

By Jasper Heldenbergh, Nicolas Jankelevitch
👋 Welcome! And thank you for checking out my blog post. Let me start by introducing myself. I'm Jasper Heldenbergh and I’m a student of applied informatics at UCLL. I’m currently doing an internship here at Dataroots as a data and cloud engineer. In this blog post, I will talk about my first internship topic.
❔ This post will be about Fabric and Soda, creating an integration for Fabric in the Soda Core library, and using this integration to check the data quality in Fabric lakehouses/warehouses.
🥤 Soda-core and the Soda platform
Before I talk about the integration itself, let's take a look at Soda-core and the Soda platform.
Soda-core is very simple. It’s a command line tool written in Python, capable of performing tests to maintain data quality and reliability. With this tool, you can define data sources, as well as your own checks to perform on these data sources. As of writing (16/04/2024), you can use more than 40 integrations to define your data sources. Some of these integrations include PostgreSQL, Airflow, Snowflake, DuckDB, and many more. You will probably not need all of them when using Soda, so you can install the integrations you need with pip install soda-[integration]. All integrations and how to install them can be found here.
Even though Soda-core is a Python library, no Python or SQL code is needed to write checks or create data sources. Everything is configured using YAML files. For writing checks, however, soda-core uses the intuitive YAML-based SodaCL language.
Then, there is the Soda platform. This subscription-based platform is built on top of Soda-core and provides an easier approach to the workflow like a dashboard and scheduled checks. The platform also comes with SodaGPT, an LLM with the task of converting user descriptions of desired checks to SodaCL code.
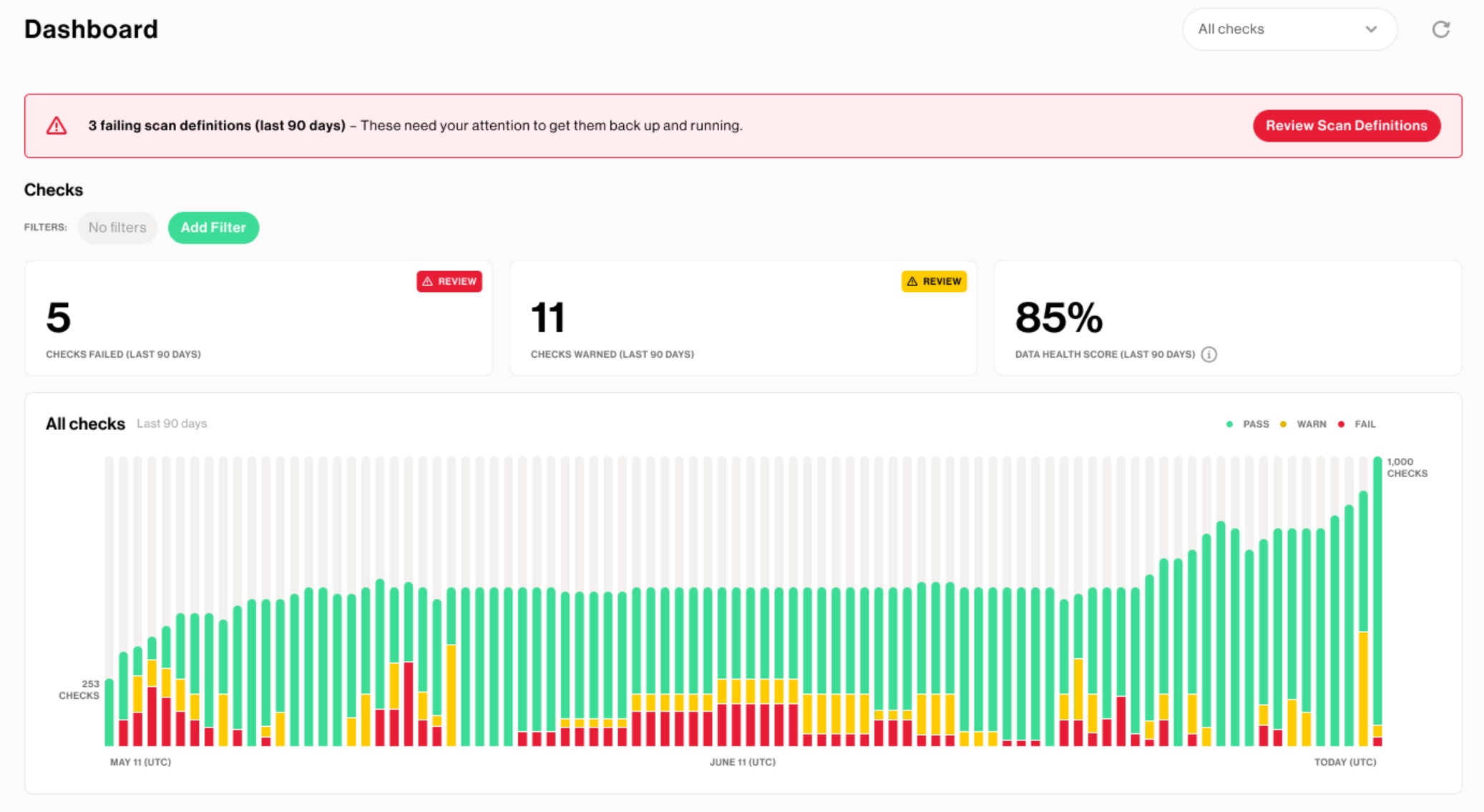
In most cases, Soda is configured using just 2 YAML files:
In the first YAML file, configuration.yml, you write YML on how to connect to your data source(s). The credentials may depend on what integration you want to use, but can always be found in the Soda documentation.
The second YAML file, checks.yml, contains all the checks you want to perform. This is also the file where you write in the SodaCL language.
That’s it! It really is as simple as installing a Python package and adding 2 YML files. The best way to show the functionality of Soda is with an example.
An example use-case
Let’s say you want to do some checks on your user data table in a Postgres database. And you chose Soda for this. This can be done in a couple of simple steps:
