

By Baudouin Martelée
Introduction
Current approaches to modeling the world are predominantly limited to short sequences of language or images and clips. Consequently, models often lack understanding of aspects of the world that are challenging to represent in brief texts or clips and struggle to process complex long-form language and visual tasks.
Long videos offer a rich context that short clips cannot fully capture, illustrating the interconnectedness of scenes, the progression of events, and the cause-and-effect relationships within the temporal dimension of the video. By simultaneously modeling both long videos and books, the model can acquire an understanding of the multimodal world and lengthy sequences of texts and videos. This advancement leads to more sophisticated AI systems with a multimodal understanding, capable of assisting humans across a broader spectrum of tasks.
Exposure to diverse long language and video scenarios enhances the AI systems' ability to generalize across various real-world situations. To address the deficiency of long-form chat datasets, a model-generated question-answering (QA) approach was developed, utilizing a short-context model to generate a QA dataset from books.
This development was identified as critical for improving chat abilities over long sequences. Consequently, this work lays the groundwork for training on extensive datasets comprising long video and language samples, thereby facilitating the future development of AI systems equipped with a comprehensive understanding of human knowledge, the multimodal world, and enhanced capabilities.
Models selection
The focus is on LWM (Large World Model) and LWM-Text, a set of long-context language models learned by training on progressively increasing sequence length data with RingAttention and modifying positional encoding parameters to account for longer sequence lengths. LWM-Text is a model capable of processing long text documents while LWM is made for long video sequence. Ring attention is a novel method that modifies the self-attention mechanism in Transformer models to efficiently handle extremely long sequences of data. For more details : Ring attention
Model training
The image below illustrates the multimodal training of a LWM. This post will take into account two stages about evaluating Chat for both LWM . The figure below describes a visual overview of both stages.
Stage 1 : LWM-Text focuses on expanding context size using the Books3 dataset, with context size growing from 32K to 1M.
Stage 2 : LWM, Vision-Language Training, focuses on training on visual and video contents of varying lengths. The pie chart details the allocation of 495B tokens across images, short and long videos, and 33B tokens of text data. The lower panel shows interactive capabilities in understanding and responding to queries about the complex multimodal world.

Stage I : LLM context extension
Learning long-range dependencies over sequences of millions of tokens requires two conditions :
- Scalable training on such long documents
- Extend stably the context of our base language.
The implementation enables training on long documents containing millions of tokens. However, it remains costly due to the quadratic computational complexity of attention. An approach is adopted where the model is trained on progressively longer sequence lengths, starting from 32K tokens and ending at 1M tokens in increasing powers of two. This method allows the model to save compute by first learning shorter-range dependencies before moving onto longer sequences.
Training Steps
The model initialization is based on LLaMA-2 7B, and the effective context length of the model is progressively increased in 5 stages - 32K, 128K, 256K, 512K, and 1M. Training is conducted on various filtered versions of the Books3 dataset, a well-known AI dataset. Each subsequent run is initialized from the run of the preceding sequence length.
Chat Fine-tuning for Long-Context Learning
A simple QA dataset is constructed for learning long-context chat abilities. For chat fine-tuning, each model is trained on a mixture of UltraChat and a custom QA dataset. UltraChat is an open-source, large-scale, and multi-round dialogue dataset comprising three sectors:
- Questions about the World: This sector contains dialogue data derived from various inquiries related to concepts, entities, and objects from the real world. Topics covered are extensive, including areas such as technology, art, and entrepreneurship.
- Writing and Creation: Dialogue data in this sector is driven by demands for writing/creation from scratch, encompassing tasks an AI assistant may aid in the creative process, such as email composition, crafting narratives, and plays.
- Assistance on Existent Materials: Dialogue data in this sector is generated based on existing materials, including rewriting, continuation, summarization, and inference, covering a diverse range of topics.
Pre-packing the UltraChat data to the training sequence length is crucial, keeping it separate from examples with our Q&A data. UltraChat data generally has a much higher proportion of loss tokens, whereas our Q&A data has a much lower percentage of loss tokens per sequence (< 1%) due to the absence of loss on the long documents within the given context. It's noteworthy that progressive training is not performed for each of the chat models; instead, they are initialized from their respective pre-trained models at the same context length.
Single-Needle Retrieval
To evaluate the LWM-text model, let’s introduce the “Needle in a Haystack” test. The test is designed to evaluate the performance of LLM RAG systems across different sizes of context. It works by embedding specific, targeted information (the “needle”) within a larger, more complex body of text (the “haystack”). The goal is to assess an LLM’s ability to identify and utilize this specific piece of information amidst a vast amount of data.
