

By Murilo Cunha
If you ever took a look into Natural Language Processing (NLP) for the past years, you probably heard of transformers. But what are these things? How did they come to be? Why is it so good? How to use them?
A good place to start answering these questions is to look back at what was there before transformers, when we started using neural networks for NLP tasks.
Early days
One of the first uses of neural networks for NLP came with Recurrent Neural Networks (RNNs). The idea there is to mimic humans: scan words in a sentence one by one, passing words to a model one by one, in sequence, as well as the model outputs from the previous step.
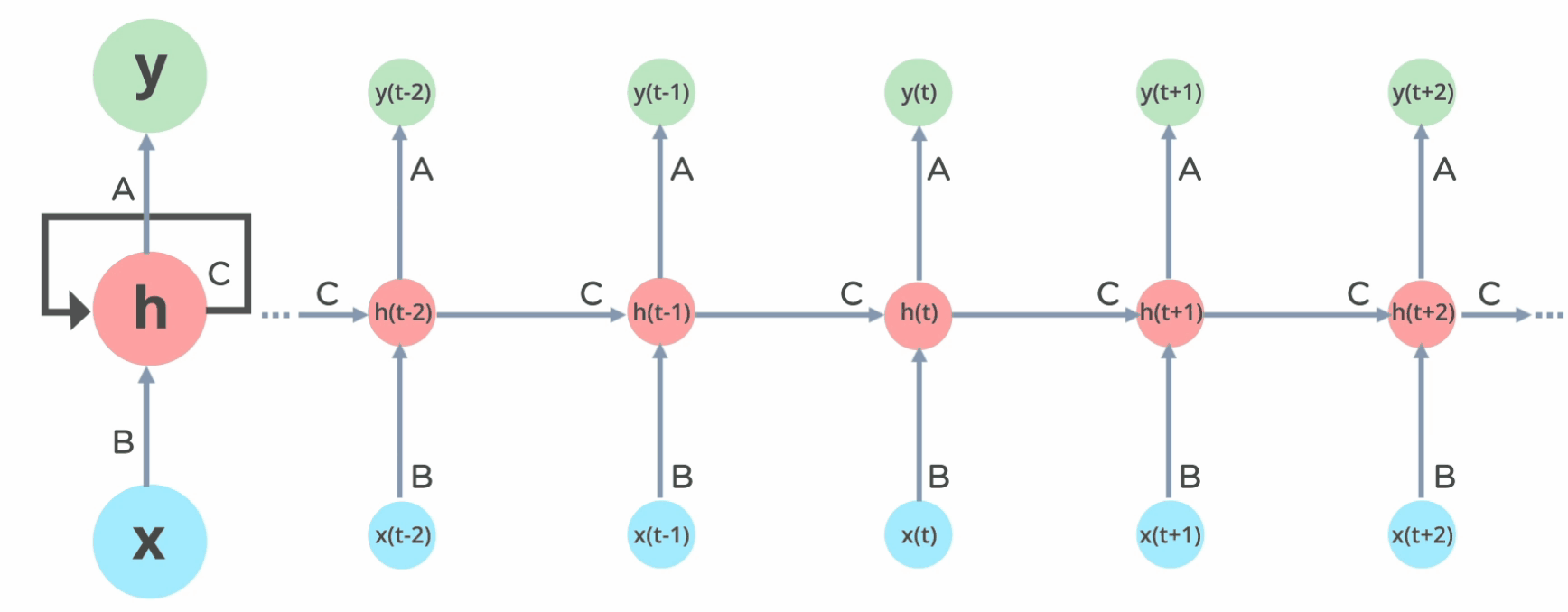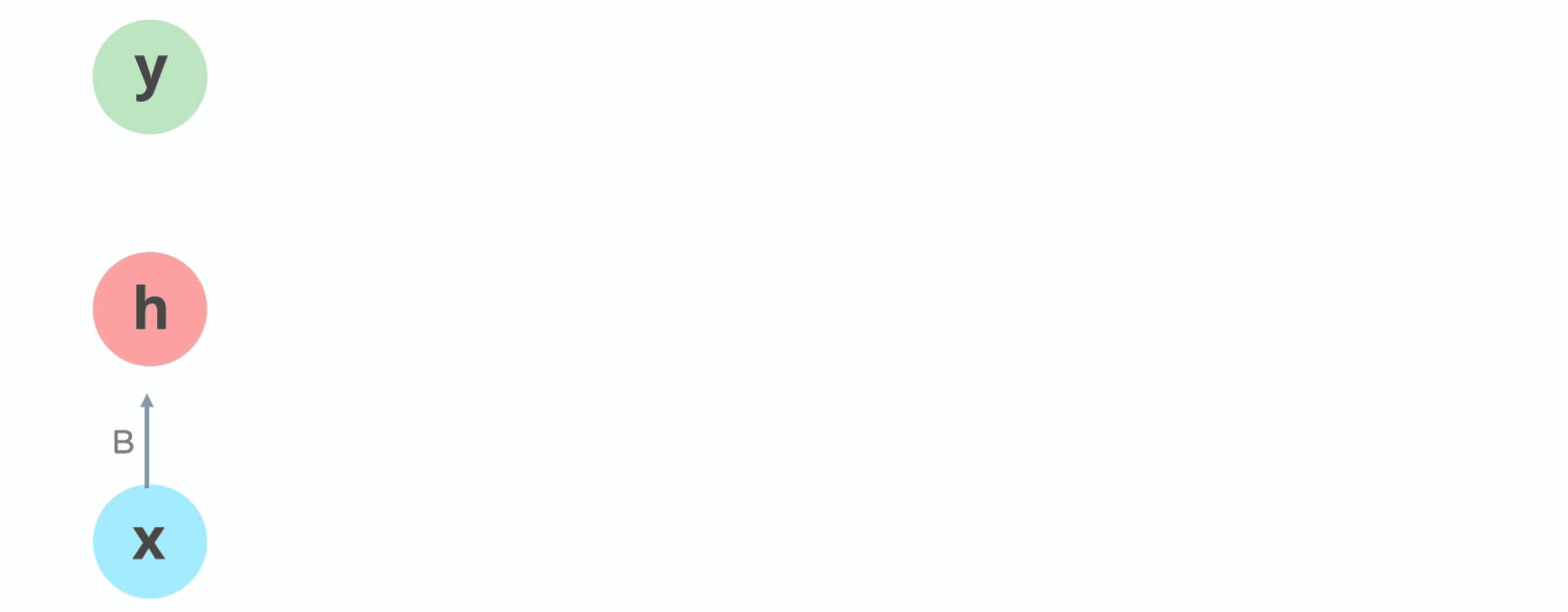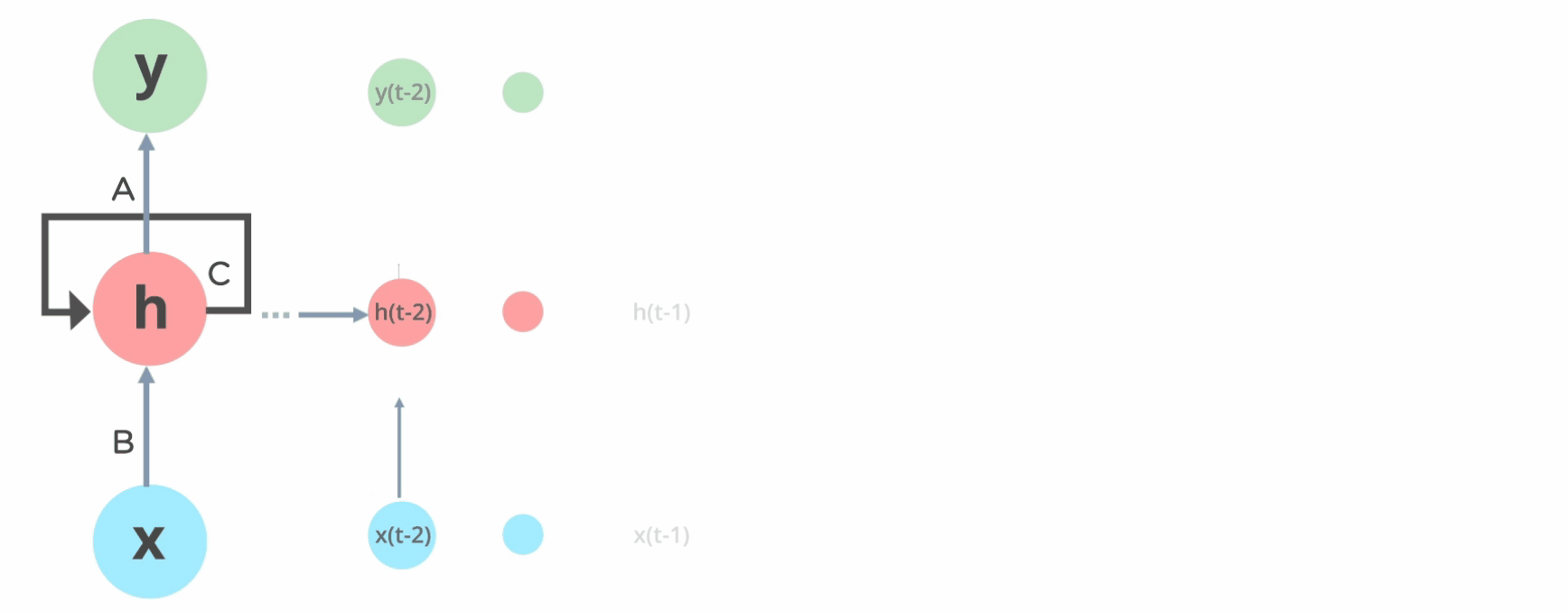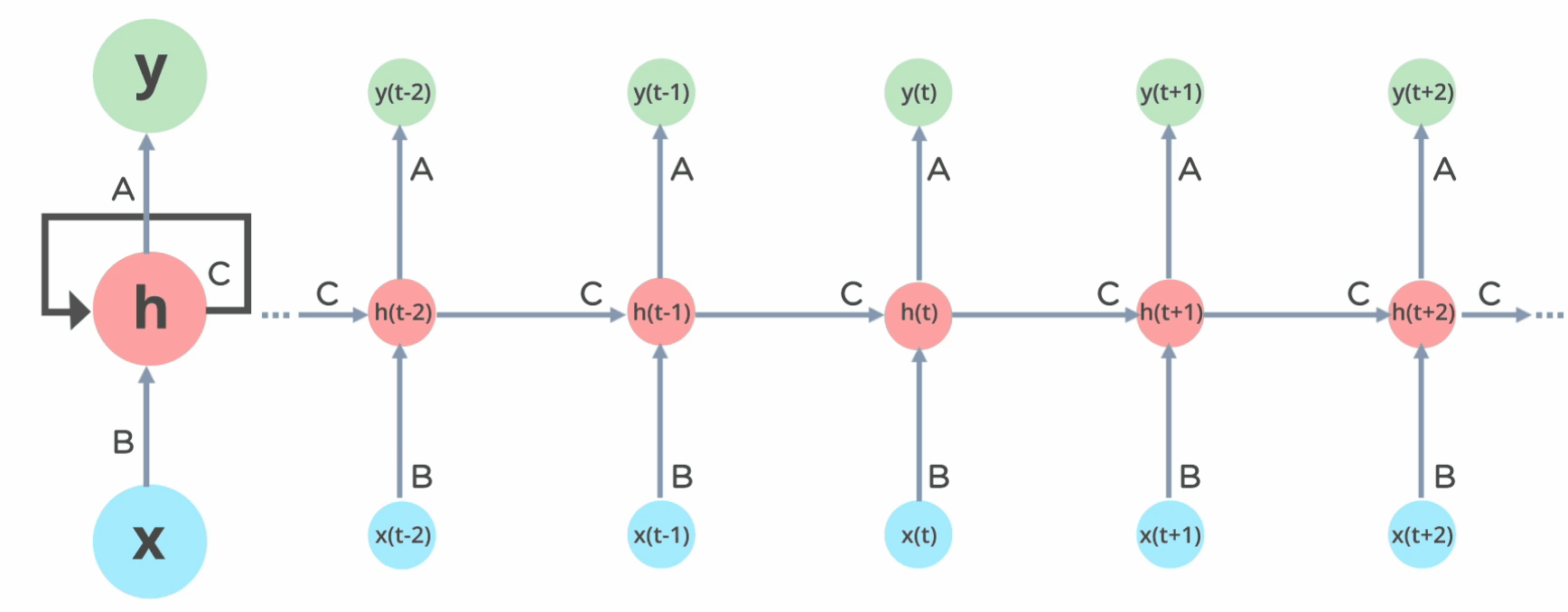
But there was a problem: neural networks learn with these things called gradients. These gradients tend to be small, especially towards the end of training. The gradients were also carried out from the end of the sentence to the beginning. So, for long sentences, the gradients would vanish, meaning that the model would not learn for the first few words.
Think of a room where people keep walking in: as the room gets more and more full, people by the door would still notice people getting in, while people in the back would not notice much difference. And the bigger the room, the less noticeable that difference would feel for the people in the back.
Remember, remember
To solve that problem, people came up with more complex neural network architectures. Now instead of having the traditional feed-forward network cells, we added things such as forget, input and output gates. These were named Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) cells. In other words, the LSTMs and GRUs are just RNNs that solve the vanishing gradient problem.