- You will need to install the Postgres adapter with
pip install soda-core-postgres. For this, you’ll need to set up an environment of Python 3.8 or greater. - Next, we’ll need to tell Soda where to look for our data source. To do this, you’ll need to create a
configuration.ymlfile containing this info. It will look something like this:
data_source my_cool_database:
type: postgres
host: localhost
port: "5432"
username: soda
password: secret
database: postgres
schema: publicAn example of a configuration.yml file
💡 Multiple data sources can be added in this file, you can choose which one to use in a later step
Test the connection (optional)
You can test the connection between Soda and your data source with the command soda test-connection -d my_cool_database -c configuration.yml .
-drepresents the name of the data source you want to test.-crepresents the name of the configuration file.
If successful, it should show an output like
Successfully connected to 'my_cool_database'.
Connection 'my_cool_database' is valid.
- Now that Soda knows where to find your data, the next thing is to define what checks it has to do on that data. As mentioned, this is your
checks.yml:
# Checks for our "users" table. Syntax is "checks for <your_table_name>"
checks for users:
- missing_count(email_address) = 0:
name: No missing email addresses
- duplicate_count(email_address) = 0:
name: No duplicate email addresses
- invalid_count(email_address) = 0:
name: No invalid email addresses
valid format: email
- invalid_percent(phone_number) < 10%:
name: No more than 10% missing phone number values
valid format: phone
An example of a checks.yml file
These are some simple checks written in the SodaCL language. SodaCL provides over 25 built-in checks and metrics to choose from. The example checks above will ensure there are no missing emails, no duplicate emails, and that all emails and phone numbers are valid formats, respectively.
- Now you’re ready to test. In this case,
soda scan -d my_cool_database -c configuration.yml checks.ymlwill perform the scan. In the command we need to specify which data source we need to test on, the name of our configuration file where Soda can find the connection details, and the name of your checks file. The result of the scan should show an output like this:
Scan summary:
3/4 checks PASSED:
users in my_cool_database
No missing email addresses [PASSED]
No duplicate email addresses [PASSED]
No invalid email addresses [PASSED]
1/4 checks FAILED:
users in my_cool_database
No more than 10% missing phone number values [FAILED]
check_value: 23%
Oops! 1 failure. 0 warnings. 0 errors. 3 pass.
