

By Sophie De Coppel
Christmas is around the corner and you are still missing some cool Christmas cards? Well I got the thing for you! Don’t let artist block control you and start creating with the help of AI.
This last year has been mind blowing with the rise of recent AI art generators like DALL-E, Midjourney and their open-source nephew, Stable Diffusion. Consequently, we at Dataroots were very excited to start a collaboration with Prismax to explore these models and help artists use them for cutting edge art creation. Together with them, we accelerated their production pipeline by implementing a tool to create high-quality images and video loops in the their specific artistic style. Interested in how we did it? Come with me on a short 10 minutes adventure into the deep space of Stable Diffusion.
Stable confusion
Understanding Stable Diffusion without any mathematical or technical background can be a bit daunting and confusing at first. An easy way to look at AI models is typically to view them as a small child learning a task by repeatedly trying it until it learns a successful way to do it.
In layman’s terms, diffusion models learn by adding some noise to an image and repeatedly trying to remove this noise again to recreate the original image. By doing this for millions of images with various amounts of noise, they learn to fill in the gaps. Eventually, the AI comprehends this denoising process so well that they can even create coherent images starting from pure noise. Stable diffusion optimizes this by (among other things) guiding the denoising process with text input.

A technical deep dive
Stable Diffusion is built upon a variation of diffusion models, called the conditional latent diffusion model (LDM). A latent model improves upon the general diffusion model by working on embeddings of the images instead of the images themselves. The architecture of Stable Diffusion then consists of three main parts:
- The variational autoencoder (VAE) that compresses the images from the pixel space to a smaller dimensional latent space. This encoder focuses on capturing a more fundamental semantic meaning of the images. This decoder part of the VAE converts the denoised latent image into its pixel representation
- The U-Net block with a ResNet backbone denoises the output from the forward diffusion process. This denoising step can be flexibly conditioned on a string of text, an image, and other modalities. The encoded conditioning data is supplied to the denoising U-Net by a cross-attention mechanism.
- An optional text encoder is used for conditioning on text. This pretrained model is typically the CLIP ViT-L/14 text encoder, although it is replaced in the newest 2.0 version by openCLIP. This encoder also includes an AI-based Safety Classifier enabled by default. It understands concepts and other factors in generations to remove undesired outputs for users. This safety feature can be disabled within the code, but StabilityAI warns that it is not responsible for the misuse that can arise from this.

The secret is in the prompt
If you’ve spent time experimenting with any AI image generators recently, like Stable Diffusion, DALL-E, or MidJourney, you’ll have noticed that a well-worded prompt is crucial. A well-engineered prompt is the difference between turning your idea into an award winning image or getting some horrifying monstrosity with entirely too many arms that will haunt you for the rest of your life.
Although the idea behind these AI image generators is similar, the way you can talk to them is different. For example, Stable Diffusion thrives on specific prompts. The more details you give it, the better. A general prompt will looks somewhat like this: “A [art style] of [subject],[other modifiers: colours, camera lens, resolution, ….], by [artist]”