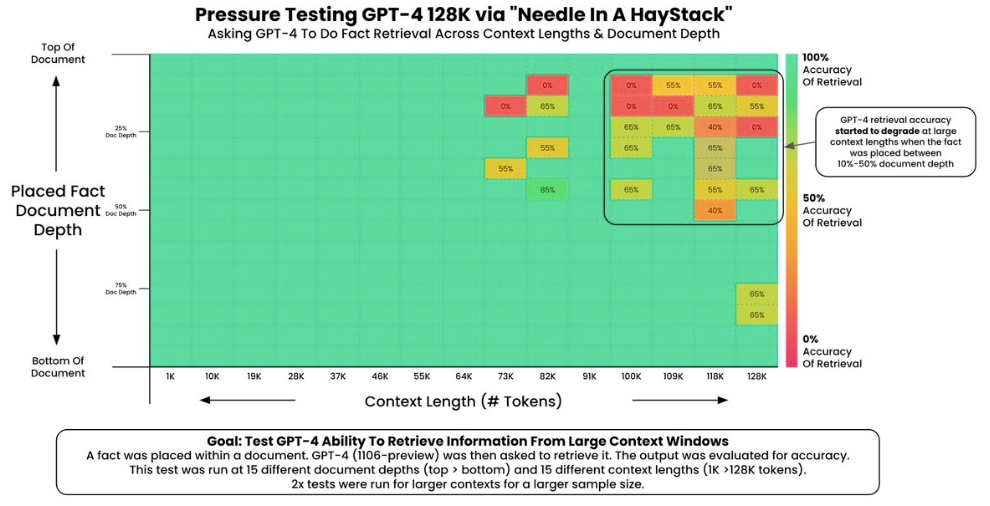
Here is an example for GPT4-4 128K where it shows limitations at large context lengths when the fact was placed between 10% and 50% of document depth.
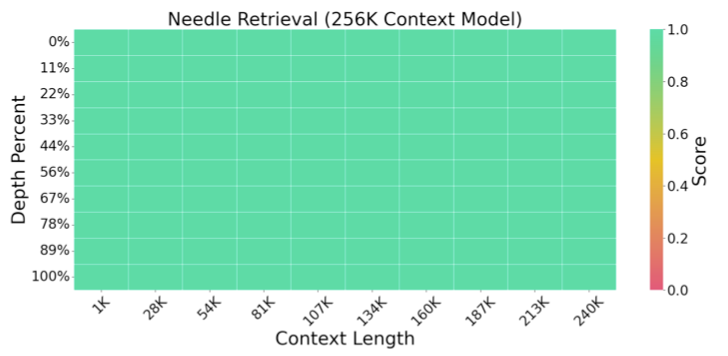
Performing the same test on our LWM-Text model, the score is much better for long-context length for a document depth between 10% and 50%.
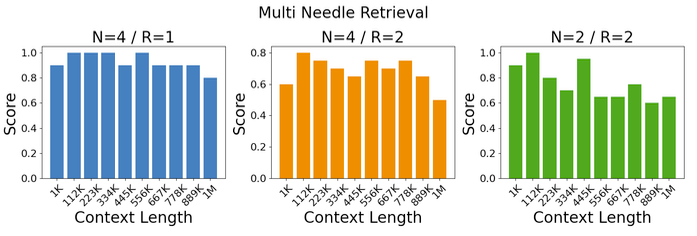
Multi-Needle Retrieval
The performance of the model is examined on more complex variants of the needle retrieval task by mixing in multiple needles, as well as attempting to retrieve a specific subset of them. The model demonstrates strong generalization when retrieving a single needle from multiple needles in context, with slight degradation when tasked to retrieve more than one needle. Furthermore, the model exhibits proficient performance and extends well to longer context lengths of up to 1M tokens. It is observed that there is a degradation in accuracy as the difficulty of the needle retrieval task increases, indicating the potential for further improvement in the 1M context utilization of the model.
Evaluation conclusion
The evaluation spans various language tasks, demonstrating that expanding the context size does not compromise performance on short-context tasks. The results suggest that models with larger context capacities perform well, if not better, across these tasks. This evidence indicates the absence of negative effects from context expansion, highlighting the models’ capability to adapt to different task requirements without losing efficiency in shorter contexts.
Stage II : Vision-Language Training
The second stage aims to effectively joint train on long video and language sequences. In this phase, the capabilities of the previously developed 1M context language model are enhanced by fine-tuning it on vision-language data of various lengths.