An example of a summary of a Soda scan
This scan shows us that not all of our tests passed. We had a test that had to check that there are no more than 10% missing phone numbers in our users table. Soda pointed out that the actual percentage is 23%.
Why integrate Fabric into Soda?
From a workaround point of view, Soda already has existing support with PySpark, and PySpark can ultimately be used in Fabric notebooks. So what’s the benefit of a direct connection with Fabric lakehouses or warehouses? Let’s go over a few of them.
You don’t need to know Python to use Soda, so let’s keep it this way in using Soda for Fabric. Using PySpark defeats this idea, as Python code is needed to configure Soda.
A direct connection doesn’t have to rely on Spark (obviously). Cutting out this middleman results in less complexity and better performance.
Every Fabric Spark notebook needs a couple of minutes to create a session when running for the first time. I know that that’s not an issue for a notebook that would take 10 minutes on its own, but for something as simple as using Spark just for Soda it’s a waste of time.
It’s convincing enough to create a direct connection between Soda and Fabric (also because it’s my internship topic and it would be strange to refuse).
🚀 The game plan
As mentioned, it would be optimal to create a direct connection between Soda and Fabric. This way, we can scan Fabric warehouses and lakehouses with Soda to receive insights on data quality and freshness. To achieve this, a new data source connection must be implemented into the Soda core library, to connect to Fabric warehouses and lakehouses. After this addition, users can easily install and use this connection like any other Soda data source by executing pip install soda-core-fabric.
🔍 Finding some data
🗺️📍 To get some data for getting started, I was recommended to use some of the public NYC Taxi Trip Records datasets. In total, I picked 3 sets, containing data for January from 2021 to 2023 (no specific reason). These datasets contain info about (unsurprisingly) taxi trips in New York City, having columns like the pick-up and drop-off date time, the number of passengers, the distance, the type of payment, the tip amount and other fun stuff. These datasets were in the parquet file format.
🚕 There is nothing about the car or the driver, so I looked for more to add. I found a dataset containing frequently used taxi cars on Kaggle. This dataset contains info about things like the model, the brand, the colour, the engine and fuel type. This dataset was in the CSV file format.
👤 To represent the drivers, I constructed something using Faker that has columns like the name, social security number, sex, blood group (I wanted to), home address, email address and birth date. To get it a little bit more realistic, I made sure around one in five taxi drivers are female. This dataset was in the CSV file format.
📂 Loading the raw data into Delta tables
I uploaded the datasets in a new Fabric lakehouse following the medallion architecture. Using a PySpark notebook, I loaded each file as a dataframe and saved it as a Delta table. This resulted in 3 tables that serve as our bronze layer called bronze_cars, bronze_drivers and bronze_trips. Afterwards, we can create staging data with small transformations like dropping unnecessary columns, adding columns based on calculations, type casting, and more. The result will ultimately be our silver layer.
🔀 Transformations using dbt
Microsoft Fabric has multiple tools to load and transform data. One way to do that is with a Dataflow. Dataflows are the textbook way to connect to various data sources and perform some light transformations. Afterwards, they can be stored in a lakehouse or any other analytical store.
Another way to do this is with Apache Spark. Spark is an open-source engine for data processing and is also available in many other data platforms as a processing option. In Fabric, you have notebooks in which you can use the Spark engine in the forms of various coding languages like Java, Scala, SQL and (the most popular) Python. This makes Spark also a viable option for transforming data. With Spark, you can load data from lakehouses/warehouses into a dataframe (similar to Pandas dataframes). This dataframe can then be explored and transformed before saving it as a delta table.
⬆️ Both methods have their pros. Spark is very flexible by working with multiple coding languages and a lot of Python packages, and Dataflows have a neat and feature-packed visual interface.