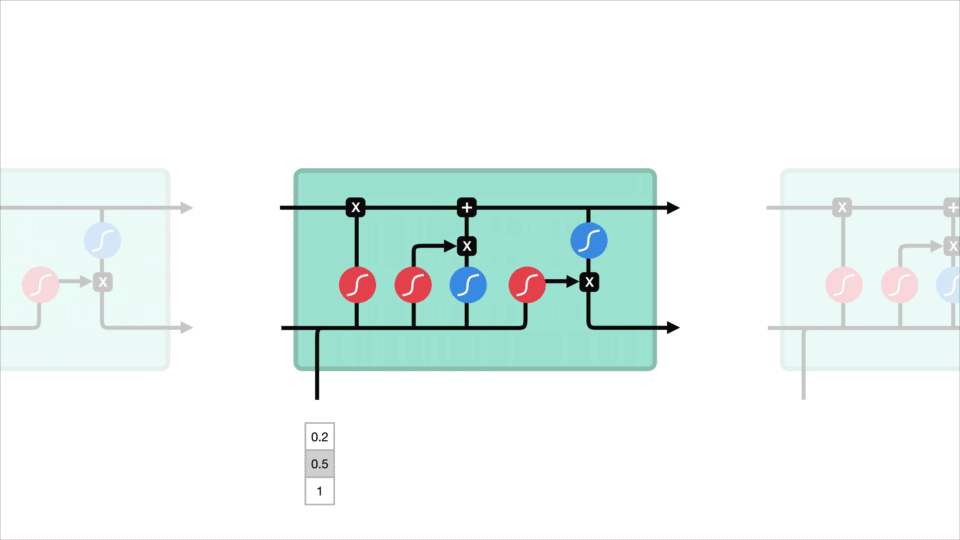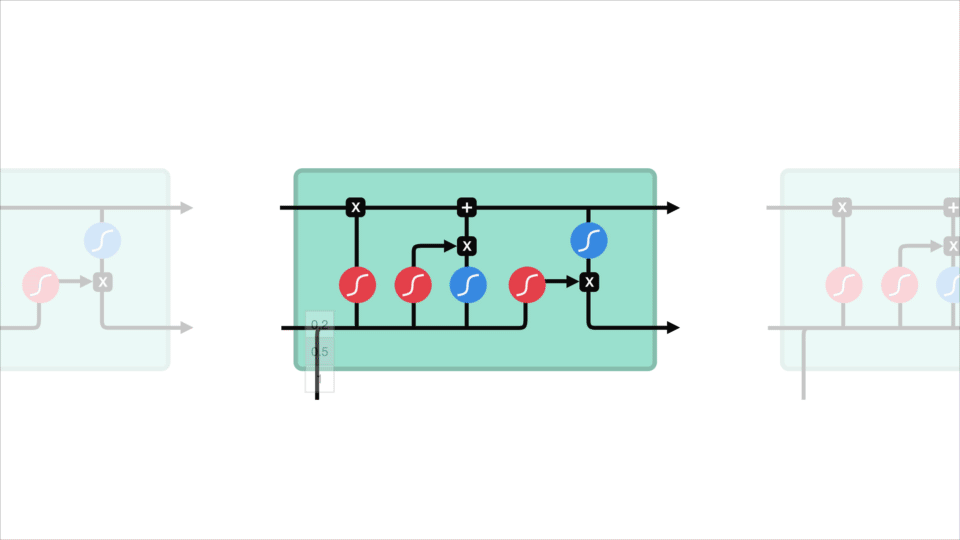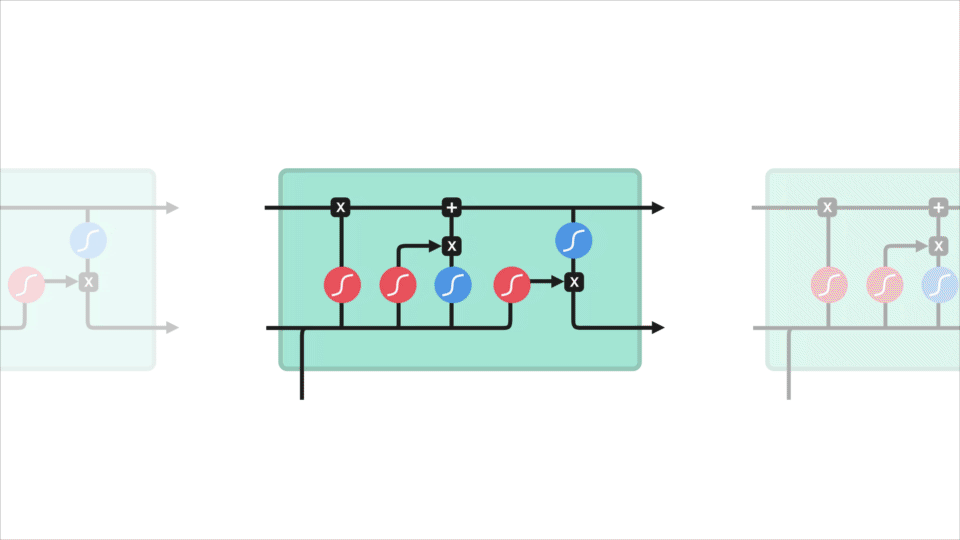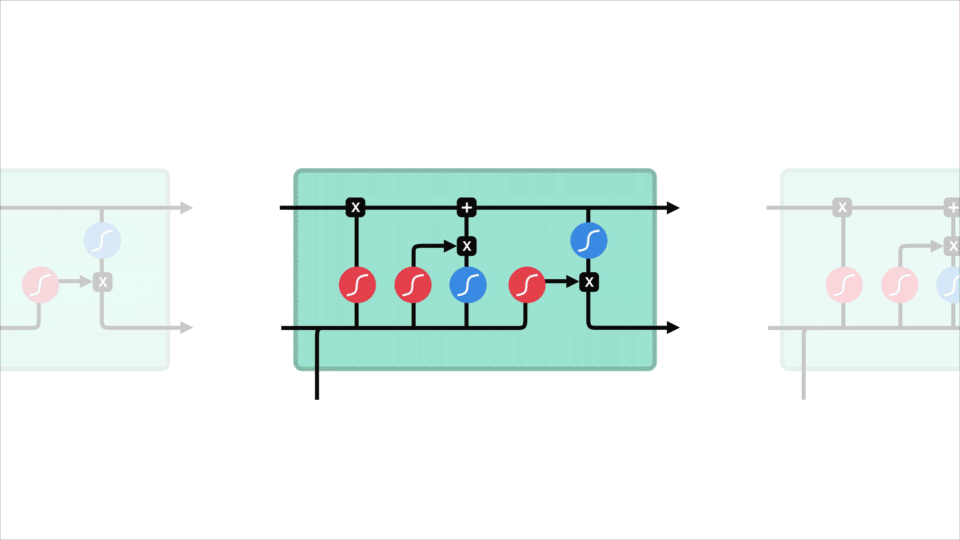
There was, however, still another issue: we scan the whole sentence and try to compress it to one vector, which was proven to be “too much to ask”.
Imagine you are trying to predict the next word on
“The chicken didn’t cross the street because it was too __”.
What was your guess? Was the chicken too tired? Was the road too wide? Either way we have to pay attention to the first words and carry these dependencies out before making our guesses. And, as you may have guessed, LSTMs and GRUs were still not good for catching these long-term dependencies.
Paying attention?
The idea now is to remember the intermediate representations for each word, and give different levels of attention to them (figuring