

By Dishani Sen, Eya Akrimi
In the roots academy session of March 2023, a group of Data & Cloud engineers and ML engineers collaborated together to deliver a cloud-native framework for healthcare data analysis, designed with privacy and security at its core; federated learning framework for healthcare.
In this blog, we introduce the problem, the goals of the project as well as the architecture proposed as the solution. The solution consists of a fully operational, federated learning framework for healthcare data analysis.
Introduction of the Problem
The healthcare industry is undergoing a major transformation thanks to the power of big data and artificial intelligence (AI). With the advent of cloud computing, it is now possible to process and analyse vast amounts of medical data to deliver personalised, patient-centric care. However, there are still significant challenges that must be overcome to fully realise the potential of new technologies.
One of the most pressing issues is how to protect patient privacy while still making use of their data. Healthcare data is incredibly sensitive, and it is critical that patient privacy is maintained at all times. Secondly, another obstacle is that, for some diseases, hospitals have a limited amount of cases (low caseload), making it difficult for data teams to build effective models. While cloud computing has facilitated the processing and analysis of massive volumes of data, hospitals continue to face data availability challenges. This can make training accurate models that can be used to make data-driven decisions difficult. Additionally, the healthcare industry is also facing challenges related to data interoperability. Health systems often use different electronic health record (EHR) systems, making it difficult to share data across different systems. This can limit the ability of healthcare providers to leverage big data and AI to improve patient outcomes.
Our Solution
Enter federated learning, a cutting-edge approach to machine learning that allows multiple parties to collaborate on a model without sharing sensitive data. Federated learning enables healthcare professionals to leverage the power of AI and big data while preserving patient privacy, making it a key enabler of personalised healthcare and precision medicine. At the heart of this innovation is a cloud-native framework designed specifically for healthcare. This framework enables healthcare professionals to build and deploy federated learning models quickly and easily, without the need for specialised expertise in machine learning or data science.
With this framework, healthcare professionals can estimate treatment impacts on clinical outcomes without ever exposing sensitive patient data. This is a game-changer for the industry, as it enables data-driven decision-making at scale while also ensuring that patient privacy is protected.
Before we jump into describing in detail the framework for federated learning which we propose, here is a quick refresher on what exactly is federated learning and who can reap benefits out of it.
Federated Learning : A Quick Introduction
Federated learning is a distributed machine learning technique that allows multiple devices to collaboratively learn a shared model while keeping their data locally. Federated learning has a wide range of applications in different industries, all with the common goal of allowing multiple parties to train a model on their data without sharing it. This approach has the potential to revolutionise machine learning and data analysis while maintaining data privacy and security. Some applications of federated learning include:
- Healthcare: Federated learning can be used to train machine learning models for medical diagnosis and treatment while ensuring the privacy of patient data across multiple hospitals.
- Financial services: Banks and financial institutions can use federated learning to analyse large amounts of data while maintaining the privacy of customer information.
- Smart home devices: Federated learning can be used to train models on user behaviour to personalise the behaviour of smart home devices.
- Traffic management: We can implement federated learning to train models for traffic prediction, which can be used to optimise traffic flow and reduce congestion.
- Industrial automation: Federated learning can be used to train models on data from multiple factories to improve efficiency and reduce waste.
- Online advertising: Federated learning could potentially personalise online advertisements based on user behaviour while preserving user privacy.
- Agriculture: Federated learning can be used to train models on agricultural data to optimise crop yields and reduce water usage.
Overall, federated learning has the potential to revolutionise the way machine learning models are trained, especially in industries where data privacy is critical.
Goal of this Project
Our goal is to build a fully operational, batteries-included federated learning, cloud-native framework designed specifically to enable easy deployment of the setup. This framework will enable engineers to leverage the power of AI and data across tenants while preserving privacy and security.
The core of our solution is a federated learning approach, which allows multiple parties to collaborate on a model without sharing sensitive data. This approach ensures that privacy is protected at all times, while still allowing business stakeholders to make data-driven decisions and personalised recommendations.
The cloud-native framework proposed is designed to be easy to use and deploy, even for those without specialised expertise in data science or machine learning. At the same time, our solution delivers reproducibility and robustness at scale. By streamlining deployment and governance, we are lowering down the barrier of adoption of federated learning.
By leveraging innovative MLOps and federation strategies, we can ensure that our clients can scale their data analysis while maintaining the highest standards of data privacy and security and best practices.
Use Case
We demonstrate the cloud based framework on a concrete case of building a coronary heart disease prognostication model. There are three remote hospitals and one research centre with real-world dataset. The three hospitals each have small sample sizes, with a total data points less than 250, whereas for each client (i.e. the hospitals), the sample size is 30 < n < 100.