⬇️ Both also have downsides. Spark needs a couple of minutes to create a session when running for the first time, and Dataflow takes quite a while to stage and refresh (1) (2) (3).
✅ Ultimately, I chose for dbt. dbt is a workflow for SQL-based transformations. It has great features like version control and easy CI/CD. What I like the most about dbt (and it’s a really great strength) is its modularity. In dbt, you build models. These models can reference each other. Every model has its own purpose, like staging models containing the initial layer of transformations applied to your raw data, intermediate models performing a bit more complex transformations like joins to implement business logic, and fact models for gaining a better understanding of optimizing business processes. Modularity builds the entire transformation process in layers which provide abstraction and re-usability. It’s really great. Did I mention it’s open source?
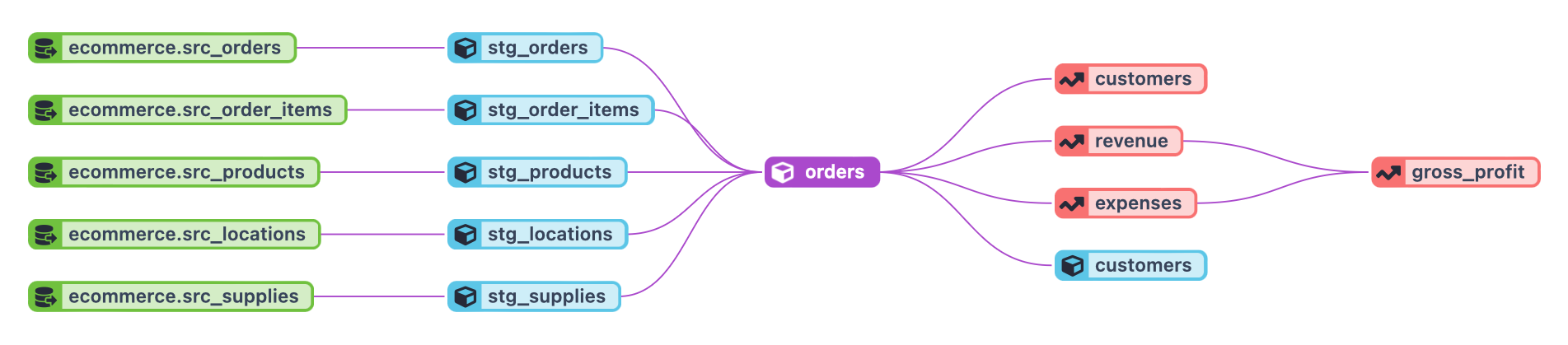
dbt also has out-of-the-box testing, but we’re not here to do that. This is where our Soda comes in.
Result
Let’s ask GPT-4 for a diagram of loading the raw files into Delta tables, getting dbt to do the transformations, and getting the models back into the Lakehouse. Just to save some time:
Something went really wrong there, here’s a more human version:
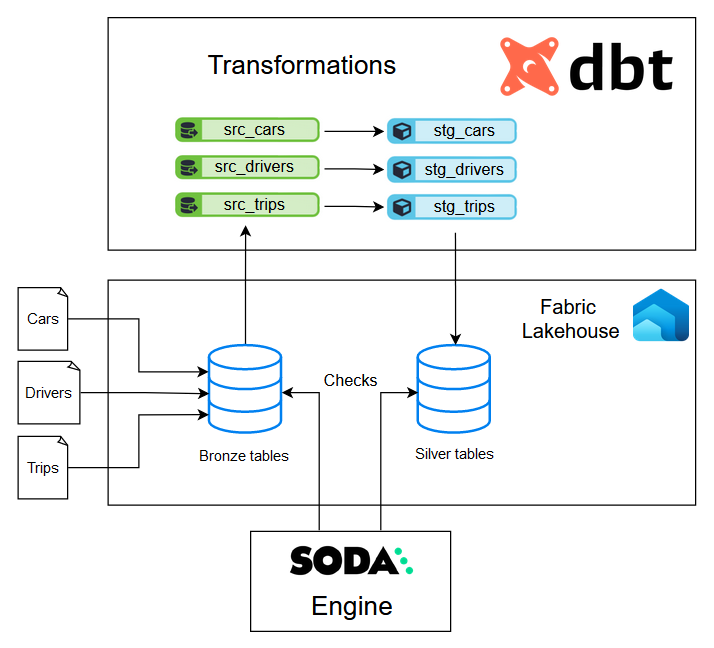
📋 Testing with Soda
Now that our transformations are done, we can use Soda to test our raw and staged data.
