

By Tim Leers
The problem.
Artificial intelligence (AI) is driving the rapid transformation of industries. However, the exponential rate of that transformation is difficult to manage for legislators. Moreover, there is no industry standard to ensure AI is safe and beneficial. New applications are introduced at breakneck speed, oftentimes without sufficient consideration of their potential societal impact.
AI promises to enable the scaleable automation of almost any decision-making system. In doing so, we amplify biases that are inherent in any system: As human decision-making gets replaced piecemeal or even wholesale by AI-driven systems, the biases that are implemented in these systems are propagated efficiently and widely, through the power of the internet and the cloud.
...intelligent machines reveal their nature of ‘magnifying glasses’ in the automation of existing inequalities...
(there is) mounting attention for technological narratives ... technology is recognized as a social practice within a specific institutional context. Not only do narratives reflect organizing visions for society, but they also are a tangible sign of the traditional lines of social, economic, and political inequalities
- Sartori & Theodoru (2022)
The example.
Anytime AI is trained with some remotely human objective in mind, such as face detection, there is near-certainty that implicit biases will slip into the AI solution, one way or another.
We evaluate 3 commercial gender classification systems using our dataset and show that darker-skinned females are the most misclassified group (with error rates of up to 34.7%). The maximum error rate for lighter-skinned males is 0.8%.
- Buolamwini & Gebru (2018)
Some part of that may be due to bias in data collection and representation: If a part of the human face distribution is not well-represented, that may lead to issues in detecting faces. If you train an AI to detect only male faces by training it on a dataset of male faces, and subsequently try to detect female faces, you wouldn't expect the AI to do well - so why would you expect the same for other scenarios where the dataset is not representative of the real world context?

However, it goes beyond the data. Even if the data is representative, the underlying algorithm used to detect faces will almost always be biased in one way or another: Models implicitly use biases, i.e. assumptions, about the data to perform inference. Inference is about deriving useful conclusions, or arriving at decisions, in the absence of complete information. It becomes a massive problem when those assumptions encode technological narratives that remain unchecked.
Let's take a hypothetical example (made a bit more extreme for the sake of clarity) suppose that we have 1 to 100 ratio of female to male faces in our dataset of 10 000 faces, which would look a bit like this if we take a subset of 100 faces:

If we optimize face detection for accuracy, with such an imbalanced dataset, that optimization will likely bias our model to perform better at detecting male faces, even if the female faces give a sufficiently accurate representation of the real distribution. After all, if 9900 male faces are correctly identified, but 100 female faces are incorrectly identified, we still attain the much sought after and often mythical 99% model accuracy. Without sufficient consideration to such issues, the practitioner hangs their hat, as the model is ready for supposed value creation. A subset of end-users (i.e., all women in this hypothetical scenario) is unfortunately adversely impacted by this method in that their face is not detected.
The consequences.
Because of the lack of representation in data, or lack of fairness in how we build and optimize models, it is often the case that disadvantaged peoples are affected by insufficiently representative or negatively biased models. In the case of failing face detection for phone authentication, that may be just frustrating, and just another area in which minority groups are disadvantaged. (*just is very much used sarcastically here - it is very clearly another way, of already too many ways, in which disadvantaged people are being disadvantaged even more).
As AI solutions are (mis-)used for applications they were not developed for, errors can become undeniably severe and insidious:
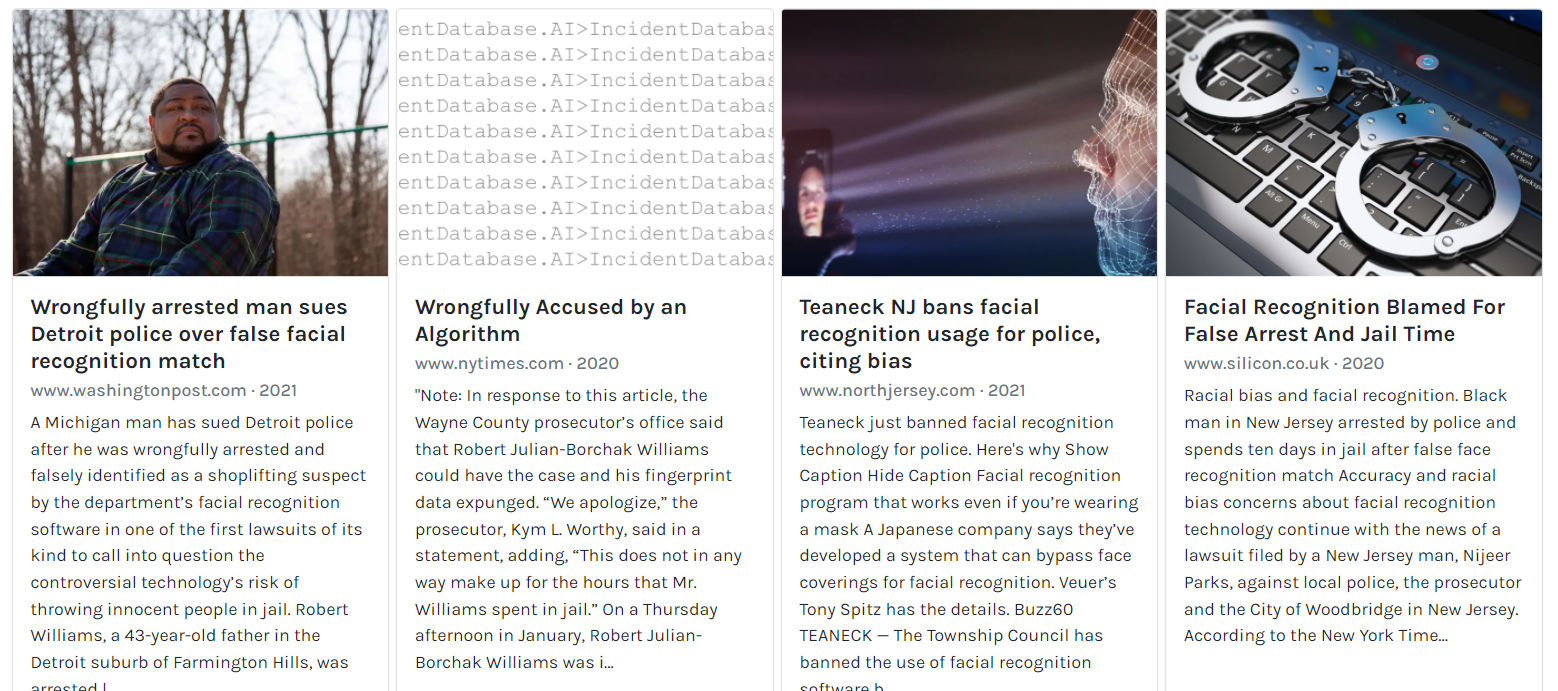
It is impossible to give a full account of the many ways that AI is disadvantaging peoples, just like it is difficult to do the same for its advantages. For a more representative lived experience and fascinating exposition of how AI (un)fairness has serious, real-life impact, we recommend listening to Gebru's talk at NeurIPS 2021.
Our role as industry practitioners
The first question we need to ask, before we think about fairness, equations or anything else:
What are we all contributing to? What are we building? Is it the utopia that we want to build?
... If you are truly interested in justice, fairness and whatever else, you need to start with that first question.
- Timnit Gebru on "Machine learning in practice: Who is benefiting? Who is being harmed?"
Technological solutions are not built in a vacuum. Whenever we build an AI solution, we need to take into account the sociotechnical context - how will the AI solution practically contribute, and who will it affect? Applying those questions to the example of gender classification is left to the curious reader, but can only lead to question marks as to the motivation of researchers or industry practitioners developing such a system. Unfortunately, this step is not part of contemporary AI project lifecycles as it does not intuitively improve business value creation. Pressured under sprints & project goals, to convince stakeholders, we may never consider the impact on the end-user.
Let's say we add steps to consider harmful impact to our project lifecycle, what now? There's no 3-step plan nor 5-bullet point checklist to avoid bias & inequities caused by AI.
AI is like any other technology, a tool. A more dangerous tool, because of its potential, but in the end, it is human behavior that will need to change to fundamentally improve fairness in practice.
What we can do.
There's a two-pronged approach to improving fairness that any company can ultimately start working on today.
- Improving diversity & inclusivity. Representation matters. Open discussion about these challenges matter. Yes, it is important, and no, it's not a waste of time to consider these issues in an industry project. Diversity can lead to a broader representation and awareness of how technology can impact various groups of people in very different ways. By increasing the diversity of lived experience, the model's biases may be picked up on and discussed earlier. By ensuring an inclusive work environment, these topics are made discussable.
- Implementing ethical consulting and value-driven engineering. As companies progress up the AI maturity curve, aside from business value, the societal impact of any solution should be considered. Consultants should inform clients about potential biases, and how they can be mitigated. Some products should simply not be built: If the questions posed by Gebru only lead to ever more worrying answers, then the first step should not be to build an AI solution. Instead, we should take a step back and consider the goals of the organization and/or project, and whether AI is a fitting tool for that purpose.
So, how to make AI fair? As software eats the world, a common tendency is to throw technology & mathematical equations at a problem until it's "fixed". Yet, the takeaway from this post should be that there is no easy tool that fixes bias, but that bias is omnipresent in everything we do. Then, to influence data (science) projects, biases should be mapped and mitigated to the fullest extent possible, in part by considering the context and purpose for which we build our AI solutions. In some parts, detection of bias can be eased by technology (i.e., XAI), but in the end, it's up to organizational and human effort.
Unfortunately, until there is stricter enforcement, there is often little incentive for companies to implement an additional AI fairness step, as some companies will only see it as a detriment to value creation. Fortunately, at dataroots we see an increased trend to map and mitigate harmful biases, in part because of impending regulations and the potential liability associated with erroneous AI-driven decisions.
At dataroots, we are strongly engaged to diversity and inclusivity, and building a culture where ethical consulting and value-driven engineering are part and parcel of our way-of-working. Combining that with our continued focus on XAI-as-a-service, we aim to serve as a market leader in reducing harmful bias in AI.
Recommended listening
The material for this post was largely adapted from and inspired by Timnit Gebru & Emily Denton's talk at NeurIPS 2021. Recommended listening, especially if this topic is unfamiliar and new!