The heart disease prognostication model will be based on a federated learning algorithm that takes into account a wide range of factors, including age, sex, smoking status, cholesterol levels, and blood pressure. As the data cannot leave the hospital premises, so the best solution is to use federated learning to train the model. By analysing this data, we can identify patients who are at high risk for developing heart disease and provide targeted interventions to prevent its onset.
Our approach for implementing federated learning in healthcare is through the use of the NV Flare algorithm. The NV Flare algorithm is well-suited for federated learning in healthcare because it is able to handle large, complex data sets that are distributed across multiple locations while also maintaining patient privacy. This makes it an ideal choice for healthcare applications that involve sensitive patient information.
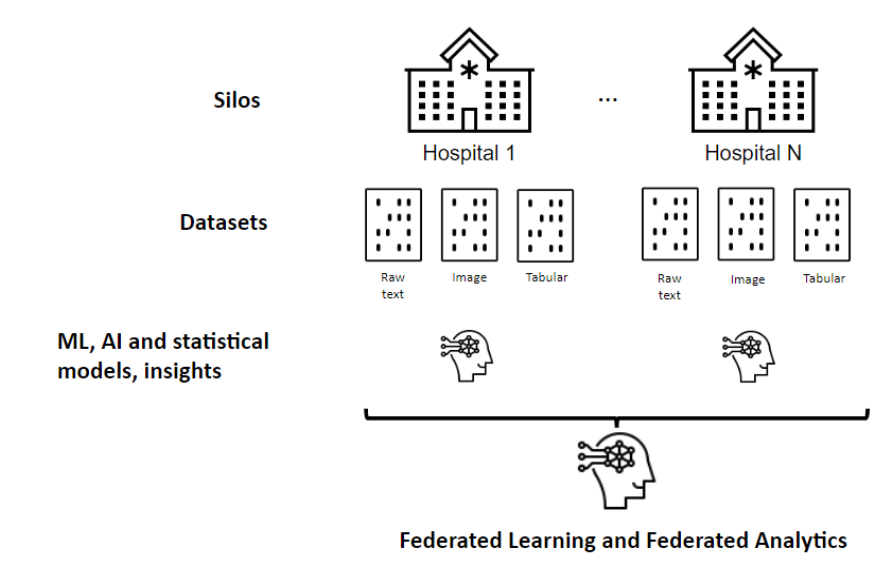
The Architecture as the Solution
The Federated Learning architecture ideally consists of the following:

The main idea of the architecture is to enable the hospitals to train their models locally and finally aggregate them and create a central model to better facilitate the collaboration between hospitals and the research centre and derive insights from a lot more data thanks for collaboration.
The global architecture is divided into four main parts, consisting of one research centre and three hospitals (tenant). The whole architecture is implemented on Azure Cloud. Each tenant will have the same privacy friendly architecture in its own Azure Cloud subscriptions. The architecture is written in terraform, which allows us to scale the project to more tenants very easily. Data contains patient demographics, medical history, and lifestyle factors that could contribute to the development of heart disease. To ensure the privacy and security of patient data, a fourth subscription will act as the central node (research center), responsible for aggregating the insights (models and data analysis) and exposing the final prognostication model. This federated learning approach allows us to train the model on data from multiple nodes without ever data leaving the hospital's premises and thus exposing sensitive patient information.
Challenges
When building an architecture for federated learning with three hospitals as client nodes and one research centre as the central node, there are some unique challenges to consider. Building a full architecture and implementing the infrastructure and MLOps comes with its own set of trade-offs, especially when it comes to implementing MLOps best practices in a federated setup. In this section, we will explore some of the challenges encountered while implementing the federated learning infrastructure :
- Immature Technology : As federated learning is a new topic, the technology behind it is still in the experimental phase, and there is not much information about how to set it up. This means that there is a lack of standardisation and best practices for building and deploying federated learning infrastructure. Therefore, it is important to keep an eye on the latest developments in the field and be prepared to adapt and change the infrastructure as needed. Solution comes in the form of staying up-to-date with the latest developments in the field of federated learning and making use of community resources such as forums, blogs, and GitHub repositories. At Dataroots, we have experimented with different tools and frameworks to find the best solution for the specific use case which has been presented here.
- Data Privacy : Data privacy is a critical concern when it comes to federated learning. In a federated learning setup, data is kept on the client nodes, and only the model updates are shared with the central node. In this architecture, the client nodes are hospitals, which means that they will be dealing with sensitive patient data. It is important to ensure that data is protected at all times during the training process, and that data is not exposed to unauthorised parties. However, it is still important to track the results and models while ensuring that the data is kept private. This can be challenging, especially when it comes to explaining the results to stakeholders. As a solution, we have implemented strict access controls and data protection measures to ensure that only authorised personnel can access the data. We have also created dashboards that show only aggregated data to provide stakeholders with an overview of the results without compromising data privacy.