The integration
I created an integration for Fabric by contributing to the soda-core library. If you want to check out the result of the integration, you can find it here.
Authentication
We’ll need Soda-core to access our lake- and warehouses in Microsoft Fabric, so we’ll need to think about how it will authenticate. There are a lot of ways to do this, like Azure CLI, Service Principals, SSO, using your browser, and more. For this case, I chose to create a Service Principal. To use this in Python, I had to use the ClientSecretCredential class from the azure.identity Python package. Sam wrote an interesting blog post on how to authenticate with similar credentials here, from which I shamelessly stole some code to use for my case. Thanks, Sam!
Implementation
Soda-core makes it easy to contribute to new data sources. Every data source is represented as a folder in the core library. For creating a new data source for Fabric, I had to create such a folder, using the following file structure:
├───fabric
│ │ docker-compose.yml
│ │ LICENSE
│ │ setup.py
│ │
│ ├───soda
│ │ └───data_sources
│ │ fabric_data_source.py
│ │
│ └───tests
│ conftest.py
│ fabric_data_source_fixture.py
│ test_fabric.py
A tree view of the integration
An overview of the important files/folders:
docker-compose.yml- This file sets up a Microsoft SQL server with Docker, this emulates Fabric and is used for testing.setup.py- Info about the data source, like the name and what libraries it needs.fabric_data_source.py- The main file where the logic of the data source is. Everything in this file makes the integration work for Fabric. To list a few requirements:- How to connect to a fabric lakehouse/warehouse
- What data types there are in an MS SQL database
- What credentials are required of the user to use this data source
- How things like email addresses and phone numbers should be validated
As well as the logic for checks:
- How to find the table where checks should be performed
- How to find all rows with a specific limit or filter
- How to group by a specific column
- How to find duplicate rows
/testsfolder - This folder is for testing the data source using thedocker-compose.ymlfile.
Soda encourages contribution by providing a class named DataSource. This class already has logic present for a data source to work, and it can be seen as a skeleton to build your own adaption for the integration on top of it. This is useful because this way I only need to overwrite the stuff that is different for my integration.
Using the connection
You’ll need Python 3.8 or greater, and Pip 21.0 or greater for this. Once my pull request gets accepted, you can install the Fabric data source package with pip install soda-core-fabric. For the configuration file, it should look something like this:
data_source fabric_lakehouse:
type: fabric
connection:
driver: 'ODBC Driver 18 for SQL Server' # Or a similar driver
host: 'jxze2...7rhy.datawarehouse.fabric.microsoft.com'
port: '1433'
database: 'database'
schema: 'schema'
tenant_id: '<your-tenant-id>'
tenant_client_id: '<your-client-id>'
tenant_client_secret: '<your-client-secret>'
# Optional
trusted_connection: false # Default: false
encrypt: false # Default: false
trust_server_certificate: false # Default: false
configuration.yml
For the host, you’ll need to fill in the SQL connection string of your lakehouse or warehouse:
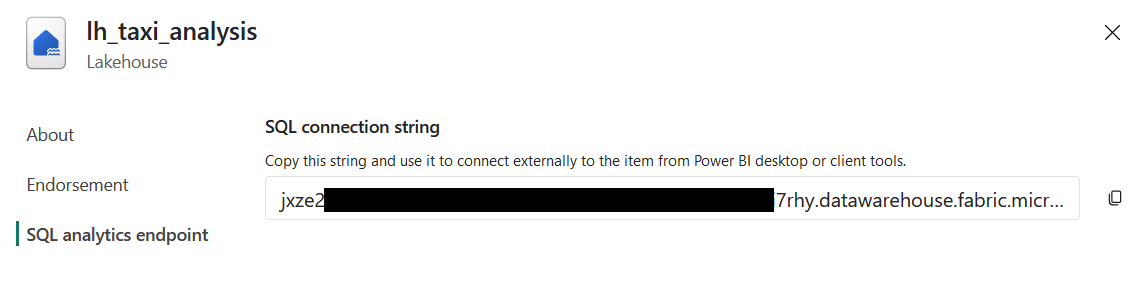
Our service principal, which is needed for authentication, can be created in the Azure portal. From the dashboard, expand the hamburger menu on the top left, and select “Microsoft Entra ID”. Then, click “App registrations” in the left menu. Here you see a list of existing applications. If you have no apps yet, check out this guide to create one.
