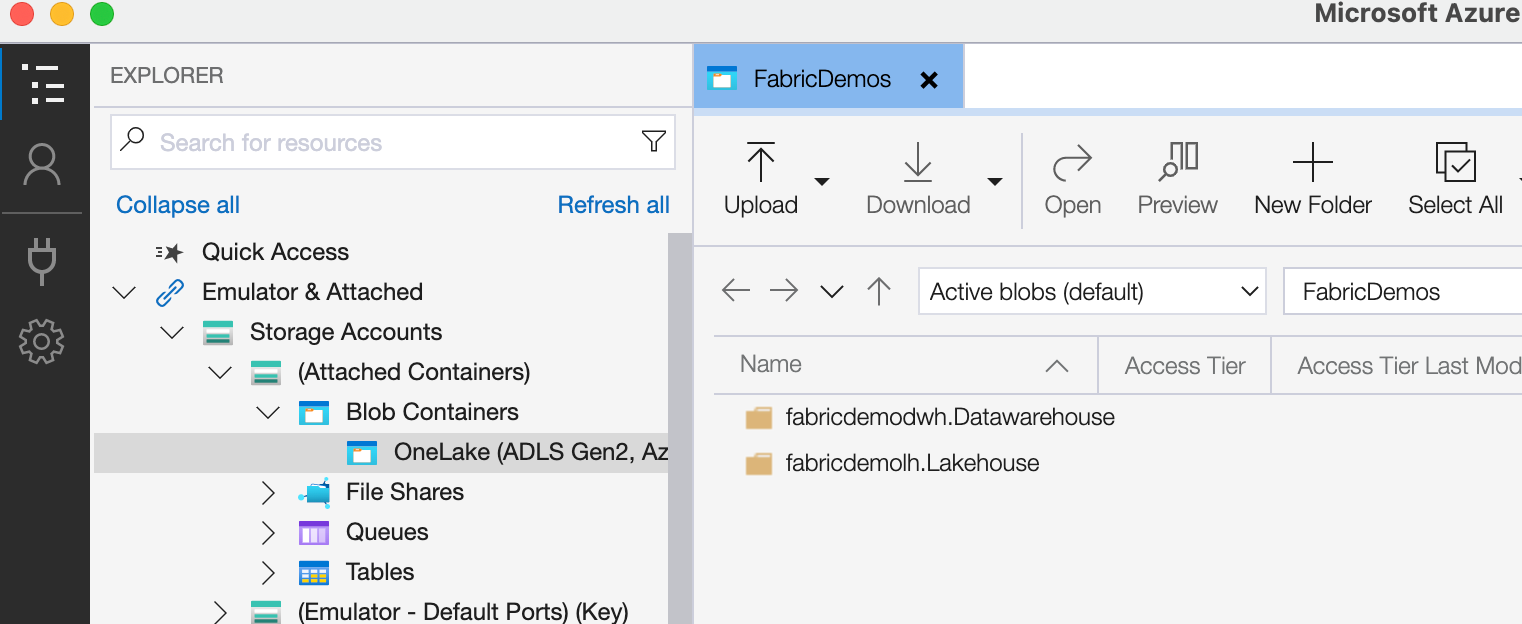
You will quickly recognize the resources you've created in Microsoft Fabric and even have a peek inside the files where you'll spot your Parquet files and their corresponding Delta Lake transactions logs.