out how relevant the word is for what we are trying to do). These were coined attention RNNs, and the amount of attention to be given to each word is also learned during the training process.
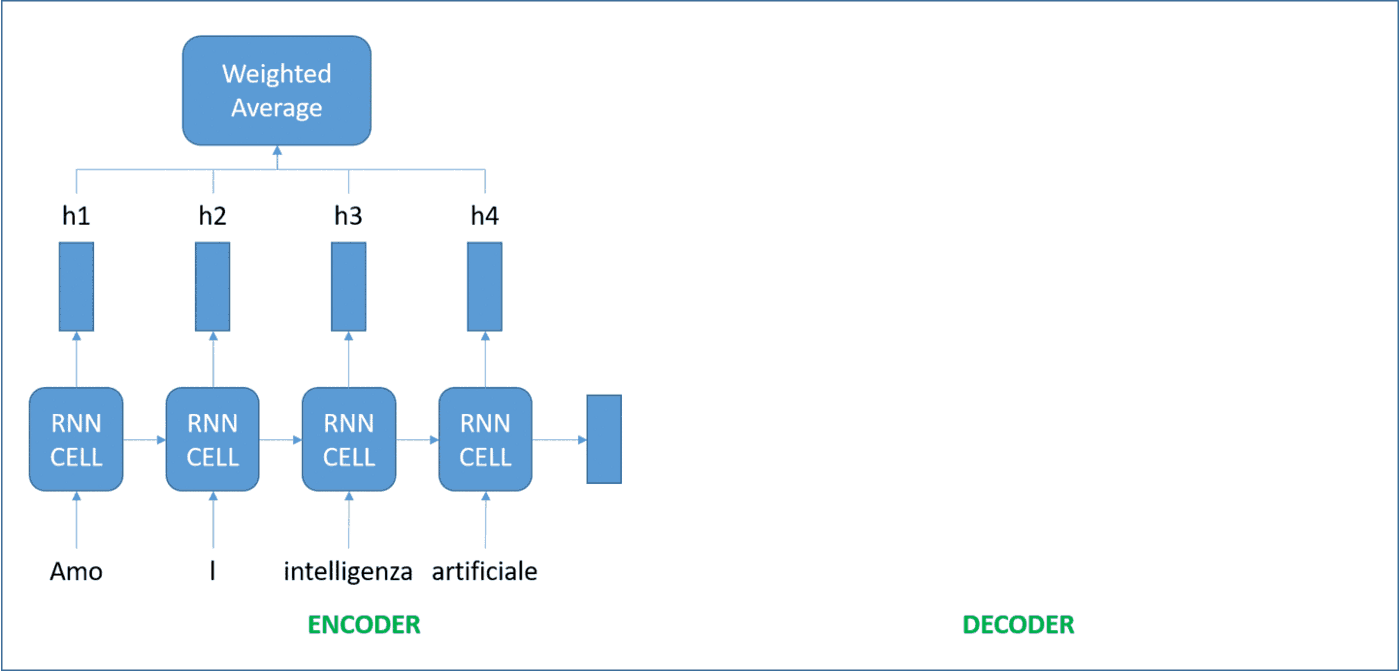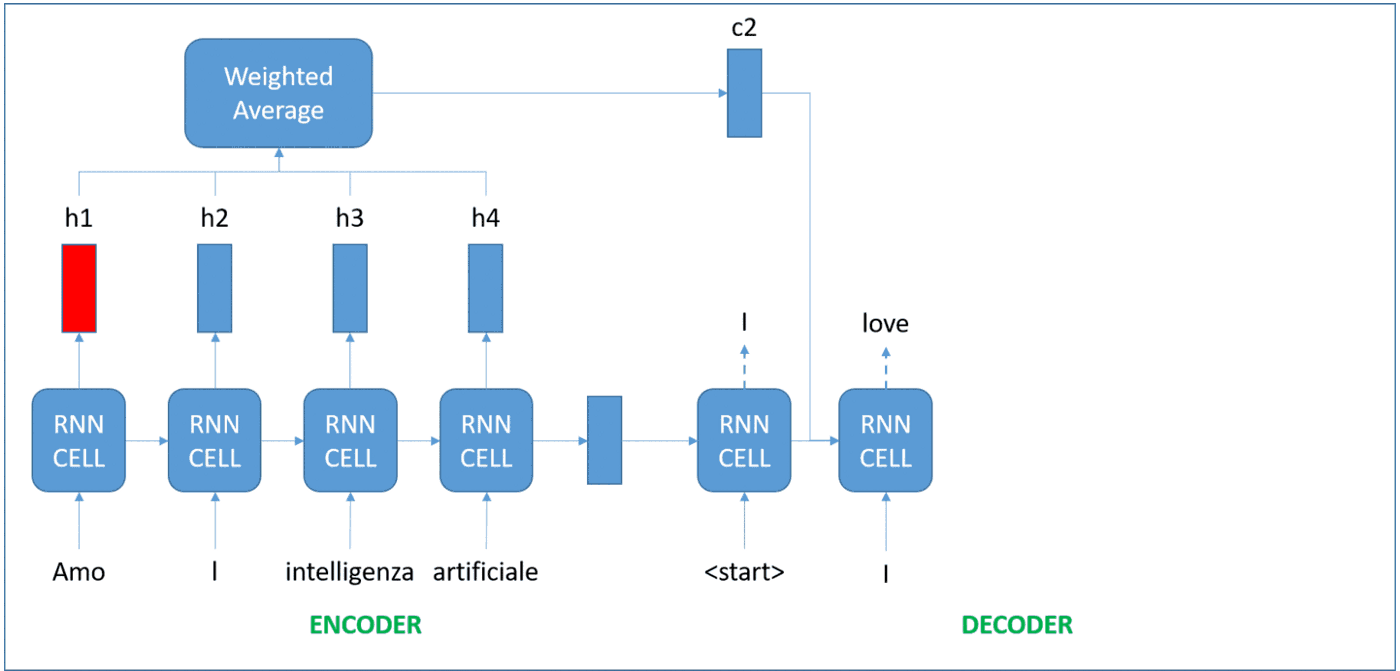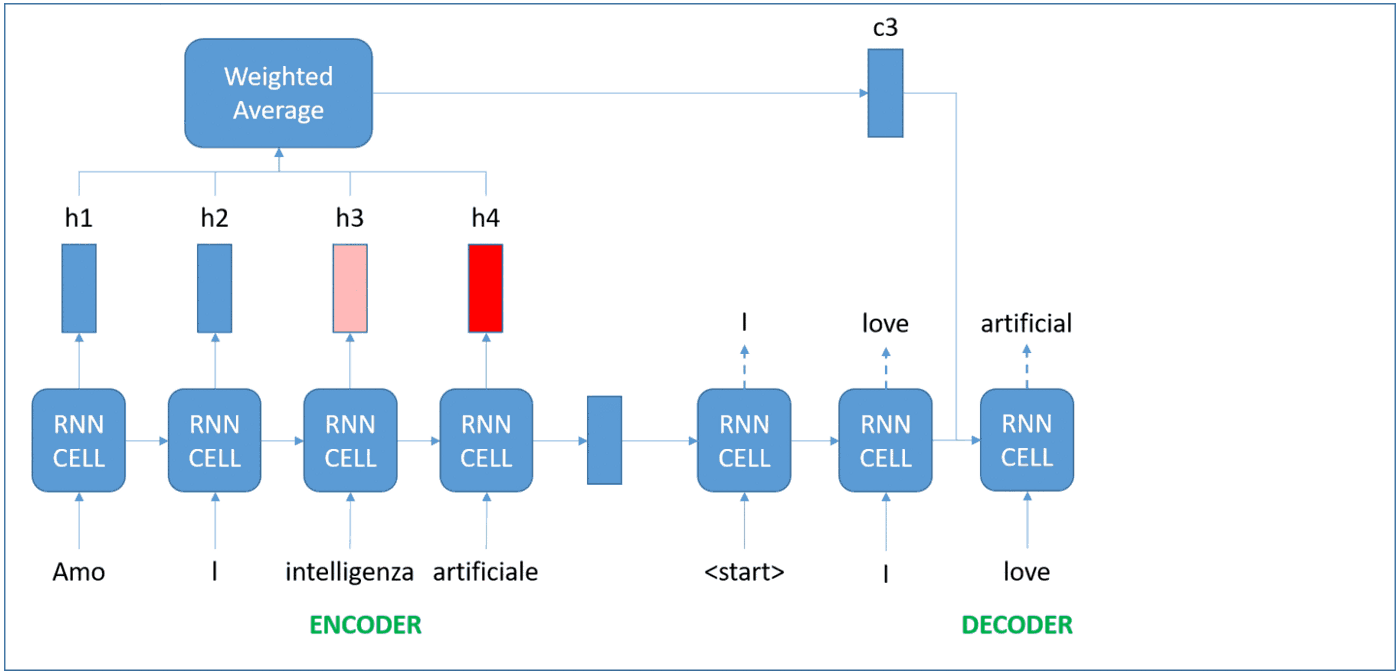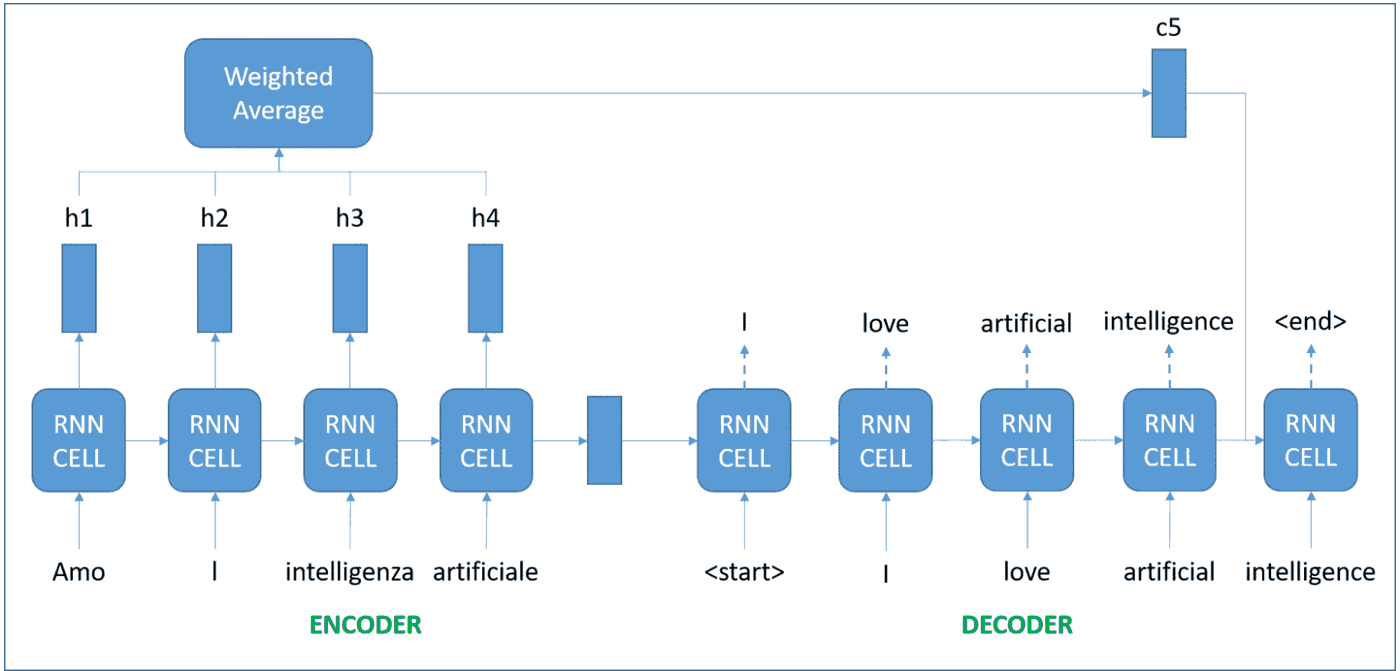
Transform it!
And all was good. Life was peaceful. And one day someone came along and thought, “why do we need this whole RNN business?”. And the paper named Attention Is All You Need was published. Basically it stated that the RNN part is not needed, and we can get better results with the attention part only. And that attention-only model is actually the transformer.

There are different types of attention. And because of that, there are different transformer blocks and consequently different types of