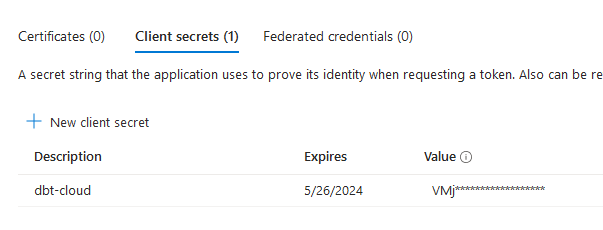
When you have an app registered, you can select it to see more info. To use our service principal to authenticate, we'll need the application ID, tenant ID, and a client secret.

The client secret needs to be created first by going to the certificates and secrets, and clicking "New client secret". Give it an accurate description and an expiry date.
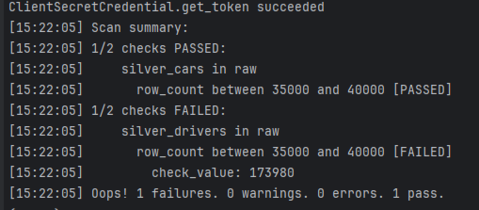
Now, create a checks.yml file and write some checks. Then, scan your data source with soda scan -d fabric_lakehouse -c configuration.yml checks.yml, and voilà!
Summary
In this blog post, we explored the integration of the Fabric data source within Soda, to perform data quality checks within Fabric lakehouses and warehouses. Soda offers us a straightforward approach with little configuration and without any programming knowledge. This was then shown through a practical example.
There was a need for a direct connection to Fabric lakehouses or warehouses, offering advantages over the indirect method involving PySpark. This direct approach simplifies the process, while also keeping the no-code mentality, and reducing the time required to establish Spark sessions. We used and prepared multiple datasets, loaded raw data into Delta tables, and transformed this data using dbt, chosen for its modularity and SQL-based workflow.
Additional observations
T-SQL certainly doesn’t make it as straightforward as PostgreSQL or MySQL in terms of using Regex. I’ve noticed this when trying to overwrite the default method in the Fabric integration to detect a valid email address.
In the Soda core library, emails are detected with the following expression by default:
^[a-zA-ZÀ-ÿĀ-ſƀ-ȳ0-9.\\-_%+]+@[a-zA-ZÀ-ÿĀ-ſƀ-ȳ0-9.\\-_%]+\\.[A-Za-z]{2,4}$
A simple breakdown of this expression in order:
- One or more letters, digits, dots, hyphens, underscores, per cent signs or plus signs
- An @ symbol
- One or more letters, digits, dots, hyphens, underscores, per cent signs or plus signs
- A period
- A word between 2 and 4 letters that contains upper- or lowercase letters
This expression matches a pretty wide range of email addresses. But this can sadly not be used in T-SQL due to its limitations with regular expressions. For T-SQL the pattern looks something like this:
%_@__%.__%
A breakdown of this expression in order:
- At least one character
- An @ symbol
- At least two characters
- A period
- At least two characters
This expression is very broad and can match many strings that are not actually email addresses, you can however improve this validation with extended string manipulation or UDFs, but there is no out-of-the-box solution like fully supported Regex.