However, this format is not strict. Adding an artist or a specific art style is only meant to guide the model and is completely optional. Similarly the order of words can also be exchanged. Using a very detailed prompt with multiple artists and subjects can also help guide the process to a specific mix of the keywords given.
If you want to put more emphasis on a certain word in you prompt, a common solution is to place it more to the beginning of your prompt. This will help the model focus its attention on it. Additionally, some user interfaces (like Automatic1111's) also allow for prompt weighting. This technique increases the weight of a word by placing round brackets around it. The more brackets there are, the more attention. Otherwise, if you want to do the opposite and avoid something in your resulting images, the negative prompt comes to the rescue.
Apart from all the theory, one can also learn by practice, or even better: the practice of others. Below is a non-exhaustive list of some amazing websites.
Prompt websites to the rescue
- The Stable Diffusion prompt book — a visual guide explaining the basics of prompt building with many examples.
- Krea — a collection of images generated by Stable Diffusion and their corresponding prompts which is searchable by keyword.
- Lexica — similar to Krea but includes additional parameter settings (like the amount of steps, guidance scale or resolution)
- Arthub — similar to Lexica with the addition of an upvoting system.
- Stable Diffusion Artist Style Studies — A non-exhaustive list of artists Stable Diffusion might recognise, as well as general descriptions of their artistic style. There is a ranking system to describe how well Stable Diffusion responds to the artist’s name as a part of a prompt.
- Stable Diffusion Modifier Studies — a list of modifiers that can be used with Stable Diffusion, similar to the artist studies.
- The AI Art Modifiers List — A photo gallery showcasing some of the strongest modifiers you can use in your prompts, and what they do. They’re sorted by modifier type.
- Top 500 Artists Represented in Stable Diffusion — By analyzing the dataset of Stable Diffusion all artists and their prominence in the dataset or listed here.
- The Stable Diffusion Subreddit — The Stable Diffusion subreddit has a constant flow of new prompts and fun discoveries. If you’re looking for inspiration or insight, you can’t go wrong.
With new models coming out every month, prompt-engineering keeps evolving. StabilityAI recently released their newest model v2.1, a new iteration of the version 2 series. To minimise copyright risks, StabilityAI rebuild the dataset for these models. Specifically, it used a better NSFW filter and does not support artists or celebrities in the prompt anymore. The user is still able to finetune their own model by scraping images of the celebrity or artist from the internet, but now the responsibility lies with the user. And lastly, from experimentation of other users, we know that negative prompts have become essential with these version 2 models to get a high-quality output image.
Bringing it to life
Stable Diffusion also offers image-to-image functionality. This feature lets the user supply both a text input and an image input (which can be a photo or simple sketch). Stable diffusion then adds some noise to this image and uses it as a starting point instead of starting from random noise. Now, Deforum hacks this image-to-image functionality to create animations with Stable Diffusion. By using the current frame as an input for the next, they are able to preserve some consistency between frames and create a video.
Similarly, we improved upon this feature to create video loops by using a weighted average of the previous frame and first frame as input. The weight of the first frame will increase gradually to the end of the video, providing a smooth transition. Additionally, this functionality can also be used to provide image inputs at certain points in the video creation process.
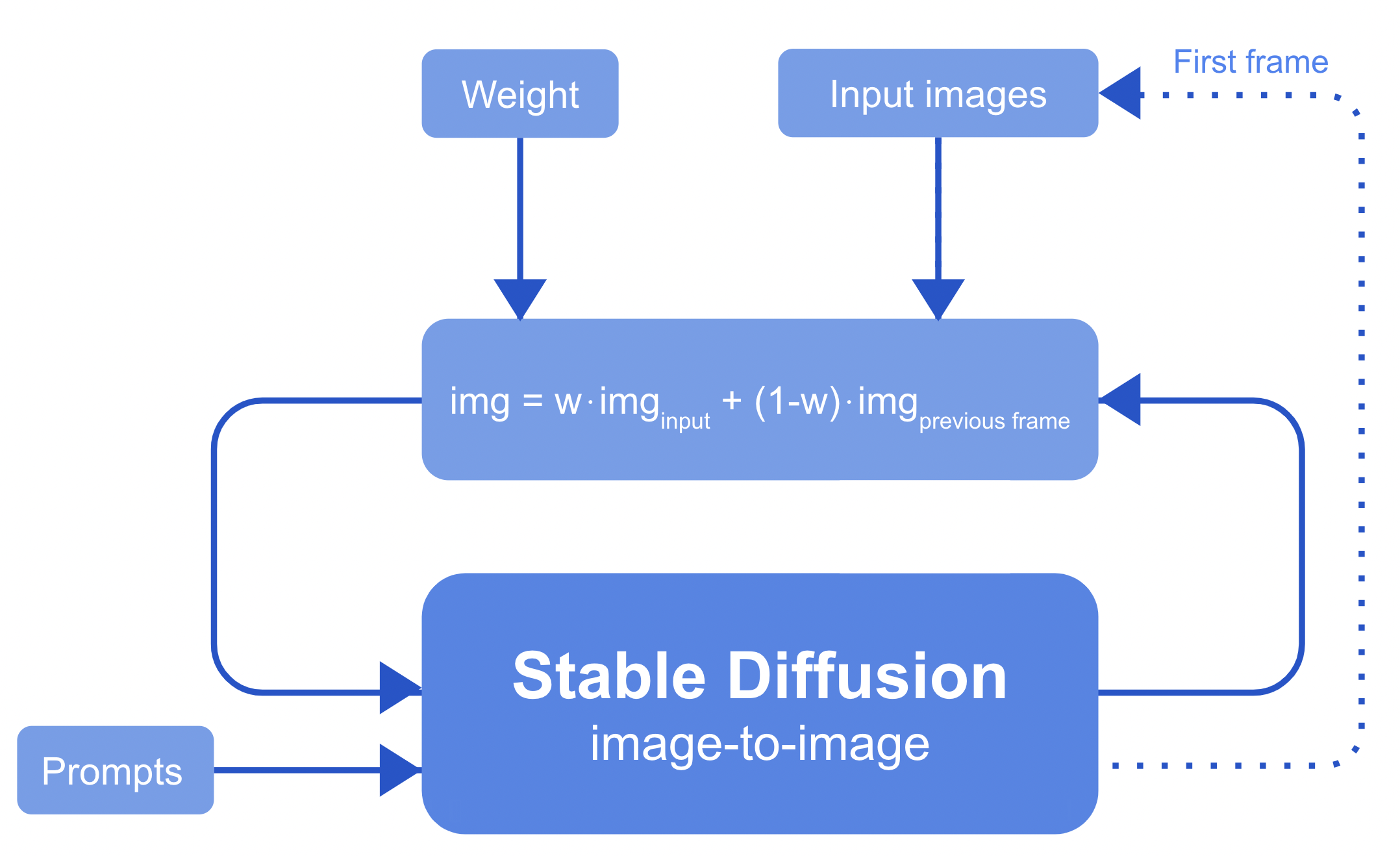
In depth explanation
Let's get more into the details. The formula image = weight • image_input + (1-weight) • image_previous_frame has three important factors:
- The weight is a matrix containing a value between 0 and 1 that is calculated according to a sigmoid that takes into account the current frame id, the total amount of frames and the amount of frames it is allowed to use for the transition (supplied by the user).
- The input image is one of the images supplied by the user, selected according to its accompanying keyframe. At the beginning of the animation, the first frame is stored and added to the list of input images to be used again at the end of the video to create a loop.
- The previous frame is the frame just created by the animation loop.
To provide a smooth transition even with camera movement, the input images are transformed according to the cumulative reverse camera movement such that they gradually come into the frame in a natural manner. The weight matrix is transformed accordingly. Additionally, the user also has the ability to provide strength variables with the input images to further control the output.
Although this addition to Stable Diffusion allows to create some sort of video, these animations do not compare to real footage. The main shortcomings of these animation are its missing understanding of motion, the lack of control during the video creation process and the lack of temporal consistency.
There are some tricks to improve the output quality of the video, such as using video input, experimenting with the diffusion cadence, strength schedule or seed schedule. Additionally, one can also use external software such as After effects or Ebsynth as a post-processing step.
Making dreams come true with Dreambooth
On its own, Stable Diffusion is limited to the art styles and concepts it knows from its database. Consequently, creating art of yourself was initially impossible (unless you were a celebrity). Luckily, this limitation was overcome by the creation of Dreambooth, a tool to fine tune your own custom model.