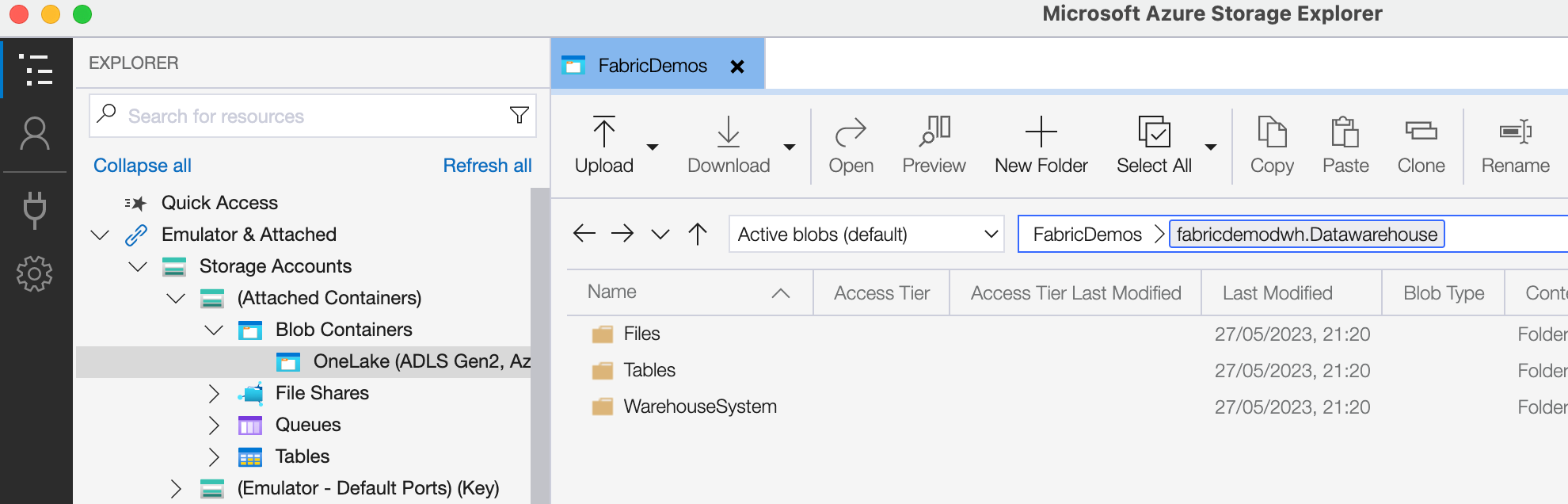
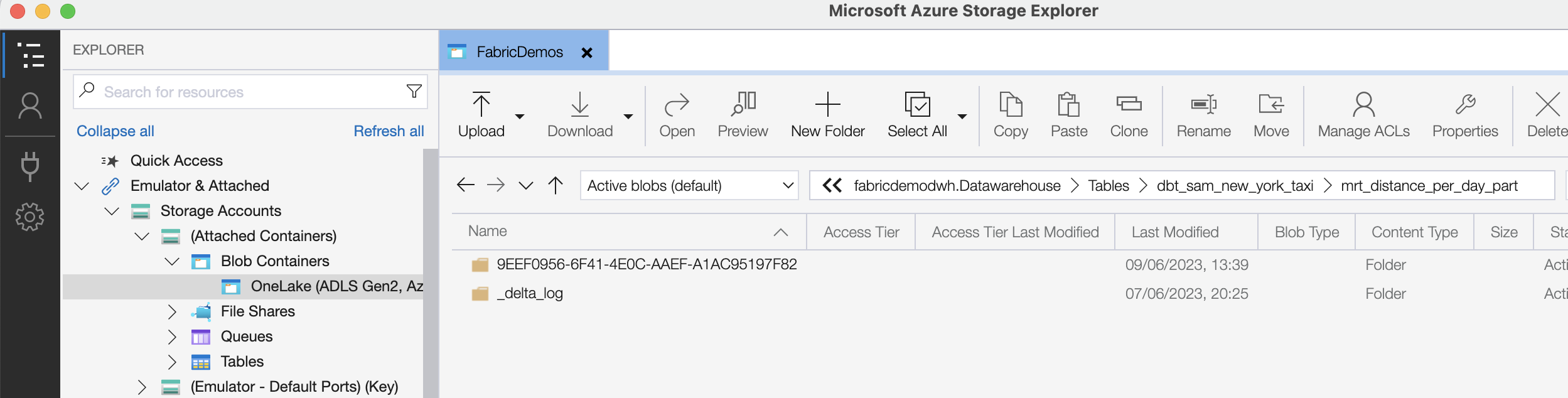
You can clearly see how Fabric Data Warehouse tables are just folders with Parquet and Delta files in them.
Upload data to OneLake
You can also use Azure Storage Explorer to upload data to your OneLake. Let's see how this works.
I went back to the root of my workspace and opened one of the Lakehouse folders. Every Lakehouse has a folder named Files, where I created a new folder called created_from_explorer. I then created a new folder inside that one called flight_data.
Then it was a matter of dragging and dropping some Parquet files into Azure Storage Explorer and my data started flowing into OneLake. In my example, I'm using flight data with about 50 million rows and about 70 columns. In compressed Parquet files I'm looking at about 1 GB of data and uncompressed CSV is about 3 GB.