- Network Security: One of the major challenges is that hospitals have to open up a part of their infrastructure to communicate with the research center. This can be a potential vulnerability, as it allows external parties to access some of the hospital's infrastructure. To overcome this challenge, federated learning systems use a pull or push mechanism. In a pull mechanism, the research center requests data from the hospital's infrastructure, whereas in a push mechanism, the hospital sends data to the research center. Both mechanisms have their advantages and disadvantages. A pull mechanism is more secure, as it limits the amount of data that can be accessed by the research center. However, it requires the research center to have access to the hospital's infrastructure, which can be challenging from a security perspective. A push mechanism is more straightforward to implement, but it requires the hospital to trust the research center with its data. Furthermore, to ensure the security of communication between the parties, it is important to use Virtual Private Network (VNET). The VNet allows hospitals to create a private network that is only accessible by authorised parties. This ensures that only authorised parties can access the hospital's infrastructure, and reduces the risk of data breaches. Each VNent for the different hospitals are created with different virtual network address space to ensure no over-lapping during the VNet Peering.
- Reproducibility & experimentation: Reproducibility is essential in any machine learning project, and it becomes even more challenging in a federated learning setup. This is because federated learning involves multiple parties, and each party may have their own set of configurations and parameters that they use to train their models and experiment. Tracking all these config files can be difficult and time-consuming. For this challenge, we have used a version control system to track changes to the code and configurations. We used MLflow to track experiments, metrics, and model artifacts across multiple runs and created a standard set of configurations and parameters that all parties can use to ensure reproducibility and experimentation.
- Trust trade off : While federated learning offers significant benefits in terms of scalability and performance, it also involves a trust trade-off between privacy and automation. In the use case described, the first option is having a super user with access to all hospitals' data would greatly enhance scalability, as it would enable automated data sharing and model training across all hospitals. However, this approach would require trusting one party with access to sensitive medical data, which is unlikely to satisfy current legislation around medical data privacy. It also poses the risk of data breaches or unauthorised access to confidential information. Similarly if one party would spin all the federated learning framework, this would allow great automation and scalability and yet would probably not meet privacy and security regulations. On the other hand, the second option is each hospital deploy their infrastructure which reduces the risk of data breaches and ensures compliance with data privacy regulations. However, this approach requires each hospital to independently set up and maintain their infrastructure, which can be time-consuming and resource-intensive. This is where our solution comes in handy as we provide the documentation, templating, and easy examples. When each hospital creates its infrastructure, it would be easier in terms of the global framework if the infrastructure for every node is similarly designed. This ensures that there's no differences in infrastructure quality and the availability of data, and no negative impact on the accuracy of the model.
- Model aggregation: The models trained on the client nodes need to be aggregated to create a global model. However, this model aggregation process can be challenging, especially when dealing with models that have different architectures, parameters, and hyper-parameters. Therefore, it is always a good idea to ensure that there is a similar infrastructure in place for each client nodes and that the diverse parameters can be logged in the MLOps tooling to ensure documentation and replication.
- Communication overhead: In this architecture, models are trained on data that is distributed across multiple client nodes. This means that there is a significant amount of communication overhead involved in exchanging data between the different client nodes and the central node. This communication overhead can impact the performance of the training process and make it more difficult to scale up to larger data sets yet ensuring results in a timely fashion. We might require to upscale the infrastructure on each tenant. For our POC, a single VM was sufficient to obtain timely results.
- Agile collaboration between teams: In a real-world scenario of implementing federated learning, there can be more than one team in charge of setting up the infrastructure and MLOps framework separately. It is highly recommended to collaborate not just within the teams, but between the different teams and running appropriate tests early on.
By addressing these challenges head-on, organisations can take advantage of the many benefits of federated learning, including improved model accuracy, better data privacy and security, and more efficient use of computing resources.
Conclusion
In conclusion, our federated learning, cloud-native framework is designed with privacy and security at its core, empowering healthcare professionals to make data-driven decisions based on a patient's unique profile. The primary goal of this framework is to operationalise using federated learning for healthcare by following the best practices. If you liked what you read and would like to dive deeper, then stay tuned. There is more to come in terms of information about the MLOps framework and the infrastructure framework for deploying the cloud-native solution. We aim to provide a comprehensive understanding of the entire framework, including its technical aspects and implementation. With the upcoming blogposts on MLOps framework, we want to showcase the operational aspects of the cloud-native solution, including how it works, how data is processed and analysed, and how the machine learning models are trained and updated over time. Additionally, the upcoming blogpost on the infrastructure framework will provide insights into how the cloud-native solution can be deployed and scaled across different hospitals and healthcare systems, making it easier for healthcare professionals to use and access the solution.
You might also like