Now, the possibilities are endless. Do you want to create custom Christmas cards in your specific style or with the family pet? No problem! Collect around 20 images of you favourite pet, resize or crop them to 512 by 512 with the help of Birme and you can start training. You can either use an online Colab notebook (with a free GPU) or use the latest optimized version in Automatic1111's web user interface. This last option requires a local GPU however. If you don't want to go trough the hassle of installing everything, you can also opt for the online (paying) option Photo Booth.
Bridging the gap (between artists and code)
Nevertheless, all the possibilities these models bring would be lost if artists could not interact with the tools. As much as a developer may think that it is not hard to clone a Github repository and run their code, for some non-coders this may already be a first hurdle to overcome. Therefore, a well constructed and documented user interface is key to expend AI art community.
One of the most popular user interfaces is the webui of Automatic1111, with an extensive amount of features and extensions (such as Deforum and Dreambooth). Recently, a new user interface has been making a rise called invokeAI. This tool is primarily popular because of its unified canvas where it combines outpainting, inpainting, text-to-image and image-to-image seamlessly. Unfortunaltly, the interface does not currently support model fine tuning.
Artist that do not want to leave their familiar software can also enjoy the boom of plugins that were created from Stable Diffusion, such as Unreal Diffusion, Stable Diffusion for Photoshop or AI Render in Blender.
It’s not over yet
And the journey isn't over yet! Following the succes of the recent text-to-image models, many big corporations are working on better version or brand new artistic models like text-to-video or text-to-3D.
- New text-to-image are still coming out. StabilityAI recently released their new v2.1 model which is incredible for realistic scenes. Its competitor, Midjourney, is also actively evolving and blew people away with their fantastic v4 model.
- Text-to-video is still a work in process. Meta and Google have showcases their models (Make-a-video, Phenaki and ImagenVideo), but have yet to opensource the code or release the model. Although these models seem very promising, it is visible that they have struggles of their own (with for example humanised hands).
- A text-to-3D model already exists in the open source community under the name of Dreamfusion, which can create low-quality 3D models that serve as a base for a 3D project. Recently, researchers at NVIDIA showcases a new model called magic3D with astonishing results! However, similarly to Meta and Google, the code or model weights or not yet open sourced.
In short, the field is clearly still evolving and new models keep coming out. It is therefore a waiting game until the next art revolution starts.
Conclusion
To conclude, AI art generators have certainly made waves among artists, both good and bad. They have created astonishing master pieces, but also gave rise to criticism. Many artists are worried that these AI models will steal their art, overtake their jobs and make them obsolete, which is well-founded as Stable Diffusion is still improving to avoid copyright infringements. Altogether, legislation around AI generated art is still in its infancy and should therefore certainly be tackled in the European AI act.
Nevertheless, AI generated art is here to stay and should therefore be made accessible as a tool for artists instead of an opponent. I am hopeful for what the future brings and I'm certainly wishing for the new year with even more AI art revolutions!
Happy holidays to you!