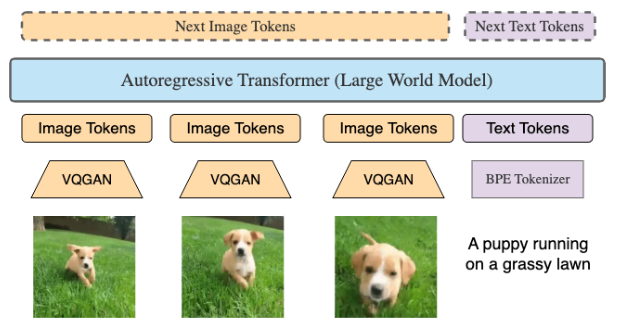
LWM is an autoregressive transformer on sequences of millions-length tokens. Each frame in the video is tokenized with VQGAN into 256 tokens. VQGAN is a GAN architecture used to learn and generate novel images based on previously seen data. These tokens are concatenated with text tokens and fed into transformers to predict the next token auto-regressively. The order of input and output tokens reflects varied training data formats, including image-text, text-image, video, text-video, and purely text formats.
The model is trained in an any-to-any manner using multiple modalities. To differentiate between image and text tokens, and for decoding, video and image tokens are surrounded with special delimiters "<vision>" and "</vision>". Additionally, "<eof>" and "<eov>" vision tokens mark the end of intermediate and final frames in images and videos. For simplicity, these delimiters are not shown.
To enhance image understanding, the "Masked Sequence Packing Ablation" is introduced. The implementation of attention masking and the recalibration of loss weights are pivotal considerations for specific facets of downstream tasks, particularly in the context of image understanding.
The utilization of packing results in a significant decline in accuracy across tasks associated with image understanding. Our hypothesis suggests that this decline may be attributed to the simplistic approach of naive packing, which results in the down-weighting of answers represented by shorter text tokens. This phenomenon assumes significance as the length of text tokens plays a crucial role in achieving optimal performance in benchmark assessments of image understanding.
Training Steps
Commencing from the LWM-Text-1M text model, a similar process of progressive training is executed on a substantial amount of combined text-image and text-video data, as it inherently supports up to 1M context. The training encompasses the following datasets:
1. LWM-1K : Large-scale training occurs on a text-image dataset that merges LAION-2Ben and COYO-700M. These are large-scale image-pair dataset.
2. LWM-Chat-32K/128K/1M : In the final three stages of training, a combined mix of chat data is utilized for each downstream task, including text-image generation, image understanding, text-video generation, and video understanding.
Aligned with the training methodology, a random modality order swap is introduced for each text-video pair, ensuring a comprehensive learning approach.
During the initial two stages of training (LWM-1K and LWM-8K), a strategic choice is made to include 16% of the batch as pure text data from OpenLLaMA . This deliberate inclusion proves beneficial in preserving language capabilities while the model is being trained on vision data.
Long Video Understanding
In the context of vision-language models, ingestion of long videos is commonly achieved through substantial temporal subsampling of video frames, primarily due to limited context length. However, this approach may lead to a loss of finer temporal information critical for accurately addressing questions about the video.
The model is trained on extended sequences of 1M tokens, allowing it to simultaneously attend to thousands of video frames and retrieve detailed information over short time intervals.
Demonstration reveals the model's capability to conduct QA over intricate, long-form videos. Nonetheless, there remains ample scope for enhancing context utilization across all 1M tokens. The generated answers from the model may occasionally lack accuracy, and it may encounter challenges with more intricate questions requiring a deeper understanding of the video content.
It is envisaged that the model will contribute to future endeavors aimed at refining foundational models and establishing benchmarks for understanding long videos comprehensively. Furthermore, in addition to performing image/video captions and QA, the model possesses the capability to generate images and videos from text.
Conclusion
This blog post addresses the formidable challenge of enhancing model comprehension by integrating language and video modalities. Leveraging RingAttention, we undertake scalable training on an extensive dataset comprising lengthy videos and books. Notably, we gradually increase the sequence length from 32K to 1M tokens, maintaining computational manageability.
To effectively train on this diverse dataset encompassing videos, images, and books, we introduce innovations such as masked sequence packing and loss weighting. These advancements play a crucial role in optimizing the learning process.
The research showcases that the model, LWM, boasts a highly effective 1M context size – the most expansive to date. This achievement empowers the model to excel in intricate tasks involving extensive video and language sequences.
This contribution is intended to pave the way for advancing AI models, fostering reliable reasoning, and establishing a grounded understanding of the world, thereby expanding their broader capabilities.