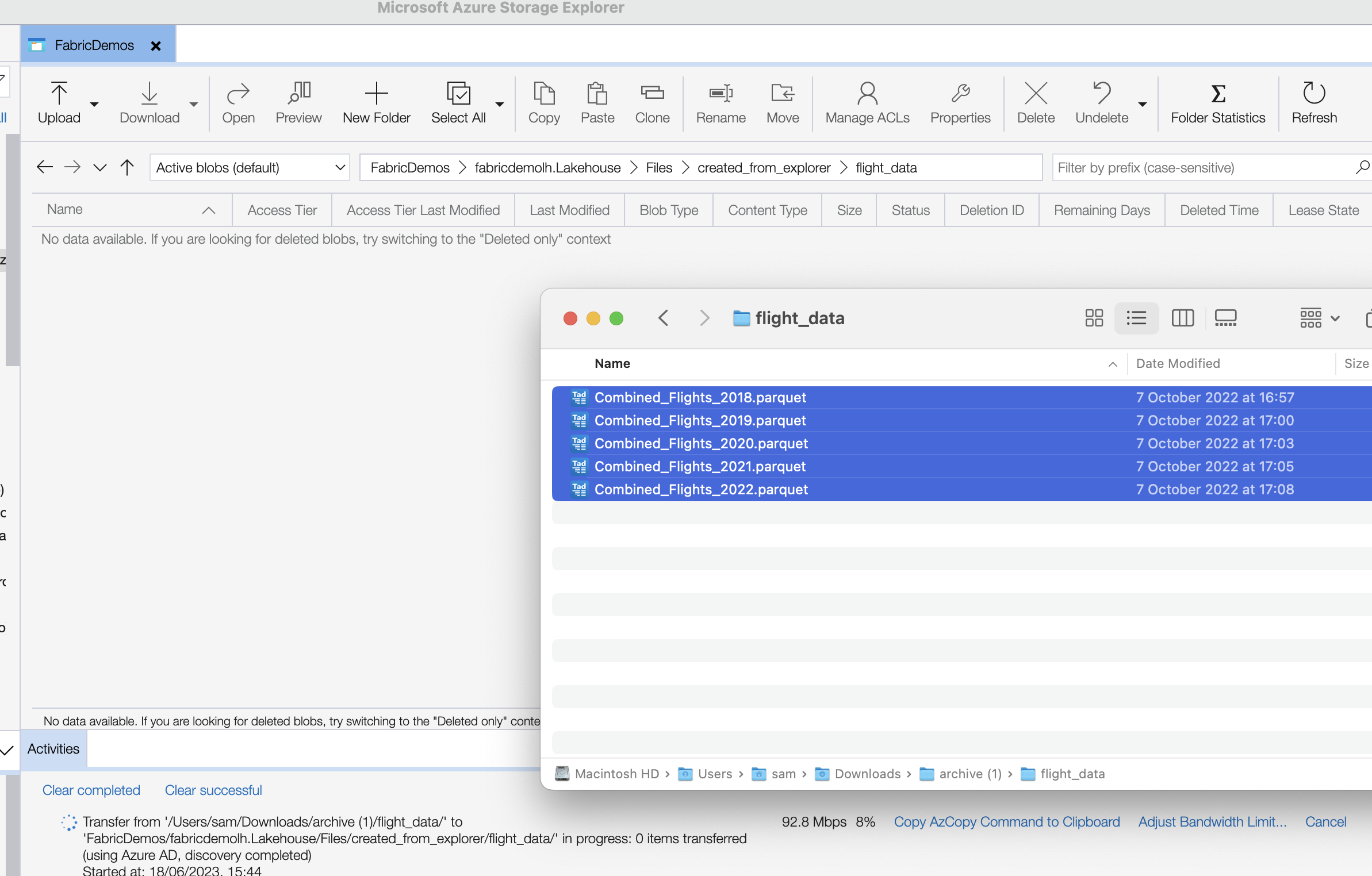
At the time of writing, Fabric Lakehouse/Warehouse is missing the OPENROWSET function to directly query this data, so I'm using a notebook with some Spark code to register the Parquet dataset directly into the Lakehouse.