transformers. With self-attention, for example, we can figure out what words refer to in a sentence. In the example of “the animal didn’t cross the street because it was too wide.”, what does the “it” means? Animal or road?
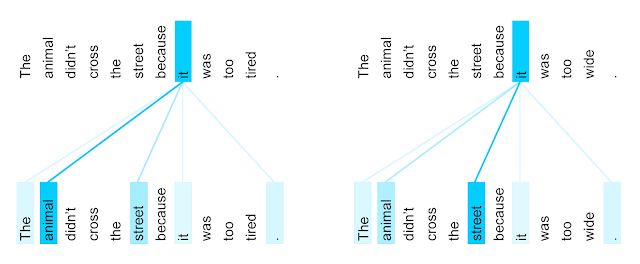
Cool, right? But this architecture alone does not give you good results. We also need some a lot of data. Where do we get it?
Transfer it!
Just as we can apply transfer learning to computer vision models (going from autoencoders to CNNs), we can do something very similar to transformers and NLP.
BERT is a transformer from Google. It wasn’t the first transformer, but there were a couple of things that made it very popular:
- It was trained on a lot of data (like over 300M words, from books and English Wikipedia). The data was unlabeled - they hid some words and made the objective to predict the masked words (like a “fill in the blank” question).
- The model was huge - 340M parameters.
- It did very well - “state-of-the-art for a whole bunch of NLP tasks” well, by just fine tuning for different use cases. It showed that we could “model language” with unlabeled data and then just fine tune with labeled data for other tasks.
Since then there are other popular transformers that came out, with slightly different training strategies and architectures. GPT-2 (3, ?), for example, predicts the next word in the sentence. But they are all huge, and all were pre-trained in a lot of data. So I guess the bottom line is just keep getting data and adding layers until your model is good enough.

Thankfully that doesn’t mean that you can only benefit from transformers if you’re Google and have GPUs lying around to train these huge models.
Grab it
The most popular package for transformers is HuggingFace🤗. It has all sorts of useful things built on top of popular neural networks frameworks (PyTorch and Tensorflow). What’s more, they list out all pretrained models, from different languages and different subject domains. Chances are that instead of training from scratch you could find a pretrained model there that would kickstart your transformer model.
Want more?
If I sparked your interest, then here are some great resources to go a bit further:
- 3Blue1Brown’s video - great explanation for gradients and backpropagation in neural networks
- Jay Alammar’s blog - great for all transformer/NLP related things, including explanations, interactive libraries and videos
- Google’s notebook - nice interactive visualization of the attention mechanism
- Demos on HuggingFace🤗 - they also offer an UI for taking models for a quick spin!