df = (spark
.read
.format("parquet")
.load("Files/created_from_explorer/flight_data/"))
(df
.write
.mode("overwrite")
.saveAsTable("flight_data"))
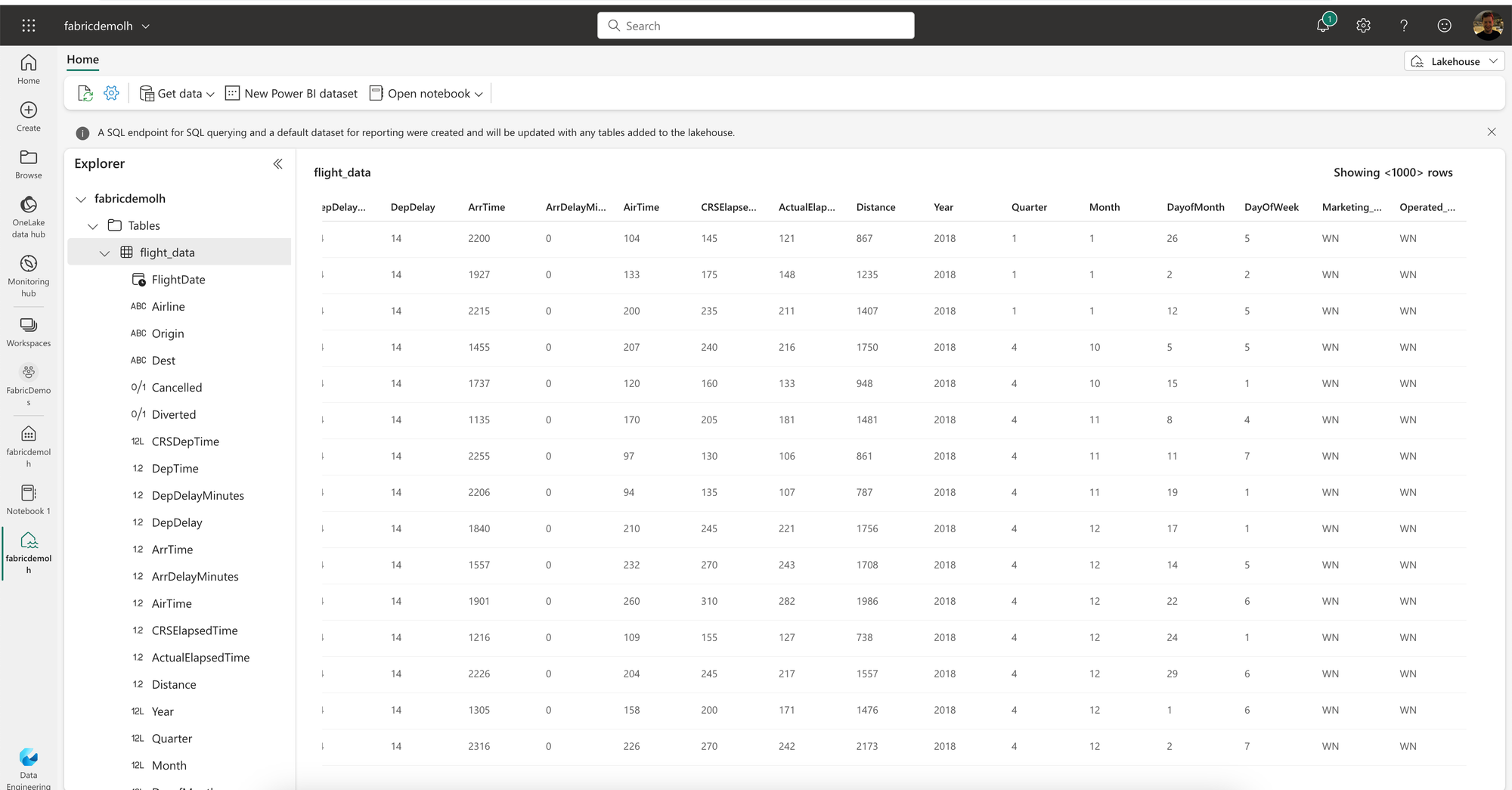
My data is now available as a table in my Lakehouse and I can use Spark SQL to query it. Note that this is not a Delta table, so I cannot use the SQL Endpoint with T-SQL for querying. If I would have used Delta files, I could have used the SQL Endpoint to query the data.
Conclusion
OneLake makes it very easy to work with your data and Fabric already has a lot of cool options to work with it. I am a big fan of this open and transparent approach where I can use the tools I already know like Azure Storage Explorer to manage my data lake.
I do hope support for T-SQL statements with OPENROWSET will be added soon so that we don't have to use the extra step with Spark to work with regular CSV or Parquet files, but that's to be expected while Fabric is in preview.
I hope you enjoyed this post and I'll see you next time!